![]()
最新記事公開時にプッシュ通知します
![]()
メガネ、メイク、豆電球!? AIを幻惑する敵対的サンプルの歴史を振り返ってみた
2022年5月17日


ITジャーナリスト
生活とテクノロジー、ビジネスの関係を考えるITジャーナリスト、中国テックウォッチャー。著書に「Googleの正体」(マイコミ新書)、「任天堂ノスタルジー・横井軍平とその時代」(角川新書)など。
iPhone X以降に搭載されるようになった顔認証機能を筆頭に、AIを使って顔検出、人体検出を行い、個人を識別し決済管理や入退室管理などを行うシステムは、すでに多くのデバイスで使われるようになっている。
しかし、人間が錯視画像に騙されるように、AIも特定のパターンに容易に惑わされる。敵対的サンプル(Adversarial Example)は大きな研究テーマになっており、AIの安全性を高めるだけでなく、ブラックボックス化しているAIの学習プロセスの解明にもつながる。
撹乱と回避。メイク、メガネ、豆電球によって生成される敵対的サンプル
「AI」「顔認証」といったら「個人情報漏洩」と思い浮かぶ方も少なくないはず。最近では、JR東日本が2021年7月に、主要駅に顔認証機能付き防犯カメラを8350台設置し、刑務所の出所者/仮出所者の顔写真を検知するシステムを導入したのち、「社会的コンセンサスがまだ得られていない」として取りやめたことが話題になった。
参考:「駅で出所者を顔認識」とりやめ JR東「社会的合意まだ得られず」
そんななか、かなり前から顔検出に引っかからないためのメイクを提案してきたアーティストがいる。アダム・ハーベイ氏は2014年からAIを惑わすメイクアップを提案している。CV Duzzle(コンビュータービジョン迷彩)と名づけられたメイクを施すと、顔検知のアルゴリズムを巧妙にハッキングしてインテルが開発をして広く使われるコンピュータービジョンライブラリー「Open CV」を幻惑し、顔として認識されなくなる。
このように、AIを幻惑し、騙す手法のことは敵対的サンプル(Adversarial Example)と呼ばれる。
CV Dazzle Look 5 from Adam Harvey on Vimeo.
▲CV Duzzleの検出プロセスのデモ。顔検出はさまざまな明暗パターンを検知し、その構成比が統計的に顔に近いと、顔だと判断をする。メイクによって余計な明暗パターンを加えることで、一般的な顔の統計情報から外れるために、顔だとは認識されなくなる
顔検知については、前稿(※リリース後リンク添付)を参考にしていただきたいが、簡単に説明すると、さまざまな明暗パターンを検出して、明暗パターンの構成比を割り出し、それが統計的に顔特有の明暗パターン構成比に近い場合に顔だと判断するというものだ。
ほかには、カーネギーメロン大学のマハメッド・シャリフ氏のチームによる研究では、簡単な明暗パターンや、明暗パターンのフレームでつくったメガネをかけるだけで、顔検出を回避できることが示された。
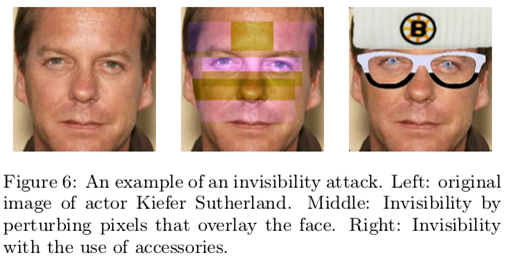
さらに、マハメッド・シャリフ氏らのチームは、この顔検出回避メガネをさらに発展させて、別人と認識させることにも成功した。マハメッド氏が特殊な模様がプリントされたメガネをかけると、AIはマハメッド氏ではなく、まったく別人のアリエルという女性だと判断をした。理屈上は、このメガネを利用すれば、他人の口座で顔認証決済ができるようになったり、顔認証による入室管理をしている施設に侵入ができるようになる。

