

明治大学総合数理学部 専任教授
菊池 浩明(きくち・ひろあき)
ネットワークセキュリティ研究者。株式会社富士通研究所、東海大学教授などを経て、2013年より現職。2017年より理化学研究所客員研究員を兼任。専門はネットワークセキュリティ、プライバシー保護データマイニング、暗号プロトコル。ビッグデータ活用における「データの匿名化」やプライバシー保護基盤の研究を長年牽引するほか、マルウェア解析からファジィ論理まで学術的貢献を持つ。情報処理学会フェロー。
画面上に表示された、歪んだ文字を入力する。いくつかに分割された交差点の風景画像から、信号機のタイルを選択する。あるいは、「私はロボットではありません」というチェックボックスをクリックする――。
こうしたWebサービスにアクセスしているのが人間なのかボットなのかを判別する技術は「CAPTCHA」と呼ばれます。
2000年代初頭から広く普及したCAPTCHAですが、近年は状況が大きく変わりつつあります。現在のAIを活用すれば、CAPTCHAは高い精度で突破できてしまうからです。
じゃあ、もうCAPTCHAは意味がないのでは? こんな素朴な疑問について尋ねると、ネットワークセキュリティの専門家である明治大学総合数理学部の菊池浩明教授は、首を横に振ります。
「CAPTCHAはそもそも、攻撃を完全に防ぐことを目的とした技術ではないんです」
一体どういうことなのか? 完全防御を至上命題としないCAPTCHAという技術は、なぜ生まれたのか? 今後もCAPTCHAが生き残り続ける理由とは? セキュリティの最前線に立ち続ける菊池さんに、話を聞きました。
AI時代、CAPTCHAの防壁は崩壊?:そもそも昔から破られている
——AIの進化が目覚ましい昨今、CAPTCHAは今、どのような状況にあるのでしょう。AI時代の、新たなアイデアや技術は生まれているのでしょうか?
菊池:実際のところ、最新のAIに対応した真新しいCAPTCHA技術が次々に生まれているような状況ではありません。

——ですが、今もCAPTCHAをさまざまなWebサービスで見かけますよね。あれらは、従来のCAPTCHA技術の域を出ていないということですか?
菊池:そのように捉えています。
——ということは、従来のCAPTCHAでも、最新のAIを使った攻撃を防げている?
菊池:そうですね……。例えば、GoogleのreCAPTCHAでよく見かける「信号機の画像を選んでください」というクイズがありますよね。
あれをいちど「GPT-4o」に解かせてみたのですが、ほぼ100%解けてしまったんですね。
「信号機のタイルは、これ。こっちは道路標識」といった具合に、人間のような推論ができてしまいます。
――えっ。もはやセキュリティとして機能していないのでは……?
菊池:ですが、それでもCAPTCHAは「機能している」と言えます。
——なぜそう言えるのでしょうか?
菊池:CAPTCHAは最初から「攻撃を完全に、100%防止すること」自体を目的とはしていない技術だからです。
いわば、「非常に弱いセキュリティ技術」。それがCAPTCHAなのです。
——どういうことでしょうか。
菊池:まずCAPTCHAがどのような経緯と目的で生み出されたのか、少し歴史を振り返らせてください。
ご存知かと思いますが、CAPTCHAは、ユーザーが「人間か機械か」なのかを判定する技術の総称です。正式名称は「Completely Automated Public Turing Test to Tell Computers and Humans Apart(コンピュータと人間を識別するための完全に自動化された公開チューリングテスト)」。その頭文字を取ったのが、CAPTCHAです。
人間と機械を判別する技術のベース自体は1990年代には存在していましたが、「CAPTCHA」という名前で正式に発表されたのは2003年のことです。暗号理論のトップカンファレンスの一つである「Eurocrypt」で、カーネギーメロン大学の研究グループが提唱しました。
——では、どのような目的から生まれた技術なのですか。
菊池:1990年代後半からインターネットが普及し、ビジネスにおけるWebサイトの重要性が増す一方で、ボットによる不正行為が問題になり始めました。そのカウンターとして、CAPTCHAが登場しました。
CAPTCHAが生まれた背景にある不正行為は、多岐にわたります。
ボットの自動処理による弊害といえば、今では「フェイクニュースの大量投稿による政治的影響」などが問題視されていますが、2000年初頭には、オークションサイトへの攻撃や、アカウントの大量作成といった被害が印象的でした。
