![]()
![]()
AIが自分自身に報酬を与えて進化する「自己報酬型言語モデル」 米Metaなどが開発、実験でGPT-4を上回る【研究紹介】
2024年1月23日

先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
米Metaと米ニューヨーク大学に所属する研究者らが発表した論文「Self-Rewarding Language Models」は、大規模言語モデル(LLM)が自分自身に報酬を与えることで繰り返し学習する「自己報酬型言語モデル」を提案した研究報告である。このモデルは、自身が生成した問題に対する応答に報酬を割り当て、その結果をトレーニングデータとして使用。自己を反復して訓練することで、精度を向上させられる。
研究背景
最新の研究によると、人間を超える知能を持つエージェントを作成するには、人間以上のフィードバックが必要であるとされている。現在のところ、多くの言語モデルは人間の好みに基づく報酬モデルから学習しており、これには2つの問題がある。ひとつは、人間のパフォーマンスレベルによって制限される可能性があること。もうひとつは、これらの固定された報酬モデルが、LLMの訓練中に改善を学習できないことである。
そこで提案されたのが、今回の研究で紹介されている自己報酬型言語モデルである。このモデルは、言語モデル自身がトレーニング中に反復して報酬を与えることで学習し、精度を高めるアプローチである。
研究内容
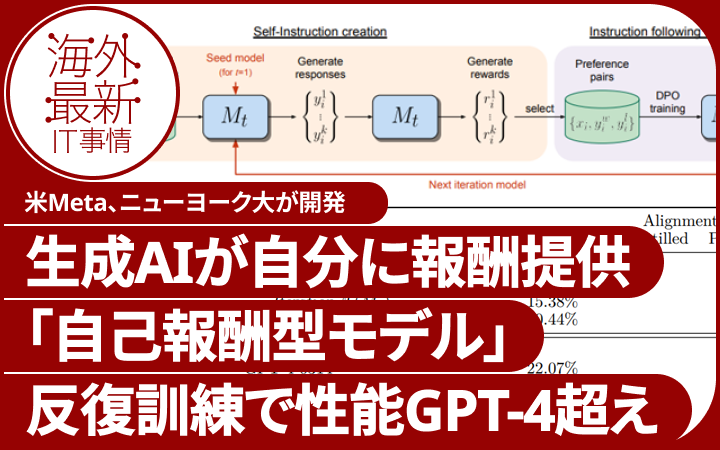
このモデルは2つの主要な機能を持つ。1つ目は、与えられたプロンプトに対して良い応答を生成する能力である。2つ目は、新しい問題(プロンプト)をつくり、それに対する答えを生成し、その品質を評価して(報酬を割り当て)、自分の学習データに加える能力だ。この評価は、「LLM-as-a-Judge」というプロンプトを用いて実行され、反復して訓練される。
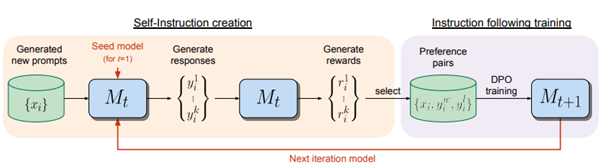

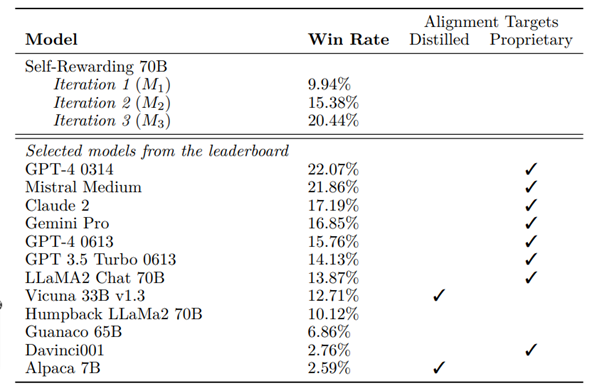
Llama 2 70Bを基盤(シードモデル)として実施された実験では、訓練を1回から3回反復することで、モデルの性能が回数を増すごとに向上すると示された。また、反復を3回行ったモデルでは、AlpacaEval 2.0リーダーボードでの評価において、Claude 2、Gemini Pro、GPT-4 0613など多くの既存システムを上回った。

研究評価
この訓練方法により、モデルの指示に従う能力と報酬モデリング能力が反復ごとに向上することが示された。モデルは、自分の答えを生成する能力を向上させると同時に、自分自身の報酬モデルとしても機能。通常は固定されている報酬モデルが、繰り返しのプロセスを通じて改善される。これは、人間などの外部からのフィードバックを不要にし、学習モデルが自分自身をよりよく改善できるようになることを意味し、自己改善の好循環を生み出す。予備的な研究であるが、限界を広げる可能性を秘めているといえる。
Source and Image Credits: Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, Jason Weston. Self-Rewarding Language Models.
関連記事

ゲーム開発もAIで完全自動化。ChatGPTが働く仮想のソフトウェア開発企業「ChatDev」

テキスト指示からリアルな立体物をつくる多視点拡散モデル「MVDream」 中国バイトダンスなどの研究者らが開発【研究紹介】

写真から生成した3Dモデルに人の手が触れたときの「弾力や揺れ」をリアルに再現する手法「PIE-NeRF」【研究紹介】
人気記事

ワークス同期たちの、今だから話せる「原点」。カミナシCTOとKyash、タイミーVPoEが新卒時代に得たもの、失ったもの

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?


