

ITジャーナリスト
牧野 武文(まきの たけふみ)
生活とテクノロジー、ビジネスの関係を考えるITジャーナリスト、中国テックウォッチャー。著書に「Googleの正体」(マイコミ新書)、「任天堂ノスタルジー・横井軍平とその時代」(角川新書)など。
@takemakino
世界のZ世代の心を鷲掴みしたショートムービープラットフォーム『TikTok』(ティックトック)。日本国内の月間アクティブユーザー数(MAU)は950万人程度だと言われている。Twitterの4500万人やLINEの8600万人と比較してはまだ一部の人に楽しまれている状況だ。
一方、開発元の中国発IT企業「バイトダンス」がリリースしている中国版『TikTok』の『抖音(ドウイン)』は、2022年中国の国内MAU6.9億人を記録した。中国全体のネットユーザーは8.54億人と言われているなかで、実に80%以上の人が最低でも月に1回はドウインを利用していることになる。もはや国民的アプリになっている。
その人気の秘密は、ショートムービーを見る楽しみだけでなく、撮ることが楽しくなる機能を最大限に提供をしているからだ。備え付けのフィルターを使えば、理想の容姿に変えられたり、かわいい小動物に変身できたりなど、誰でも簡単に楽しめる。ドウインはご存知のとおり、主にタブレットで使用されるアプリだ。この自由自在なクリエイティブをGPUも搭載していない非力なスマートフォンで実現するには、バイトダンスの高い画像処理技術力だ。本稿は、被写体の顔にフィルターを精確に被せるために駆使されている「顔検出技術」と「3D顔メッシュモデル」を紹介する。
Viola-Jones法と顔検出技術
ドウインは、その高い技術力を活かして、数々の機能を非常に短いサイクルでリリースしている。常に新しい驚きをユーザーに提供することで、新しいユーザーを惹きつけつつ、既存ユーザーの離脱率を低く抑えている。
ドウインの人気の理由の一つである美顔特殊効果を実現するには、リアルタイムに以下のステップを完成させなければならない。
- 動画の中から顔部分を検出する
- 特徴点(ランドマーク)を推定し、3D顔メッシュモデルを生成する
- メッシュモデルを統計結果をもとに算出した「美しい顔」に変形する。
- 変形したメッシュモデルに合わせて、映像を変形させる。
顔検出アルゴリズムの決定版ーーViola-Jones法
昨今の顔検出技術は、もはや安価なデジタルカメラや無料のカメラアプリにも搭載され、ありふれた技術となっている。現在主流で使われている顔検出の手法は、Paul ViolaとMichael Jonesが2001年に提案した「Viola-Jones法」に基づいている。
Viola-Jones法の考え方は王道だ。あらかじめ顔の写真を大量に集めて解析し、特徴量の統計分布を測定しておく。すると、顔画像がどのような特徴量を持っているのかがわかる。次に、ターゲットの写真の特徴量を測定して、顔の特徴量の統計と似通っている部分を顔と判断をする。画像の特徴を解析するには「Haar-like特徴量」ーー「垂直エッジ」・「水平エッジ」、「垂直線分」・「水平線分」、「矩形の頂点」がどこにあるのかを左上から右下に走査をしていく。
最初は最小単位である2×2ドット構成の「Haar-like特徴量」を調べていき、次は4×4ドットに拡大し、次は8×8ドットとサイズを大きくしていく。これにより、細かい特徴から大きな特徴まで検出できることになる。この特徴量を抽出する時に、画像のどの場所に特徴量が抽出できたのかを知るために、畳み込み演算をしていく。
 ▲顔検出に使われる「Haar-like特徴量」。このようなカーネル(フィルター)を使って畳み込み演算を行い、画像の特徴を解析する。
▲顔検出に使われる「Haar-like特徴量」。このようなカーネル(フィルター)を使って畳み込み演算を行い、画像の特徴を解析する。