このなりすましメガネのつくり方の原理はシンプルだ。フェイク画像の生成にも使われているGAN(Generative Adversarial Network、敵対的生成ネットワーク)を使う。GANは贋金つくりの例えでよく説明される。贋金を生成するAIと贋金を見分けるAIの2つを用意し、生成AIがつくった贋金を判別AIが見分ける。生成AIはより判別AIを騙せるように学習が進み、判別AIはより精巧な贋金も見分けられるように学習が進む。互いが互いを高め合って、高速で学習が進むというものだ。
マハメッド氏の顔写真にランダムノイズをプリントしたメガネ画像を重ね合わせ、判別AIはこれがアリエルかどうかを判別する。生成AIはアリエルだと誤解されるようにメガネのプリント模様を変えていく。このようなGANで、最終的には「アリエルだと判別される、メガネをかけたマハメッドの画像」が得られる。
豆電球の「レフ板」で赤外線による人体検出を回避
本人認証に使われるのは顔だけではない。近年では体型認証や歩行認証も本人認証の補助手段として活用されるようになっている。例えば、解像度が低い市中の防犯カメラに映った不審人物を特定し、その人物がカメラのアングルを外れたら、別のカメラから検出して、追跡するということができる。また、地下鉄の顔認証自動改札で、改札で顔認証をするのは時間がかかるため、遠方から体型や歩行行動で個人の絞り込みをあらかじめ行なっておくことで、改札での顔認証時間を短縮しようという試みもある。
こういった人体認証の動きに対して、清華大学のジュー・シャオペイ氏らの研究チームは物理的な攻撃方法を提案している。赤外線映像から人を検出する物体検出ライブラリ「YOLOv3」に対して、一定パターンの豆電球を取り付けた板を手に持ち、赤外線センサーの体温検知機能を利用して、システム幻惑させる手法を開発した。実証実験の結果では、豆電球板をもった被験者の平均検出率(AP)は通常より34.48%低下したという。
参考「Fooling thermal infrared pedestrian detectors in real world using small bulbs」
人間とAIの判断が食い違う敵対的サンプル
さらに、人間の判断とAIの判断がまったく違ってしまう敵対的サンプルも知られている。図の例では、左の列に3枚の写真が並んでいて、上からスクールバス、うずら、ヒンズー教寺院になっている。右の列にも同じ写真が並んでいる。しかし、この右列の写真をAIに物体検出させると、AIは3枚とも「ダチョウ」と答えるのだ。

つまり、人にはわからないように、AIだけに誤解させる画像をつくることができる。鍵になっているのは中央の画像で、これは元画像とダチョウ画像の差分画像で、これを元画像に合成することで、敵対的サンプルをつくることができる。
ディープラーニングの物体検出では、まず画像の細部のパターンを検出し、その複数の検出パターンがどのような比率で構成されているかを見て、物体特有のパターン構成を学習していく。つまり、細部からだんだん全体を見るように学習をしていく。ここで、ダチョウ画像の細部パターンを元画像に埋め込むと、AIにとってはダチョウの画像であると判別するが、全体しか見ない人間の目にはスクールバスであるかのように見える。
このような敵対的サンプルは、自動運転AIの交通標識の認識に対する攻撃の可能性をが懸念されている。例えば、人間の目には「通行止め」に見える標識に、AIには「駐停車禁止」に誤解をする標識を設置しておくと、自動運転車は危険が待ち受けるにも関わらず、止まることなく侵入をしてしまうことになる。
AIの社会実装が進む中で注目される敵対的サンプル研究
2020年10月14日に、スコットランドのインバネス・カレドニアン・シッスルFCのサッカーの試合中継で面白いことが起きた。本拠地のカレドニアンスタジアムには、AIカメラ「ピクセロット」が導入されて、自動でボールを追跡し、無人でライブ中継が行えるというものだった。
ところが、この日の試合では線審にスキンヘッドの人がいた。ピクセロットはなぜかボールではなく、この線審を追いかけてライブ中継を行った。
これは笑い話にすぎないが、AIが生活の中であたりまえのように活用されるようになり、敵対的サンプルの研究はますます重要になっている。直接的には、AIの実用精度をより高める改良が可能になることだ。また、間接的にはAIのロジックの解明につながる。ディープラーニングは原理はわかっているものの、具体的にどのような学習が行われているのかまだまだ未解明の部分が多い。錯視画像を研究することで、脳の信号処理の仕組みが解明されていくように、敵対的サンプルを研究することでAIの仕組みが解明されていくのではないかと期待されている。
ここで紹介したのは、視覚による敵対的サンプルだが、当然、音声、データの敵対的サンプルを生成することも可能だ。音声データが別人と判別される、話の内容がまったく違った内容に理解されるなどということも起こり得る。マルウェアがAIの監視を潜り抜け、有用なソフトウェアだと判断してしまう。そのようなことも起こり得る。敵対的サンプルは、AIを活用するセキュリティ企業では押さえておくべき重要な情報になっているだけでなく、セキュリティ研究、AI研究としても大きなテーマになってきている。
関連記事

AIが大学レベルの数学を即座に解き、高品質な問題の生成にも成功。プログラム合成技術を活用 MITなどが発表【研究紹介】

画像の畳み込み演算に3D顔メッシュモデル。中国版TikTok「ドウイン」のクリエイティブを支える顔検出技術を解説

28位と中位グループに下げ止まった日本。IMD国際デジタル競争力ランキングから見えてくる日本ITの弱みと希望は?
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


