![]()
![]()
たった1枚の画像からシャープな3Dモデルを自動生成 Google「3DiM」開発【研究開発】
2022年10月18日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
Google Researchの研究チームが発表した論文「Novel View Synthesis with Diffusion Models」は、わずか1枚の2次元画像から3次元オブジェクトを自動生成する拡散モデルを用いたフレームワークを提案した研究報告だ。画像から3次元的に一貫性のある複数の新規ビューを生成する。

研究課題
2020年に発表された拡散モデル(Denoising Diffusion Probabilistic Models)が話題になっている。敵対的アプローチよりも優れた学習安定性を持ちながら、高品質な画像生成に成功、圧縮や密度推定などのさらなる応用も可能にする。特にテキストから高品質な画像を自動生成するText To Imageモデルで多くの人に知られるようになった。

拡散モデルを理解する上で、簡単にText To Imageモデルの原理を説明する。まず、テキストの特徴量と画像の特徴量が同じ特徴量空間で等しく扱えるようにエンコード(テキストと画像を比較できる形式に変換すること)する。次にその情報をもとにデコード(エンコードされたデータを画像に復元すること)して画像を生成する。エンコード部分ではCLIPがよく使われ、デコード部分では拡散モデルが使用される。拡散モデルでは、ノイズ推定(元画像をガウシアンノイズまでノイズを付加していき、そこから戻るようにノイズを除去していくことで画像を生成する)という方法で高品質な画像生成を行っている。
このように、拡散モデルは画像生成の役割を扱うモデルなため、さまざまな画像処理タスクにおいて重宝される。画像から残りの画像を生成する、テキストから3Dモデルを生成する、超解像技術、インペインティング、カラー化などである。
一方で拡散モデルの活用が進んでいない画像タスクもあり、その1つが入力画像の新しい視点を予測すること(新規ビュー合成)である。
新規ビュー合成が話題になり始めたのもここ数年で、Scene Representation Networks(SRN)やNeural Radiance Fields(NeRF)の出現により、大幅に進歩した。だが、歪みやぼやけなどのアーティファクトの少ない3次元オブジェクトを構築するには、異なる角度から撮影した複数枚の入力画像を用意する必要があった。
研究内容
本研究はこの課題に対して、単一の2次元画像から3次元オブジェクトを再構築する拡散モデルを用いたフレームワーク「3DiM」を提案する。3DiMは単一の参照ビューと相対的なポーズを入力として受け取り、新しいビューを生成するために訓練される。
フレームワークは、 UNetアーキテクチャの改良版であるX-UNetと、拡散モデルを用いて各フレームで自己回帰的に生成できる新しいサンプリングアルゴリズムの組み合わせで構成される。
X-UNetは、 通常のUNetにウェイトシェアリングとクロスアテンションを加えて改良する。サンプリングアルゴリズムは、複数のフレームを作る自己回帰の処理と各フレームからノイズを除去する処理の2つに分けられ行われる。この組み合わせにより、わずか1枚の画像から非常にシャープなサンプル品質で、3次元においてほぼ一貫したビューを生成する。
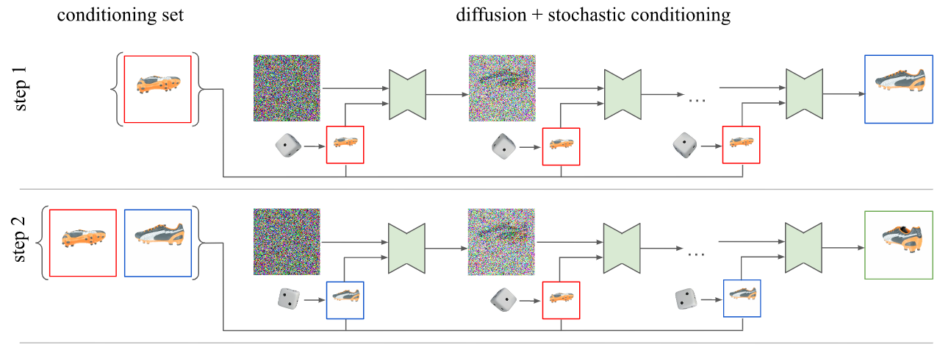
このように3DiMの中核をImage-to-imageモデルとしておくことで、複数のフレームを共同でモデル化するアーキテクチャの設計と学習の難しさを回避することができる。また、1シーンあたり2ビューしかないデータセットでの学習を可能にすることも利点である。
さらに、学習データに矛盾があると性能が低下するため、モデルの出力画像に対してNeural fieldsを学習させ、ジオメトリにとらわれない生成モデルの3次元的一貫性を定量的に評価するスコアリングも開発し導入している。
研究評価
本提案手法を評価するため、少数の画像から新規ビュー合成を行う最先端手法と出力結果を比較した。SRN ShapeNetベンチマークを用いて行った結果、先行する手法よりも3DiMの方がよりシャープに表示された。拡散モデルにより、ぼやけの少ない高品質な仕上がりになったと考えられる。

3DiMは1つのモデルでデータセット全体をモデリングできるため、実世界の3Dデータセットに適用できる可能性が示唆された。ただし、その場合ノイズの多いポーズや焦点距離の違いなどを考慮しなければならないという。
Source and Image Credits: Daniel Watson, William Chan, Ricardo Martin-Brualla, Jonathan Ho, Andrea Tagliasacchi, and Mohammad Norouzi. Novel View Synthesis with Diffusion Models
関連記事

顔のみをアニメ風にして動画配信。動く人の顔を高品質に漫画化するスタイル転送技術「VToonify」【研究紹介】

青と黄を混ぜると「きちんと」緑色になるお絵かきデジタルツール 油絵や水彩画などのデジタル再現に活用【研究紹介】

手書きスケッチで描いたキャラやロボットの関節を自在に動かせるデザインツール 韓国チームが開発【研究紹介】
人気記事

ワークス同期たちの、今だから話せる「原点」。カミナシCTOとKyash、タイミーVPoEが新卒時代に得たもの、失ったもの

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?