例えばオークションなら、ボットが自動で不正に入札を繰り返して値を釣り上げる。あるいDDoS攻撃のように、Webサイトに大勢で一斉アクセスを仕掛けて過負荷にし、サーバーを落とす。もしくは、無料のメールアカウントをボットが自動で大量に取得して迷惑メールの踏み台にする。こうした使われ方も、大きな問題となっていました。
この、ボットによる「物量作戦」を防ぐことが、CAPTCHAの大きな目的でした。
つまり、CAPTCHAの主眼は物量作戦を防ぐことであり、「攻撃を完全に、100%防止すること」ではなかった。
——「完全に防ぐこと自体を目的としていない」というのは、セキュリティ技術としては意外な気がします。
菊池:例えば不正ログインを狙う攻撃の場合、CAPTCHAを破ったところで、その先の「ユーザー認証」においてパスワードが分からなければ結局システムには入れません。ここについては多要素認証など、別の高度なセキュリティ対策が必要でしょう。
そこに至るまでのCAPTCHAという「第1段階」においては、「完全に防げない」ことはそこまで問題ではないかと思います。
CAPTCHAの本質はボットを完全にシャットアウトすることではなく、ある種の「足切り」にあるからです。私はそのように捉えています。
ネットワークセキュリティの世界では、攻撃の性質に応じた多層的な防御を考えます。その中で、ボットによるDDoS攻撃や、オークションの自動入札、あるいは総当たり攻撃のような量やトラフィックを武器にする攻撃に対しては、「最初の関所」でいかに効率よく弾くかが重要になります。
CAPTCHAは、その「最初の関所」なのです。
高度な偽装工作をしていない「カジュアル」なボットを第1段階のフィルターで軽く弾くことができれば、それだけで悪意あるトラフィックは激減します。サーバーの負荷や帯域の圧迫を防ぐのはもちろん、不正な自動入札やスパムアカウントの大量作成といった「物量にモノを言わせた被害」を食い止める効果が得られるのです。
要するに、完璧に守るのではなく「攻撃者にひと手間かけさせて、攻撃のコストを増やし、割に合わなくさせること」に大きな意義がある。
そもそも現在のAIブーム以前から、CAPTCHAは破られ続けています。特に、初期によく見かけた「ボットには読みづらい、グニャグニャに歪んだアルファベット」の画像も、AIの登場を待つまでもなく、従来のOCRや画像処理技術の向上によって、とっくに解読されていました。そのたびに、また新たなCAPTCHAが生まれてきたわけです。
だから、今のセキュリティ学会で「CAPTCHAの突破手法」を発表したとしても、それだけでは学術論文として認められづらい。前提として、ユーザーの正規操作によって解かれるようにつくられているものですし、「破れても、当たり前でしょう」と言われてしまうわけです。

フィッシングサイトが自分でCAPTCHAを設置しはじめた?
――しかし、そんな「弱い技術」であるCAPTCHAが、世界中に広まったのはなぜでしょうか?
菊池:最大の要因は、システムを導入するWebサイト側や実際に利用するユーザーにとって、非常に「優しい」技術だからだと考えています。
通常、システムが相手を「正しいユーザーである」と認識するための高度な認証技術を導入しようとすれば、複雑な暗号プロトコルを実装する必要があります。例えば公開鍵暗号方式を用いたり、各ユーザーにパスワードや生体情報などの「秘密情報」を登録・管理させたりしなければなりません。マイナンバーカードのように、厳密なKYC(本人確認手続き)が必要になるケースもあります。
さらに、それらを処理するためにサーバー側にも強固なセキュリティ基盤や、GPUなどの強力な計算リソースが要求されます。
しかし、CAPTCHAの目的は「個人の特定」ではなく、単なる「人間か機械かの判別」です。システム側が問うのはその二択だけなので、ユーザーに対して事前の登録手続きや、秘密情報の入力を求める必要がありません。
特別なハードウェアも不要で、手軽にボット対策を実装できる。これが、「優しい」といえる理由です。
特にGoogleのreCAPTCHAは、わずか数行のスクリプトを自社のWebサイトに埋め込むだけで動作します。しかも、Googleは一定のリクエスト件数まではこれを無償で提供している。Googleにとっては「自社のボット防止技術が広く使われ、インターネット全体の安全性に貢献している」とアピールできるメリットがあるのでしょうけれど。こうした強力なプラットフォーマーによる手軽な提供があったことも、CAPTCHAがここまで爆発的に広まった背景にあります。
―—導入の手軽さが、世界的な普及の裏にあったわけですね。
菊池:一方で最近、CAPTCHAが「皮肉」な使われ方をしている例もあります。
フィッシング詐欺のサイトが、自分たちの入り口にCAPTCHAを設置し始めるケースです。
——なぜ?
