![]()
![]()
映像のみから動けるリアル3Dアバターを作成 服の動きまで精密に再現【研究紹介】
2022年3月11日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
ドイツのMax Planck Institute for Intelligentの研究チームが開発した「ICON: Implicit Clothed humans Obtained from Normals」は、1枚のRGB画像から服を着た詳細な3次元モデルを再構成し、これに基づいて、ビデオフレームから直接パーソナライズされたポーズと衣服の変形を持つ、完全にテクスチャ化されたアニメーション可能なアバターを作成する手法だ。

関連記事:YouTubeなど動画内の人を3Dモデルで抜き取る技術 米ワシントン大とGoogle Researchが「HumanNeRF」開発【研究紹介】
先行研究
リアルな3Dアバターを作成する場合、高価なスキャン装置を必要とするため、近年では1枚の画像から衣服を着た3Dモデルを再構築する方法がいくつか報告されている。また3Dスキャンからアニメーション可能なアバターの生成も報告されている。しかし、体の一部や衣服、髪などのディテールが壊れたり欠けたりとアーティファクトが目立つのが現状だ。
これはポーズ、形状、衣服のバリエーションが非常に限られたデータセットでトレーニングされているため、フレーム外の見えないポーズや極端なポーズにうまく対応できないことが一因しているという。本研究ではこのようなアーティファクトを軽減して高品質に出力するフレームワークを提案する。

実証実験
このフレームワークは、ビデオフレームの画像集合が与えられると、各2次元画像のみから詳細な3次元モデルを推定し、それらを組み合わせてアニメーション可能なアバターを作成する。
具体的には、服を着た人間のRGB画像と、その画像から推定された3D人体モデルのSMPLを入力し、2つの主要モジュールで処理する。1つ目のモジュールでは詳細な衣服を着た人の表面法線(正面と背面図)を予測し、2つ目のモジュールでは人間の占有領域の等値面を生成する。法線とメッシュをフィードバックループで繰り返し改良してピクセルレベルの不整合を減らす。これらによって得られた多様なポーズをとった被写体のフレームから、SCANimateを用い、アニメーション可能な3Dアバターを生成する。
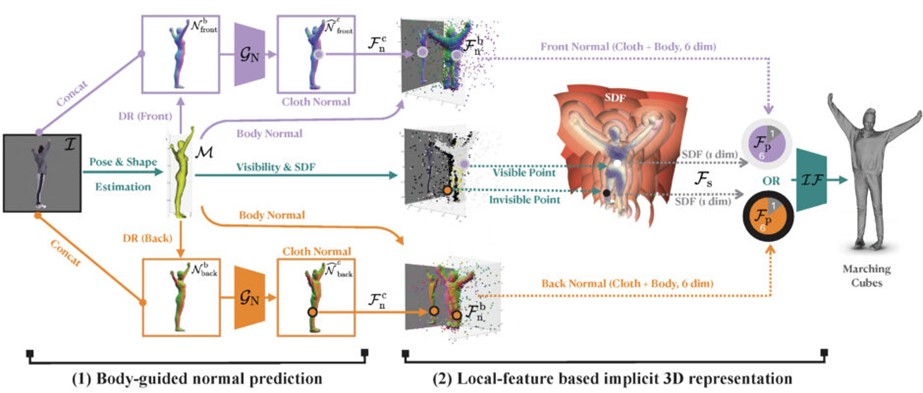
実験結果
今回の手法をAGORAとCAPEというデータセットと、実際の画像で定量的、定性的に評価した結果、学習データが大幅に制限されている場合でも、微調整や後処理を必要とせず、再構成において最先端の技術を凌駕した。また高い汎化に優位性があることがわかった。
Source and Image Credits: Xiu, Yuliang, Jinlong Yang, Dimitrios Tzionas, and Michael J. Black. “ICON: Implicit Clothed humans Obtained from Normals.” Computer Vision and Pattern Recognition (CVPR) 2022.
関連記事

サンフランシスコの街を画像からリアルに3D化 Waymoなど「Block-NeRF」開発【研究開発】

YouTubeなど動画内の人を3Dモデルで抜き取る技術 米ワシントン大とGoogle Researchが「HumanNeRF」開発【研究紹介】

VRヘッドセットの脆弱性を指摘 装着者の顔の動きから個人情報を抜き取るシステムを開発【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


