![]()
![]()
「他人の“顔”で動画配信」——リアルフェイスマスクを映像内の動く自分に滑らかに適合できる技術 ディズニーなどが開発【研究紹介】
2022年10月21日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
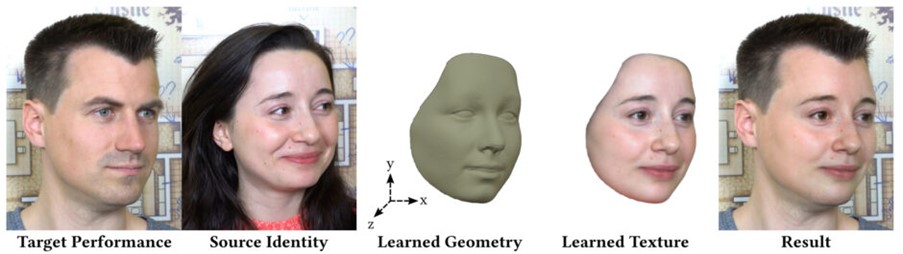
スイスのDisney Research StudiosとETH Zürichによる研究チームが発表した論文「Learning Dynamic 3D Geometry and Texture for Video Face Swapping」は、映像内の自分の顔を他の人の顔に入れ替える学習ベースのアプローチを提案した研究報告だ。髪の毛や耳、肌の色、照明、表情、頭部の動きなどを考慮して、動作によって発生するアーティファクトを抑えた自然で違和感のない合成顔を生成する。
研究背景
このように顔を入れ替える手法を「Face swapping」(フェイススワッピング)と呼び、映画制作などにおいて需要が高まっている。一般的なアプローチは、驚くほどのクオリティを実現できる一方で、現場での大掛かりなセッティング、大量のカメラやセンサーが搭載したライトステージのキャプチャー、詳細な3Dモデリングなど、非常にコストの高い作業を必要とする場合が多い。
一方、深層学習を用いたフェイススワッピング技術の最近の進歩は、特定のシナリオで顕著な結果を示しており、従来のアプローチに必要な時間の何分の一かの時間で魅力的な効果を生み出している。映像内の人物の顔(ターゲットの顔)を違う人物の顔(ソースの顔)に入れ替える技術である。
学習モデルのフェイススワッピング技術の発展は非常に有望であるが、学習データに特定のポーズや表情がない場合、生成される顔の質はかなり低下する。2Dアプローチだと、新しい視点の生成が難しく頭部の動きに対応するのが困難である。また顔の形状を考慮した3Dアプローチでも、事前に学習された顔の事前分布に依存しており、顔の幾何学的特徴にうまく適応できていない。
研究内容
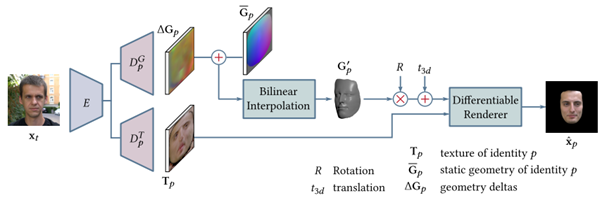
今回はこれら課題を克服するために、顔のテクスチャと形状の更新を同時に学習することで、3次元情報を利用した新しいフェイススワッピング・パイプラインを提案する。
このパイプラインのオートエンコーダはアイデンティティ間で共有され、表情や照明条件などの特定の特徴を共同で表現することを可能にする。2つの独立したデコーダを持ち、テクスチャ用と3D形状用の2つのラインで構成される。
このアプローチの特徴は、デコーダが入力された画像を動的な顔テクスチャと変形可能な3次元顔形状からなる3次元表現に変換することである。テクスチャと同様に、3次元形状をXYZ画像グリッドとしてUV空間にエンコードすることで、顔の3次元メッシュ全体を捉え、オートエンコーダが畳み込み処理を行うことを可能にする。最後に、微分可能なレンダラーを用いて、ターゲットの顔と同じ姿勢で入力画像平面に投影しブレンドする。
研究評価
このように学習した3次元形状とテクスチャを利用することで、詳細な形状と高品質なテクスチャを持つ合成顔を提供することができる。

性能を評価するための実験でも、2次元で動作する他の手法と比較して、より高品質な顔の入れ替えを示した。さらに、形状やテクスチャ、照明の変更ができるため、ユーザーが合成結果をより自由なコントロールを可能にする。また従来の単眼顔認識のアプローチと比較して、形状推定が向上することも実証した。
Source and Image Credits: C. Otto, J. Naruniec, L. Helminger, T. Etterlin, G. Mignone, P. Chandran, G. Zoss, C. Schroers, M. Gross, P. Gotardo, D. Bradley, and R. Weber. Learning Dynamic 3D Geometry and Texture for Video Face Swapping
関連記事

顔のみをアニメ風にして動画配信。動く人の顔を高品質に漫画化するスタイル転送技術「VToonify」【研究紹介】

青と黄を混ぜると「きちんと」緑色になるお絵かきデジタルツール 油絵や水彩画などのデジタル再現に活用【研究紹介】

たった1枚の画像からシャープな3Dモデルを自動生成 Google「3DiM」開発【研究開発】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


