![]()
![]()
脳信号だけでアバターを操作。表情や音声を復元、対話することに成功 米研究者らが発表【研究紹介】
2023年8月25日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
カリフォルニア大学サンフランシスコ校とバークレー校に所属する研究者らが発表した論文「A high-performance neuroprosthesis for speech decoding and avatar control」は、脳の信号だけでデジタルアバターを操作できるシステムを提案した研究報告である。
実験では、脳幹の脳卒中で重度の麻痺を持つ女性が、このブレイン・コンピュータ・インタフェース(BCI)を使ってデジタルアバターを通じて会話することに成功した。

同研究チームは、先行する研究において、脳幹の脳卒中を何年も前に経験した男性の脳信号を文字に解読する技術を実証した。今回の研究は、より進んでおり、人の顔の動きとともに、脳信号を音声に変換することに成功したのである。
※参考:脳に埋め込んだ電極で「発話内容」を読み取りテキストと音声に変換する技術 1分62英単語の高速出力に成功【研究報告】
このプロセスには253個の電極からなる紙のように薄い長方形が用いられ、女性の脳の表面に埋め込まれた。この電極は「音声感覚運動皮質」と呼ばれる部位に配置された。この部位は、人が話す際に唇、舌、顎、喉頭の動きを調整する脳の小さな領域であり、複雑な協調活動を行う。この配置によって、声道をどう制御するのかの地図が得られた。
電極は、女性の頭に固定されたポートに差し込まれたケーブルを通じてコンピュータに接続される。この電極が、彼女の顔だけでなく舌、顎、喉頭の筋肉への脳信号を傍受するのである。
彼女は数週間にわたり、研究チームと連携してシステムの人工知能アルゴリズムを訓練し、彼女特有の脳信号を音声として認識できるようにした。訓練には1,024語の会話語彙を用い、異なるフレーズを何度も繰り返して、コンピュータが音に関連する脳活動パターンを学習させた。
このシステムは単語全体を認識するのではなく、話し言葉を構成する音声の下位単位、音素から単語を解読するものである。音素の一例として、「Hello」は「HH」「AH」「L」「OW」の4つの音素から成り立っている。
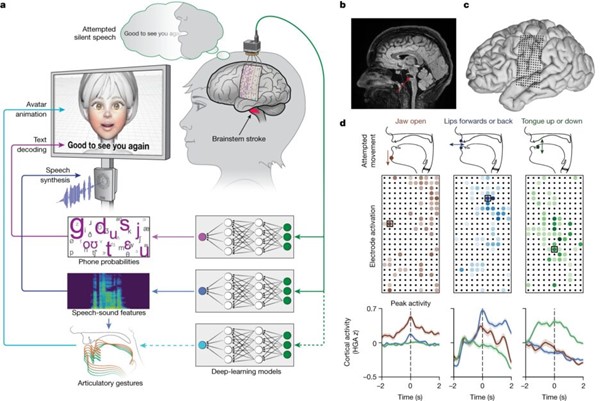
この研究チームが取り組んだアプローチにより、コンピューターは39の音素を学習するだけで、英語のあらゆる単語を解読できるようになったのである。これがシステムの精度向上に貢献し、処理速度も3倍に高まった。具体的には、1分間に80ワード近くのスピードで脳の信号をテキストにデコードすることが実現された。
さらに、音声合成の新たなアルゴリズムを考案した。これにより、女性が結婚式で話している録音を用いて、怪我をする前の彼女の声に聞こえるように音声をパーソナライズすることが可能となった。
顔の表情のシミュレーションには、フェイシャル・アニメーションを創り出す学習ベースのソフトウェアが使用された。このソフトウェアは、彼女が話そうとする際の脳からの信号を解析し、それをアバターの顔の動きに変換できるように、特別な機械学習プロセスでカスタマイズされている。

以上の技術を組み合わせることにより、脳信号からアバターの音声(彼女に似た声)と表情を復元し、よりリアルなコミュニケーションの再現が可能となったのである。
Source and Image Credits: Metzger, S.L., Littlejohn, K.T., Silva, A.B. et al. A high-performance neuroprosthesis for speech decoding and avatar control. Nature (2023). https://doi.org/10.1038/s41586-023-06443-4
関連記事

AIと人間のジレンマに打ち克てるか?中国、すべての判断をアルゴリズムに任せた「AIコンビニ」の葛藤

青と黄を混ぜると「きちんと」緑色になるお絵かきデジタルツール 油絵や水彩画などのデジタル再現に活用【研究紹介】

映像のみから動けるリアル3Dアバターを作成 服の動きまで精密に再現【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


