![]()
最新記事公開時にプッシュ通知します
![]()
「DeepSeekショック」後、生成AI開発のオープンソース化は進むのか
2025年3月11日


ITジャーナリスト
生活とテクノロジー、ビジネスの関係を考えるITジャーナリスト、中国テックウォッチャー。著書に「Googleの正体」(マイコミ新書)、「任天堂ノスタルジー・横井軍平とその時代」(角川新書)など。
大きな話題となった中国AI「DeepSeek(深度求索)」。米国AIの優位性が揺らぎかねないことから「DeepSeekショック」という言葉も使われた。
一方、AI開発の世界では技術は“ガラス張り”になっており、米国AIがDeepSeekの技術を吸収することは難しくない。米国AIの優位性がすぐには影響を受けることはないだろう。
それよりも、注目しなければならないのは、DeepSeekがオープンソースで開発しているということだ。米中ともにAIはオープンソース化必至の状況になり、ここが新たな競争の焦点になっている。本記事では、2024年12月公開の大規模言語モデル(LLM)「DeepSeek-V3」のテクニカルレポートをもとに、生成AI開発のオープンソース化について考察する。
- 投資家の動きからみるDeepSeekショックの正体
- 低コスト・高性能でAI開発の常識を揺るがしたDeepSeek発LLMの登場
- 輸出規制を乗り越えた地道で高度なプログラミング
- AI開発に押し寄せるオープンソース化の波
- DeepSeekショック後のAI開発の展望
投資家の動きからみるDeepSeekショックの正体
中国スタートアップ「DeepSeek」が公開したLLMベースのチャットボットAI「DeepSeek-R1」が、大きな話題となり、「DeepSeekショック」とも呼ばれる現象を起こしている。OpenAIのGPTとほぼ同じ性能でトレーニングコストが10分の1以下という点が衝撃を与え、多くのメディアが「米国AIの優位性が揺らぐ」と報道した。しかし、本当にそうだろうか。
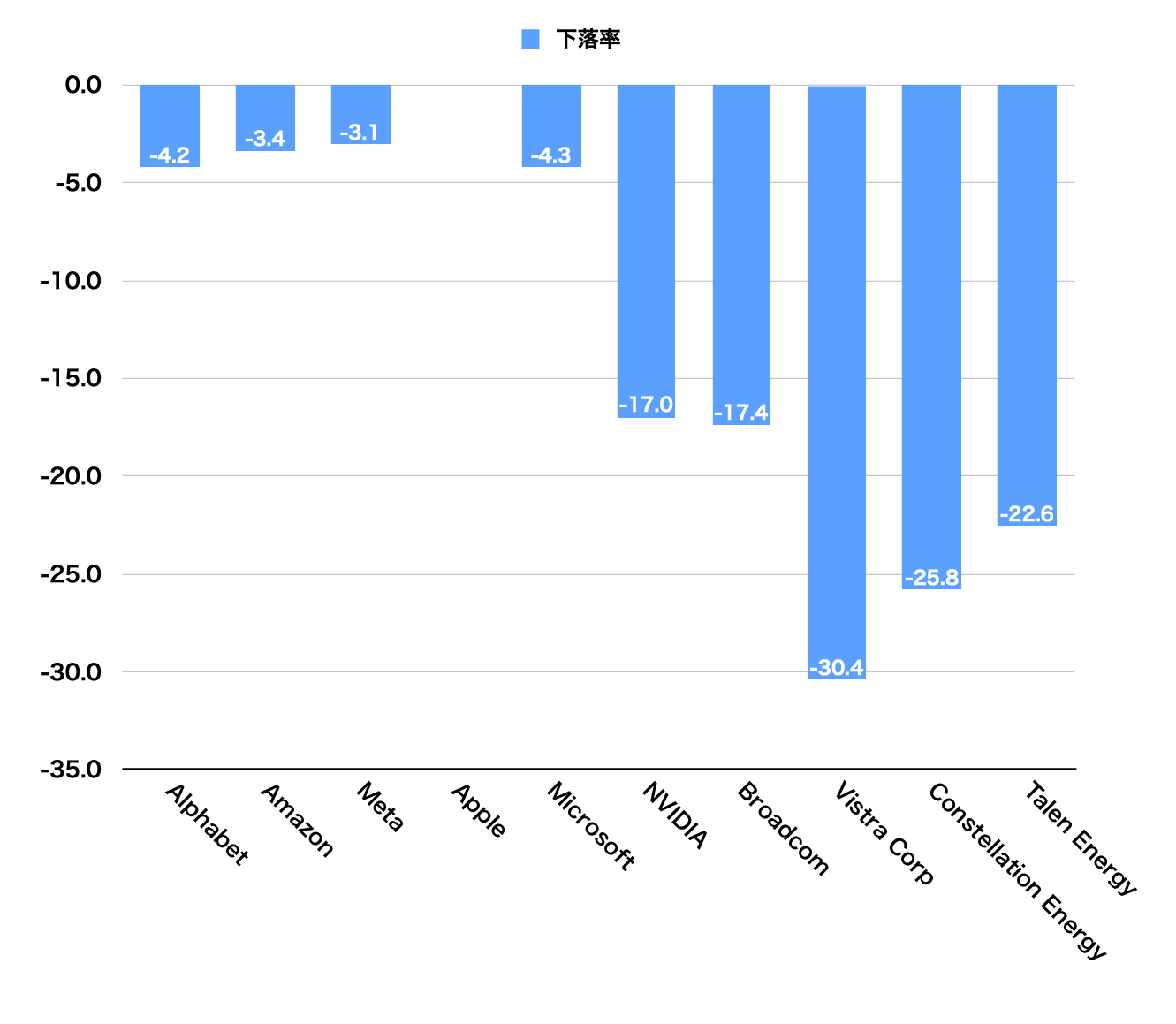
今回、DeepSeekショックが起こる前の今年1月24日の株価終値を基準にして、翌週の関連企業の最安値を調べ下落率を計算した。結果を3つのグループに分けて比較してみた。
1. GAFAMなどのAI開発企業
AIツールの開発・提供を行っているGAFAMは、アップルを除いて下落率がいずれも3%から4%でそう大きくはない。アップルに至っては下落もしていなかった。
2. AI基盤企業
AI開発に必須であるGPU(Graphics Processing Unit)を製造しているNVIDIA(エヌビディア)、ネットワーク機器を製造しているブロードコムはいずれも17%程度の下落をしており、2月上旬の執筆時点で1月24日の終値に戻りきっていない。
3. 電力ベンチャー
