![]()
最新記事公開時にプッシュ通知します
![]()
1枚の写真から作成する動くメガピクセル頭部アバター。ロシアチームが開発【研究紹介】
2022年8月26日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
ロシアモスクワのSamsung AI Center、Skolkovo Institute of Science and Technology、Yandex Armeniaの研究チームが開発した「MegaPortraits: One-shot Megapixel Neural Head Avatars」は、1枚のポートレート写真から高解像度(メガピクセル)の動く頭部アバターを生成するシステムだ。

研究課題
ここ数年、1枚の写真からリアルな動くアバターを作成する手法が複数開発されている。これらの手法は、様々な人物の動画からなる大規模なデータセットに対する事前学習を活用し、人間の外見に関する一般的な知識を用いてワンショットでアバターを作成している。
この種の手法で得られる出力結果は素晴らしいが、その品質は学習データセットの解像度によって大きく制限される。この制限は、より高い解像度のデータセットを収集することで簡単に回避できるものではない。なぜなら、データセットは大規模かつ多様である必要があり、一人当たり複数のフレームを持つ数千人に対して、多様な照明、背景、顔の表情、および頭のポーズなどを含む必要があるためだ。
これらの基準を満たすすべての公開データセットは解像度が限られており、結果、最新のワンショットアバターシステムでさえ、最大512 × 512の解像度でアバターを学習している。
研究概要
本研究では、1枚のポートレート写真からメガピクセル(解像度1024 × 1024)の頭部アバターを出力する新しい学習モデルを提案する。
モデルは2段階で行われる。1段階目は、ドライバー画像の動き(頭のポーズと顔の表情などのモーションデータ)をソース画像(動かしたい画像)の外観に転移してアニメーションを生成する。これは既存のベースモデルによって実行される。
2段階目では、メガピクセルへのアップグレードを行う。メガピクセルへアップグレードは、中解像度の動画データセットに加え、高解像度の静止画の追加データセットを用いて学習する方法で実現する。
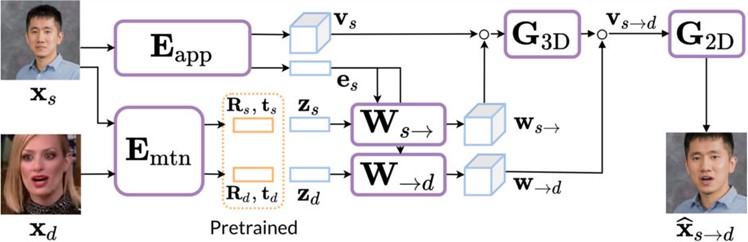
結果、同じ学習データセットを用いながら、提案手法はベースラインの超解像アプローチを凌駕する性能を示した。下記の画像を見てもらうと分かるように、瞼や視線、頭部の傾きまで精密に転移できているのが確認できる。

さらに研究チームは、訓練されたワンショット頭部アバターモデルに対して、リアルタイムで動作させるための蒸留ステージを追加している。蒸留とは、モデルの圧縮方法の1つで、大きいモデルを教師モデル(Teacher network)として、大きいモデルで得られた予測結果を小さい生徒モデル(Student network)の学習に利用する方法である。これにより、大きいモデルに匹敵するほどの精度を持つ小さいモデルを作成することができる。
一方で、高解像度になる代償としての制限もある。学習に用いるVoxCeleb2およびFFHQデータセットはいずれも正面からの視点が多いため、非正面の頭部ポーズが強い、もしくは肩の動きが激しいとレンダリング品質が低下する。また、現状では高解像度の静止画しか学習できないため、動きに伴うある程度のちらつきが発生する。
Source and Image Credits: Drobyshev, Nikita, et al. “MegaPortraits: One-shot Megapixel Neural Head Avatars.” arXiv preprint arXiv:2207.07621 (2022).
関連記事

「テレポート会議」ができるレベル 全身の動きを忠実に真似する実写アバターを米Metaが開発【研究紹介】

【動く城のフィオ】物理現実を「捨てた」僕がメタバースで東京をつくった理由 バーチャルで送る「セレクテッドな人生」とは

バーチャルデータサイエンティストアイシア=ソリッドが語る もう一度DAY ONEを始めるために「仕込み」を続ける真意
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


