![]()
![]()
映像内で動く人や背景を好きなように置き換えられる技術「DynVideo-E」。シンガポールの研究者らが開発【研究紹介】
2023年10月24日

先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
シンガポール国立大学に所属する研究者らが発表した論文「DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing」は、映像内で動く人や背景を好きなキャラクターや背景スタイルに変換できる技術を提案する研究報告である。映像が再生されても変換は維持され、一貫した映像を表現される。

研究背景
強力な画像拡散モデルの顕著な成功は、ビデオ編集への適用における関心を増大させた。しかしながら、ビデオ編集の際に時間的一貫性を高く維持することは顕著な課題となっている。この問題を解決するため、既存の拡散ベースのビデオ編集アプローチは、ソースビデオからのさまざまな対応関係を抽出し、フレーム毎の編集プロセスに組み込むように進化した。
これには、アテンションマップ、空間マップ、光学フローなどが利用されている。これらの手法は編集結果の時間的一貫性の強化を示しているものの、長時間の一貫性とフレームごとの編集との間の固有の矛盾のため、動きや視点の変化が少ない短いビデオに制限されている。
最近の研究において、「Dynamic NeRF」という技術は、3Dの人間を中心とした基準空間と、人間の姿勢に基づく変形フィールド(画像や3Dモデルの一部を別の位置や形に変更するためのベクトル情報を持つフィールド)を使って、大きな変形や視点変化を持つビデオをうまく再現できることが示されている。
研究概要
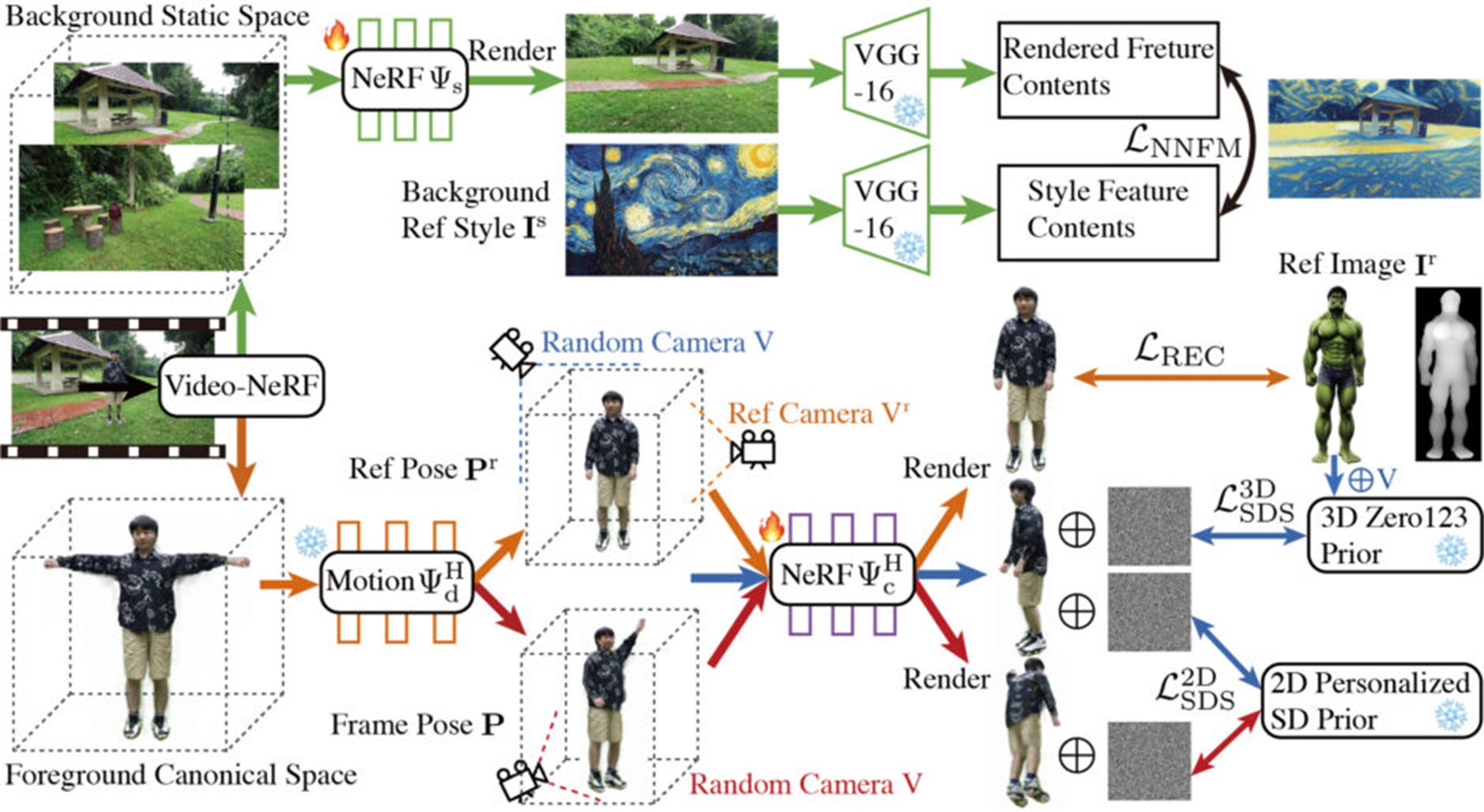
本研究では、このDynamic NeRFをビデオの表現手段として取り入れた、人間中心のビデオ編集を対象とする手法「DynVideo-E」を提案する。この手法の核となる考え方は、ビデオ編集の課題を3D空間での編集へと変換することである。
DynVideo-Eは、元のビデオ中の人物を「前景の3D人間空間」として捉え、この空間は変形フィールドと関連付けられる。また、ビデオの背景は「3D背景の静的空間」として独立にモデル化される。
編集の際、目標となる特定の人物(例えば、変換希望のキャラクター)の画像が提供されると、この画像をベースに、3D人間空間が編集される。この編集は、異なる視点や姿勢のもとで、再構築損失、2D/3Dの拡散事前情報、部分的な超解像技術を活用して実行される。
さらに、参考となる背景画像のスタイルを3D背景モデルに適用するため、特徴空間におけるスタイル転送損失が採用される。これにより、背景が参考画像のスタイルや雰囲気に変更される。
編集内容は、変形フィールドを介してビデオ全体に適用される。その上で、元のビデオのカメラ位置や角度を基にレンダリングが行われ、結果として、元のビデオの視点を維持しながら、編集内容が自然に組み込まれた高い一貫性のビデオが生成される。
研究結果
DynVideo-EはHOSNeRFおよびNeuManのデータセットで、11の動的な人間中心のビデオに対して24の編集プロンプトを用いて詳細に評価を行った。その結果、DynVideo-Eは非常に高い時間的一貫性を持つフォトリアルなビデオ編集結果を生成し、既存の最先端の手法を大幅に50%〜95%も上回る成果を示した。

Source and Image Credits: Liu, Jia-Wei, Yan-Pei Cao, Jay Zhangjie Wu, Weijia Mao, Yuchao Gu, Rui Zhao, Jussi Keppo, Ying Shan, and Mike Zheng Shou. “DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion-and View-Change Human-Centric Video Editing.” arXiv preprint arXiv:2310.10624 (2023).
関連記事

「いらない人やモノ」だけを映像からキレイに消す技術「ProPainter」 シンガポールの研究者らが開発【研究紹介】

実写動画をアニメ映像に変える生成AI「Rerender A Video」 シンガポールの研究者らが開発【研究紹介】

青と黄を混ぜると「きちんと」緑色になるお絵かきデジタルツール 油絵や水彩画などのデジタル再現に活用【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