菊池:セキュリティ企業や研究機関は、AIなどを活用した自動巡回ボットを使って、ネット上のフィッシングサイトを検知しています。その「取り締まりボット」に見つからないよう、身を守るための隠れ蓑として攻撃者がCAPTCHAを利用することがあるのです。
それに対して今度は、セキュリティ研究者たちが「フィッシングサイトを見つけ出すためにCAPTCHAを破る手法」を研究するという流れも出ています。
――防御の目をかいくぐるためにむしろCAPTCHAを使うとは、一見、不思議な流れにも思えますね。それでは、近ごろの研究動向についてはいかがでしょうか。例えば「絶対に破られない完璧なCAPTCHAをつくろう」という動きは出てきていないのでしょうか。
菊池:「破られる前提の足切り技術」として割り切られている以上、「どうすれば完璧なCAPTCHAがつくれるか」という大真面目な研究は、今のセキュリティ学会ではあまり行われていません。
高度な防御が求められるのは、ユーザー認証技術の領域の方です。ただ今はむしろ、この「ユーザー認証技術」がAIに突破されてしまう事態が、喫緊の課題です。システムの根幹を揺るがす脅威が他に山積みのため、CAPTCHAの研究よりは、認証技術をめぐる研究にフォーカスが当たっているのが現状かと思います。
「弱くても多様であること」がAI時代にもCAPTCHAを生き残らせる
——では今後、AIがさらに高度化していく中で、CAPTCHAはどのような姿になっていくのでしょうか。
菊池:今の仕組みを無理に刷新するのではなく、現状の延長線上で対策を続けていく形になるのではないでしょうか。

――具体的にどういうことでしょうか?
菊池:たとえ個々は既存の古い技術であったとしても、世の中のWebサイトに「多様な種類」のCAPTCHAが混在して導入されていること自体が、攻撃者にとっては大きな負担になるんです。
攻撃側からすれば、突破用のボットをつくるにしても、それぞれのクイズ形式やアルゴリズムに合わせてAIに学習させたり、専用のプログラムを準備したりしなければなりません。
たとえば、GoogleのreCAPTCHA v2でよく見かける、「チェックボックス」式。これは、ユーザーのマウス操作などに非人間的な動きがないかを分析していると思われます。あるいは「指定されたタイル画像を選ぶ」方式。さらには「音声を聞き取って入力するタイプ」や「パズルのピースをスワイプしてはめるタイプ」などもありますよね。
最近ではさらに進化して、ユーザーにクイズなどの操作を一切させず、機械学習を用いてページ内での行動から自動的にボットか人間かを判定する「インビジブル」な仕組みも出てきています。
こうした多様な形式が世の中に散らばっていて、時には複合的に出てくるという状況があるだけで、攻撃者からすると対応の手間が跳ね上がるわけです。
――CAPTCHAがあることで、攻撃者は「多様なパズルやボット判定に対応できる最新AI」を用意し、それぞれの形式を学習させ、大量の画像認識や推論の計算処理を回さなければならなくなる、ということですね。
菊池:はい。「AIで解ける」とは言っても、「AIの運用そのものがコスト」というわけです。
それはカジュアルな攻撃者からすれば、大量攻撃を諦め得る程度には、大きなコストです。
AIがどれほど進化しようとも、しばらくの間、「多様性で攻撃者のコストを上げる」という根本的な構図は変わらないはずです。2000年代初頭に普及した、あの「歪んだ文字を入力させる」タイプのCAPTCHAが今も時おり使われているのには、そうした理由もあると考えられます。
――種類が豊富であること自体が、防衛力になっているのですね。
菊池:それにもし多様性が失われて、世の中のCAPTCHAが例えば「チェックボックスにチェックを入れるタイプ」一択になってしまったら、まずいことになります。
いくら優れた判定技術でも、世界中のCAPTCHAが何かひとつの手法に統一されてしまえば、攻撃者はそこにだけ資金とリソースを集中投下して、専用の突破ツールをつくればよくなってしまいますよね。そうなれば、あっという間にすべてのサイトが危険に晒されてしまいます。
だからこそ、個々のセキュリティレベルはさほど高くなくても、多様なCAPTCHAが揃っている状態を維持すること。それ自体が、インターネット全体の防御として機能し続けるのです。
——「全部あの簡単なチェックボックスだけになればいいのに」と思ってしまうこともありますが、言われてみれば確かにその通りですね。