文字だけだと理解が難しいので、簡単な図形で畳み込み演算を図解してみよう。下図のような縦長の四角形と横長の四角形がある図形から畳み込み演算によって特徴量を抽出してみる。抽出する特徴量は、垂直方向のエッジだ。
図の左上の2×2領域の4ドットと、特徴量の4ドットを掛け算し、その結果を結果欄の左上に書き込む。次は、適用する場所を右に1ドットずらし、同じ計算をし計算結果を書き込む。こうして右端まで行ったら、下に一段ずらし、同じ計算を行い、右下まで走査をしたら終了となる。

このような演算は、2×2の画像の情報を、風呂敷を畳むように1ドットに収めることから畳み込み演算と呼ばれる。英語では「Convolution」ーー「巻き込む」といった意味で、バラの花びらが螺旋状に撒かれている様子などを表す言葉だ。
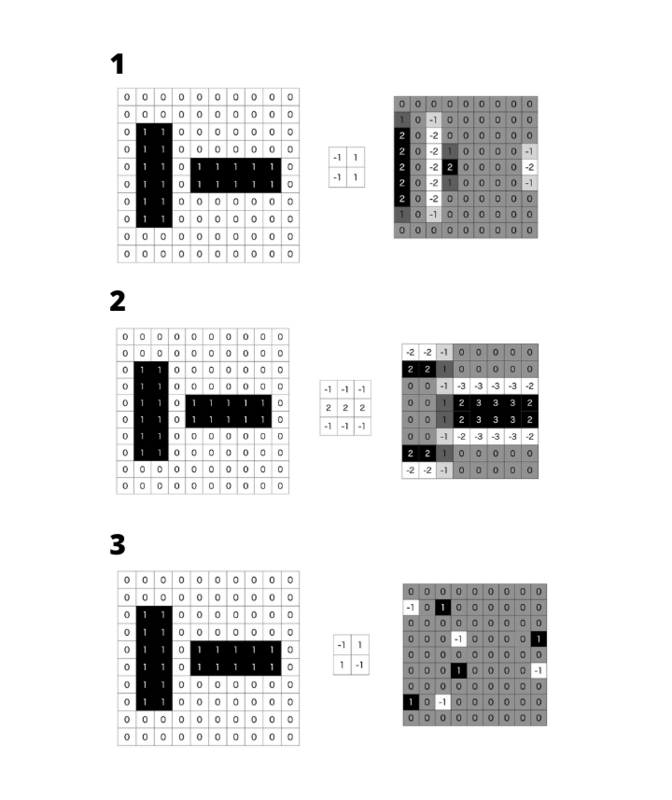 ▲畳み込み演算の図解。カーネルは垂直エッジ検出。演算結果を見ると、垂直エッジのある場所がわかる。カーネルを「水平線分検出」「矩形頂点検出」に変えることで、さまざまな図形の特徴を抽出することができる。
▲畳み込み演算の図解。カーネルは垂直エッジ検出。演算結果を見ると、垂直エッジのある場所がわかる。カーネルを「水平線分検出」「矩形頂点検出」に変えることで、さまざまな図形の特徴を抽出することができる。
顔の場合頬骨の部分は明るく、目の部分は暗い。同様に鼻筋の部分は明るく、その左右は影ができて暗くなる。あらかじめ、顔写真を大量に用意し、さまざまな種類、サイズのカーネルを適用して、どのような特徴量が強く現れるかを調べる。サンプル画像の特徴量分布が近い場合に、顔があると判断をする。
ただし、これはあくまでも顔検出の原理であり、この手法を正直に適用すると、計算量が膨大になってとてもリアルタイムでの顔検出などできない。そこで、ビオラとジョーンズは、いかに計算量を減らして、素早く顔検出をするかについても研究をし、そこまで含めてビオラ・ジョーンズのアルゴリズムとして提案をしている。それがどういうものであるかは、2人の論文「Rapid Object Detection using a Boosted Cascade of Simple Features」をお読みいただきたい。
ちなみに、この顔検出アルゴリズムを多層化したものが、のちの画像検出技術に発展していく。畳み込み演算を何度も繰り返し行うディープラーニングモデルは、CNN(Convolutional Neural Network)と呼ばれる。カーネルにより特徴を抽出し、さらにそこから特徴の特徴を抽出していき、何段重ねにも特徴抽出をすることで、画像の特徴を学習していく。Viola-Jones法のアルゴリズムでは、特徴量の統計を用いて、その画像が顔であるかどうかを判定していたが、CNNでは、大量の顔の画像を読み込ませてニューラルネットワークの重みづけを調整することで学習をしていく。
画像から顔を検出したら、顔の3Dメッシュモデルを生成する。これは、目尻、鼻の頂点、口角など、顔の中で特徴点(=ランドマーク)を特定し、それを直線で結んだものだ。多面体で構成される3Dモデルになる。
 ▲グーグルが提供しているfacemeshのデモ映像。抖音でも同様の3D顔メッシュモデルを生成することで、さまざまな特殊効果を実現している。Google Developersブログ「MediaPipeとTensorFlow.jsを使ってブラウザで顔と手をトラッキングする(https://developers-jp.googleblog.com/2020/04/mediapipe-tensorflowjs.html)」より引用。