AI運用で需要が急増するとみられているデータセンターに電力を供給する電力ベンチャー3社はいずれも20%以上の大幅な下落をしている。これも執筆時点で1月24日の終値に戻りきっていない。
このことから、投資家たちは「米国AIに大きな影響はない。しかし、AI基盤に対する需要は弱まるのではないか」と見ていると推測でき、これこそDeepSeekショックの本質といえる。
低コスト・高性能でAI開発の常識を揺るがしたDeepSeek発LLMの登場
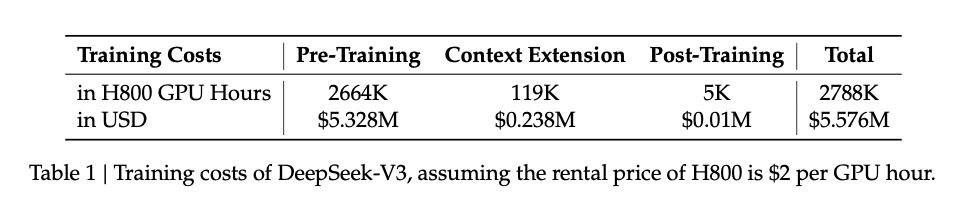
「DeepSeek-V3 Technical Report」によると、同モデルのトレーニングコストは、わずか557.6万ドル。これはGPU「H800」を2048枚使い、使用コストが1時間2ドルという想定で算出されている。性能面で匹敵するOpenAIのGPT-4oのトレーニングコストは非公開だが、報道では1億ドル前後かそれ以上とされている。
DeeSeekは、10分の1以下のトレーニングコストでありながら、GPT-4oと同等の性能を出していることになる。

これにより、「AI開発は、膨大なAI基盤を使わなくても可能なのではないか」という考え方が投資家らの間に広がり、AI基盤関連企業の株価が下落をしたというわけだ。
ところで、「AI開発に膨大なAI基盤が必須」というのがこれまでの常識だった。その考えは強烈な成功体験に基づいている。
AIの研究は1950年代から行われてきたが、半世紀にわたって大きな成果を上げることができないままにいた。状況を変えたのが、2000年代に研究者の間で話題となり始めたディープラーニングだ。
ディープラーニングは、それまで単層で構成されていたニューラルネットワークを思い切って多層化したら精度が上がるのではないかという仮説に基づいた手法で、実際にトロント大学の研究チームが2012年、世界的な画像認識コンテンストで圧倒的な成績を残した。さらに、研究チームのリーダーであったジェフリー・ヒントン氏が、2024年のノーベル物理学賞を受賞した。
グーグルは、2017年に論文「Attention is All You Need(アテンションこそすべて」で、画期的なAIモデル「Transformer」を提案した。OpenAIはこれを見て、「パラメーター数を思い切って増やしてみたらどうなるか」という仮説に基づいてChatGPTを開発した。人間と自然な対話ができるレベルのAIが登場してきた。
思い切って規模を拡大するとブレークスルーが起きる。これは「スケール法則」と呼ばれ、AI開発者の間では常識となっていた。その最たる例が、ドナルド・トランプ米大統領が発表したスターゲート計画で、4年間で5000億ドルを投資して、巨大なAI基盤を整備するというものだ。その直後にDeepSeek-R1が公開され、スケール法則は果たして正解なのかどうかという議論が始まっている。