菊池:ええ。そこで重要になってくるのが、防御側がいかに「コスパ良く、多様なパズルをつくれるか」という点です。
例えば、「3D画像を用いたCAPTCHA」というものがありました。画面上に傾いた動物の3Dモデル(例えば犬)が表示されていて、それをスワイプして「正しい足元(地面)の向き」に回転させる、といった課題を出すタイプです。
システム側からすると、3D画像の角度のパラメータをランダムに変えるだけで、無限に新しい問題をつくれます。一方で攻撃するAI側からすると、単なる2次元の平面画像を認識するのとは違い、「この物体が3次元空間でどういう立体構造をしていて、どちらが上なのか」を推論しなければならないため、要求される処理のフェーズが一段上がります。
劇的に革新的な技術が生まれなくても、多様性を確保して攻撃者の裏をかくために、こうした「つくる側にとっては簡単で、解く側は計算量が必要な手法」の模索は続いていくでしょう。
――そのコスパの差がひとつ、重要なテーマである、と。
菊池:半面、もうひとつ意識しなければならないのは、人間にとっての「ユーザビリティ」とのトレードオフです。
極端な話、歪んだ文字列を「100文字」入力させるようにすれば、AIでも破るのが難しくなります。しかし、そんな面倒なことをさせれば、本来の人間も嫌がって誰もそのサイトを使ってくれなくなりますよね。
例えば「5秒もあれば、60%の精度で解かれてしまう」CAPTCHA手法があるとします。それを防ごうとして、「AIが80%の精度で破るのに1時間かかる」複雑な演算を要求する仕組みを導入したとします。
これだと確かに防御力は上がりますが、今度は正規の一般ユーザーまで認証に何分も待たされることになってしまう。Webサービスとしては致命的ですし、それでは本末転倒です。
——「つくる側にとっては低コストで、人間のユーザーにとっても簡単。でも、ロボットが解くにはコストがかかる」という絶妙なバランスが必要なのですね。
菊池:まさにその「数で攻めてくるカジュアルなアタッカーに対し、コストパフォーマンス良く対抗する」というのが、CAPTCHAの真髄だと考えます。
あの古い「歪んだ文字」を読み取って正しく入力させるCAPTCHAも、システム側からすれば「既存の辞書データから適当な単語を拾ってきて、画像処理で少し歪ませるだけ」なので、問題をつくるコストが極めて低く済むのです。
こうした「つくる側のコスパの良さ」と、ユーザーが数十秒もかけずに直感的に解けるという手軽さのバランスが優れていたからこそ、この技術は20年以上も生き残ってきたのだと思います。

——ちなみに菊池さんご自身も、「多様性」を担保する一環として、新しいCAPTCHAの手法を研究したことはありますか?
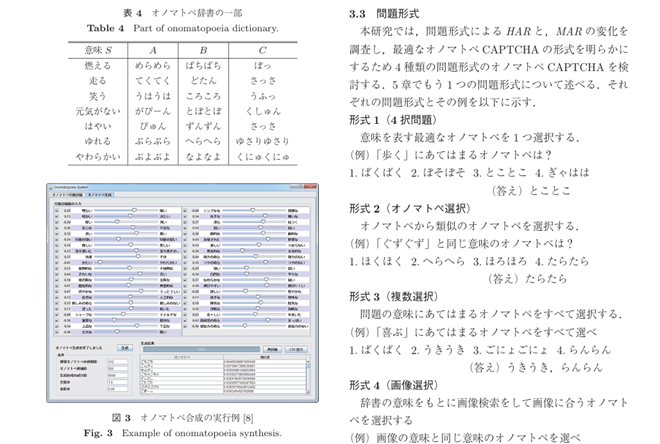
菊池:関わったものが、いくつかあります。例えば、2010年代に私の研究室の学生が提案した「オノマトペCAPTCHA」という手法。
これは、「日本語特有の擬音語・擬態語のニュアンスは、言語の壁があり機械翻訳でも文脈を捉えづらいのではないか」という仮説を利用したものです。例えば、「歩く」動作に当てはまる言葉として「トコトコ」「パクパク」「ボソボソ」の中から選ばせたり、「グズグズ」と同義のものを「タラタラ」「ホクホク」などから選ばせる、といった具合です。
当時の実験では、日本語のネイティブ話者以外には正答が難しく、独自の防壁として機能する可能性が示されました。
実は今回の取材を受けるにあたって、GPT-5にこのオノマトペ問題を解かせてみました。結果は「100点満点」でした。言語の壁も文脈のニュアンスも、AIは完璧に理解して突破できるわけですね。
――やはり現代のAIの進化は凄まじいですね。
菊池:おっしゃる通りです。
そんな時代の中、どこまでいってもCAPTCHAは「弱いセキュリティ技術」に過ぎないかもしれません。しかし、システムへ導入しやすく、ユーザーの利便性を損なわず、それでいて攻撃者の手間とコストを確実に引き上げるという、その絶妙なバランスが最大の強み。
AIがどれほど高度化していっても、CAPTCHAは「攻撃者を嫌がらせる最初の関所」として、なんだかんだで形を変えながらも生き残り続けていくのだと思います。

取材・執筆:鷲尾 諒太郎
編集:田村 今人
撮影:赤松 洋太


