![]()
![]()
動画内の“顔だけ”を後からくっきり高画質に補正するAI技術 シンガポールの研究者らが開発【研究紹介】
2022年11月21日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
シンガポールのNanyang Technological Universityに所属する研究者らが発表した論文「Towards Robust Blind Face Restoration with Codebook Lookup TransFormer」は、低画質な画像や動画内の顔を高画質に補正する深層学習技術を提案した研究報告だ。昔に撮影したノイズの多い写真や映像の顔だけを高品質に修復し、コンテンツ全体の質を向上させる。

研究課題
人は写真や映像内の顔を見てしまう傾向があるため、低画質な画像や動画でも、顔だけを綺麗にしてやれば低コストで総合的な見栄えが良くなる。

低画質な画像や動画を高画質に変換する技術は昔から探究されており、特に深層学習の登場によりその精度は大幅に向上した。だが、巨大な画像空間において、追加のガイダンスなしに学習することは依然として困難であり、先行研究のアプローチでは最適とは言えない復元品質であった。
出力品質を向上させるためには、低画質-高画質マッピングの不確実性を低減し、詳細を補完する補助情報が不可欠である。改善するため様々な手法が試されているが、どのアプローチも劣化に対する高い感度や限られた事前表現に悩まされており、出力は非常にリアルであるにもかかわらず、入力画像の劣化が激しい場合には正確なベクトルを求めることが難しく忠実度の低い結果となる。
研究過程
今回はこの課題に挑戦するために、これまでのアプローチとは異なるTransformerベースのネットワーク「CodeFormer」を提案する。このネットワークは低画質な画像から高画質な画像に復元するためのモデルで、非常に高い忠実度かつ高品質な出力結果を達成する。
ネットワークは、2段階のフレームワークで構成される。1段階目はself-reconstructionというもので、高画質な画像をエンコーダーに入力してデータ情報を落とし、画像の各セルの特徴量を抽出、離散化してコードブック(Codebook)と呼ぶ空間にマッピングする。そして、デコーダーで元の画像に戻すことを学習する。1段階目でマッピングしたコードブックは2段階目で利用する。
2段階目では、低画質な画像をエンコーダーに入力して画像の特徴量を抽出し、1段階目で学習したコードブックにマッピングするためにTransformerを活用してデコーターで高画質化する。途中、制御可能な特徴変換モジュールを用いて、エンコーダーからデコーダーへの情報フローを制御しており、これにより復元品質と忠実度の間の柔軟なトレードオフが可能となり、両者の間の連続的な画像遷移を実現している。
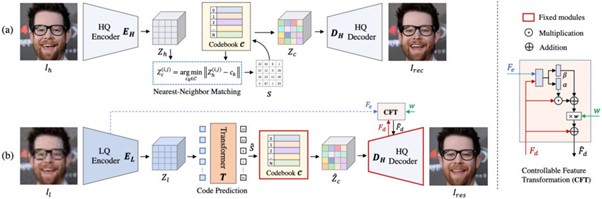
CodeFormerは、低画質な画像をより小さな空間(コードブック)にマッピングすることで、低画質-高画質マッピングの不確実性を大幅に減少し、多様な劣化に対する頑健性が促進された。実験においても、先行研究に比べて復元の品質と忠実度の両方の向上が確認され、精度の高さが示された。
Source and Image Credits: Zhou, Shangchen, et al. “Towards robust blind face restoration with codebook lookup transformer.” arXiv preprint arXiv:2206.11253 (2022).Source and Image Credits: Zhou, Shangchen, et al. “Towards robust blind face restoration with codebook lookup transformer.” arXiv preprint arXiv:2206.11253 (2022).
関連記事

「他人の“顔”で動画配信」——リアルフェイスマスクを映像内の動く自分に滑らかに適合できる技術 ディズニーなどが開発【研究紹介】

動画撮影中の動く顔を「スマートフォンだけ」でアニメ似顔絵風にその場で変える技術【研究紹介】

「テレポート会議」ができるレベル 全身の動きを忠実に真似する実写アバターを米Metaが開発【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