輸出規制を乗り越えた地道で高度なプログラミング
では、DeepSeekはどうやってトレーニングコストを抑えたのだろうか。その答えは1つではなく、ありとあらゆる最適化手法を試した結果と言える。そして、その概要を解説したDeepSeek-V3のテクニカルレポートは、「最適化手法カタログ」のようなものになっている。レポートによると、独創というよりは、鬼気迫る勢いで改善が重ねられ、異様な熱気の中で開発が進んでいたことがうかがわれる。最終的に冗長計算(同じ計算の繰り返しで無駄な処理が行われること)の80%を削減することに成功したという。
例えば、GPUをハックする話が出てくる。当時、最高性能を誇るGPUはH100だったが、米国政府の規制により中国には輸出できないことになっていた。そこでNVIDIAは、H100の性能をほぼ半分に落とした「H800」を製造し、これを中国向けに輸出した。この性能の落とし方は帯域制限だ。つまり、H800はH100と同等の演算性能がありながら、データを半分しか送れないため、半分のデータ処理しかできない。
DeepSeekはこの壁を乗り越えようとした。2048枚のH800のうち、20枚をデータ送受信専門にし、必要な処理データをあらかじめ2分の1に圧縮をしてGPUに送信をし、GPUの中で展開し演算処理をする。その結果を再び圧縮し、戻す作業をこなした。10のものを5に圧縮して送り、中で10に展開し演算させる。こうすることで10の演算性能をフルに利用することができるようになる。
ただし、このような仕様を超えた使い方は、通常のプログラミング言語ではできない。
NVIDIAは、GPU専用のCUDA(クーダ)というプログラミング言語を開発し、このCUDAを使うとライブラリにデータを渡すだけでGPUの処理が行えるようにしていた。世界中のAI開発者がNVIDIAのGPUを求めるのは、GPUとしての性能が優れていることもあるが、このCUDAが使いやすいということも大きい。
しかし、DeepSeekがやろうとしていることはCUDAではできなかった。そこで、アセンブラ(マシン語)に近い「PTX」でプログラミングをして実現した。GPUの命令を直接並べていくような方法で、GPUの構造に対する深い知識が必要になり、かつ気の遠くなるような作業が必要になる。それをDeepSeekの開発チームはやり切ったのだ。
AI開発に押し寄せるオープンソース化の波
DeepSeekショックは、今後のAI普及にも大きな影響を与える。
まず、DeepSeekがオープンソースであるという点が大きなポイントになる。オープンソースであれば誰でも自由にダウンロードし、自分の環境で動かしてみることができ、さらには改変をして再配布をすることもできる。米国ではメタの「Llama(ラマ)」のほかにもオープンソースのAIモデルが登場し始めたが、OpenAIをはじめとするAIのほとんどがクローズドソースであり、オープンソースで高性能のモデルが登場してきたということが脅威であることに変わりはないはずだ。多くの米国AI企業もオープンソース化を真剣に考えなければ生き残っていけなくなるだろう。
