![]()
![]()
テキストのみで実写画像の部分的編集ができるモデル「Imagic」 Googleとイスラエルの研究者らが開発【研究紹介】
2022年10月26日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
Google Researchとイスラエル工科大学、同じくイスラエルのWeizmann Institute of Scienceによる研究チームが発表した論文「Imagic: Text-Based Real Image Editing with Diffusion Models」は、1枚の実写画像に対してテキストを用いた様々な部分的な意味編集を実行できる学習ベースの手法を提案した研究報告だ。
画像上にペイントしたり、編集箇所をマスクしたりといった補助入力を一切必要とせず、テキストプロンプトのみで元画像の全体的な背景や構造、構図を維持したまま、目的のテキストと一致する画像を出力することができる。
例えば、下図が示すように、2羽のオウムが離れた状態からキスをしているように見せる、直立の状態の人を親指を立てているように見せるなど、高解像度で自然な仕上がりを出力する。

課題
近年、画像編集は深層学習ベースのシステムの大幅な進歩により、広く関心を集めている。画像編集のために多くの方法が開発され、有望な結果を示し、継続的に改善されてきた。
しかし現在の主要な手法は、程度の差こそあれ、いくつかの欠点に悩まされている。例えば、画像の上に絵を描くペイント、オブジェクトの追加、編集したい場所を示す画像マスク、同じ被写体の複数画像など、多くのモデルではこれらの補助入力を必要とする。
研究内容
今回の研究では、上記の問題をすべて軽減するセマンティック画像編集手法「Imagic」を提案する。本手法は、編集対象の入力画像と編集内容を記述した1つのテキストプロンプトが与えられるだけで、実際の高解像度画像に対して高度な非剛体編集を行う。
具体的には、姿勢変更、構図変更、複数オブジェクト編集、オブジェクト追加、スタイル変更、色変更などが行える。

これらを達成するために、次のようなパイプラインを実行する。まず実写画像とテキストプロンプトが与えられると、テキストをエンコードして埋め込みを得る。次に、それを最適化して入力画像を再構成し、埋め込みを得る。次に拡散モデルを微調整し、入力画像への忠実度を向上させる。最後に画像の忠実度とテキストプロンプトの整合を共に達成できる点を探すため、最適化した埋め込みとテキスト埋め込みの間で線形補間を行う。
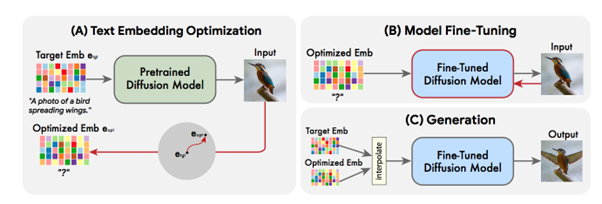
評価
Imagicの実力を示すために、様々な領域の多数の画像に対して本手法を適用し、いくつかの実験を行った。その結果、入力画像に高度に類似しつつ要求されたテキストプロンプトとうまく整合する高品質な画像を出力することができ、全ての実験において素晴らしい結果を達成した。

Source and Image Credits: Kawar, Bahjat, et al. “Imagic: Text-Based Real Image Editing with Diffusion Models.” arXiv preprint arXiv:2210.09276 (2022)
関連記事

「コード」から「漫画」を自動作成するツール「CodeToon」。カナダの研究者らが開発【研究紹介】

YouTubeなど動画内の人を3Dモデルで抜き取る技術 米ワシントン大とGoogle Researchが「HumanNeRF」開発【研究紹介】

たった1枚の画像からシャープな3Dモデルを自動生成 Google「3DiM」開発【研究開発】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