▲グーグルが提供しているfacemeshのデモ映像。抖音でも同様の3D顔メッシュモデルを生成することで、さまざまな特殊効果を実現している。Google Developersブログ「MediaPipeとTensorFlow.jsを使ってブラウザで顔と手をトラッキングする(https://developers-jp.googleblog.com/2020/04/mediapipe-tensorflowjs.html)」より引用。
顔に分布するランドマークが多ければ、より精密な顔メッシュモデルが構築できるが、その分計算量は多くなる。首を軸に顔を左に回転させると、顔の左半分のランドマーク間の距離は動きによって変化する。その距離のズレから顔の凹凸が推定でき、3Dの顔メッシュモデルが生成できる。一般に顔認証に使われるランドマークは70個前後と言われるが、ドウインの場合は1セッションに107個のランドマークを使用しているという。
この仕組みを利用したドウインの実例をみてみよう。次のショートムービーは「牛乳フェイスパック」という名の特殊効果を利用したものである。フィルターをオンにすると、自分の顔に泡立てたミルクが塗られたようになる。動画を見ればわかるように、話す際の口角の細かい動きにもきれいに追従するものだ。さらに、ショートムービーの後半部分で、自撮りをしている女性が自分の左目と唇を手で覆っても、崩れることなく効果は維持している。それだけ精密にメッシュモデルがつくられているということがわかる。
 ▲ドウインの特殊効果「牛乳フェイスパック」
▲ドウインの特殊効果「牛乳フェイスパック」
もうひとつご紹介したいのが、京劇に出てくるキャラクターになりきることができる特殊効果だ。頭のかぶりものと化粧はCG合成だ。顔の動きにきちんと追従し、さらに頭の上の飾りや耳横の飾りの揺れ具合にも注目していただきたい。顔の傾きなどに応じて、きちんと物理計算されているため揺れ方がきわめて自然だ。
建築物にCG効果を合成する「ランドマークAR」
検出できるのは何も顔だけとは限らない。例えば自動車の物体検出を行いたければ、あらかじめ自動車の画像を使って、特徴量の統計を取っておけば顔と同じように検出することができる。さらに、ランドマークを設定して、メッシュモデルを生成すれば、そこにきれいにCGを合成できる。
その手法を使ったのが「ランドマークAR」と呼ばれる効果だ。抖音アプリから指定されたランドマーク建築物を撮影すると、物体検出されて、CGが合成され、建築物があり得ない変化をしたように見える。イベントや観光の集客ツールとしても活用されている。
 ▲西安市の鐘楼を抖音で撮影すると、鐘楼が変化をして鳳凰が中から飛び出てくる。観光やイベントの集客キャンペーンとして、中国各地のランドマーク建築物で同様の効果が公開されている。
▲西安市の鐘楼を抖音で撮影すると、鐘楼が変化をして鳳凰が中から飛び出てくる。観光やイベントの集客キャンペーンとして、中国各地のランドマーク建築物で同様の効果が公開されている。
顔検出から画像生成AIへ
ドウインは、あくまでも暇つぶしのためのアプリと思われているかもしれない。ただそれでも、開発チームは技術追求に少しも手抜きをしていない。これが、クリエイティブの質の高さに繋がり、利用者の心をとらえるポイントとなり、6.9億人のMAUという結果に結びついている。
2017年、バイトダンスは初めて自分の顔の上にアニメの犬の顔を載せることができる特殊効果をドウインに実装した。自分が瞬きをすると、犬も瞬きをする。単純な特殊効果だが、これが面白いと評判になり、ドウインの利用者数や利用時間が大幅に伸びるキラー機能になった。ここからバイトダンスは、画像生成系のAIの研究開発を始め、今では自分の顔の年齢を変えたり、写真の顔を動かすなど、AIテクノロジーを使ったさまざまな特殊効果が搭載されている。それを支えているのが、高いAI技術力とクリエイティブ力だ。バイトダンスは、子どもの頃のSFアニメで見た魔法のカメラを現実のものにした。