さらに、オープンソースでありながら、最先端のMoEアーキテクチャを採用しているということがDeepSeekの最も光る点だ。MoE(Mixture of Experts)は、グーグルが提案をし、Geminiなどにも使われているが、DeepSeekはこれをさらに洗練させて採用した。
一般的なAIモデルというのは1つの専門家モデルがすべての処理を行う。それに対して、MoEは小さな専門家モデルの集合体になる。DeepSeek-V3の場合、256の小さな専門家モデルのうち、8個ほどが協働して回答を生成している。
このMoEの最大のメリットは、小さなモデルであるためトレーニングにかかるコストが節約でき、なおかつ得意分野を持つ専門家モデルが回答するため精度を出しやすいということだ。同パラメーター数の単一モデル方式に比べて、トレーニングコストは40%減少し、生成速度は80%向上するという。
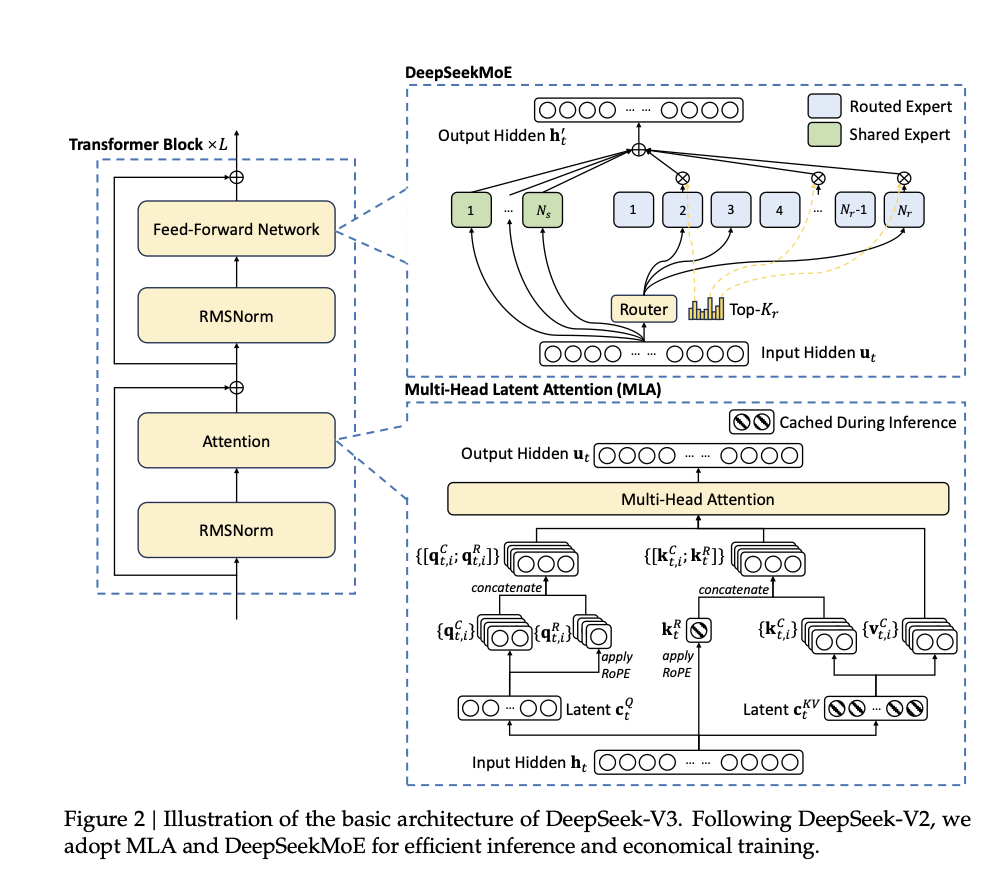
このMoEは、運用面でも大きなメリットがある。DeepSeek-V3は6710億ものパラメーターを持っていて、稼働させる時にはこのパラメーターをすべてメモリ上に展開しなければならない。そんなことは通常のPCでは無理な話で、専用のサーバーが必要になる。しかし、MoEアーキテクチャでは、実際は8つのモデルしか動かないため、6710億のパラメーターのうち活性化されるのは370億程度にすぎない。このレベルであれば、専用サーバーなしでも高性能PCで動かすことが可能だ。SNS上では、Mac Studio(Macの上位機種)やMac miniを複数台連結したシステムで稼働に成功したという報告がいくつも投稿されている。
従来のAIモデルはPCでは動かすことができないため、ウェブやAPIを通じて入力プロンプトを送信し、専用のサーバーで処理をしてもらい、その結果を返してもらうという使い方をせざるを得ない。これはユーザー企業にとって悩ましい問題だ。なぜなら、入出力の経路とサーバーのセキュリティ評価ができないために、企業内部の情報や顧客情報を入力することができないのだ。結局、内部情報を入力しないルールを設けて、限定的な使い方にとどめざるを得ないことになっている。
しかし、オープンソースであるDeepSeekは違う。ダウンロード後、高性能PCにインストールすると、社内ネットワークの内部に設置してしまうことができる。外部に送信をしない環境で運用をすれば、内部情報や顧客情報をAIに処理してもらえるようになる。つまり、企業のAI活用が一気に本格化をすることになる。
もちろん、DeepSeekが今後さまざまな企業や機関で使われるようになるかどうかは分からない。メタのLlama、アリババの「通義(Qwen)」もオープンソース戦略を取っており、その他のAI企業も対抗をしてオープンソース版をリリースすることは十分に考えられる。
DeepSeekはその技術を論文の形で公開しており、ソースコードも公開をしているため、技術はガラス張りになっている。米中のAI企業は必死になって解析をして、その技術を洗練させて自社モデルに取り込もうとしている最中だ。メタではウォールーム(戦時対策室)を設置したとも言われる。
DeepSeekショック後のAI開発の展望
生成AIはすべてオープンソース化すべきだという意見も大きくなっている。Open AIとマイクロソフトは、DeepSeekがGPTの入出力結果を“蒸留”してトレーニングに利用したと非難をしている。しかし、その行動に対して「いったいどの口で非難をしているのか」と指摘する人も多かった。ChatGPTは、権利者の断りなくネット上のドキュメントを学習素材として使っているとして、作家やメディアから複数の訴訟を起こされている。自分が利用する時は「フェアユース」(公正な利用)を主張しておきながら、他人が利用することに対しては非難をするのは矛盾ではないかという指摘だ。
DeepSeekは、メタのLlamaやアリババの通義を蒸留して学習に使用したことを論文の中で明らかにしている。Llamaや通義はオープンソースであるため、法的な問題は起こらないためだ。画像生成AIなどでは、自分が描いたイラストなどをネットで発表している人たちから、勝手に学習素材にされることに対する拒否感が強い。このことからも生成AIがオープンソース化されることにより、社会の見方は変わってくるだろう。米国AI企業は、何らかの形でオープンソース化を考えなければならなくなっている。
DeepSeekショックの本質とは「低コストで高性能のAIが登場した」というところではなく、「オープンソースで軽量動作のAIが登場した」ということにある。今年は、企業や機関へのAIの本格導入が進み、業務や生活のさまざまなシーンでAIが活用される年になる可能性が高い。AI企業各社は、米中ともに、AI開発の競争からAIの社会実装に向けた競争に移ることになる。
関連記事
科学論文の査読にLLMが使われている?誤字修正目的の範囲を超えての使用も スタンフォード大など調査【研究紹介】

初めてのAIプロダクトで「独自LLMで会話するAI VTuber」を開発。にゃおきゃっと氏に聞く「今10分触ってみる」が持つ力
AIが自分自身に報酬を与えて進化する「自己報酬型言語モデル」 米Metaなどが開発、実験でGPT-4を上回る【研究紹介】
人気記事

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理

国産組込みOS「ITRON」が40年生き残ってきた理由を、生みの親と振り返る【TRON】

インデックスを張るだけでは足りない。数億件の名刺データを扱うSansanのSQLパフォーマンス改善