![]()
![]()
科学論文の査読にLLMが使われている?誤字修正目的の範囲を超えての使用も スタンフォード大など調査【研究紹介】
2024年3月21日

先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
スタンフォード大学やNEC Labs Americaなどに所属する研究者らが発表した論文「Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews」は、科学論文の査読(ピアレビュー)に大規模言語モデル(LLM)が使用された割合を調査した研究報告である。
研究背景
LLMの能力が高まるにつれ、AIによって生成されたテキストなのか人間が書いたテキストなのかを区別しなければならない問題が浮上している。なぜならAIによって生成された、根拠のないテキストが、権威のある証拠に基づいた文章、例えば科学論文を装う危険性が高まっているからだ。そして、今回この研究において、科学論文の査読にもLLMが使用されている可能性が示唆された。
研究内容
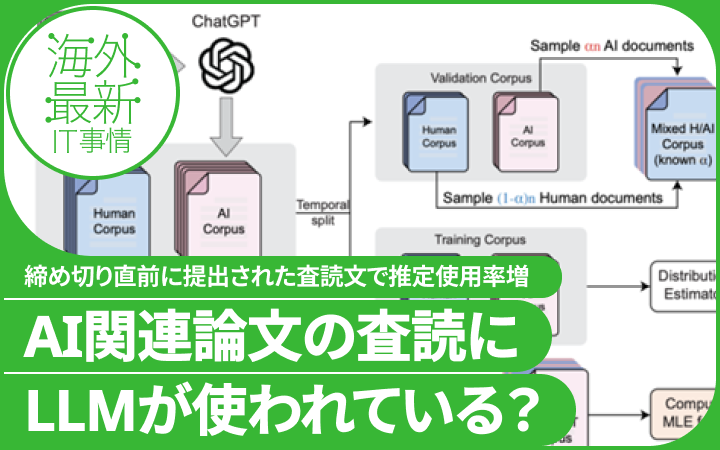
研究者らはLLMが使用されているかを調査するために、AIによって生成または修正されたコンテンツを効率的に調査するための新たなフレームワークを開発した。個々のテキストがAIによるものか人間によるものかを判定する従来のAIテキスト検出手法とは異なり、このフレームワークでは、テキスト全体(コーパス)の中でAIによるものがどのくらいの割合を占めているかを推定することに焦点を当てている。
具体的には、人間の専門家が書いた査読(以下、人間レビュー)とLLM(ここではGPT-4を使用)が生成した査読(以下、AIレビュー)を参照データとして使い、それらのデータから推定された単語の出現分布を比較することで、実際の査読コーパスにおけるLLMの使用割合を推定する。
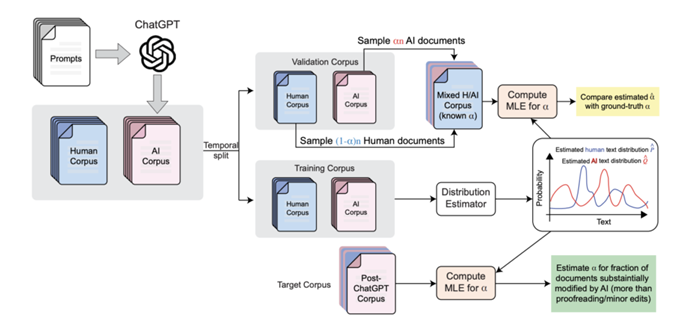
実験では、2018年から2024年までのICLR、NeurIPS、EMNLP、CoRLなどのAI関連のトップカンファレンスに査読として提出されたテキストへの詳細なケーススタディを通して、このアプローチを実証した。また、Nature誌のジャーナルに提出されたレビューについても調査を行った。ChatGPTのリリースが2022年なため、それ以前と後を区別した分析内容となっている。
まず人間レビューとAIレビューを混ぜ合わせた検証用データセットを作成し、提案手法の有効性を検証した。その結果、AIレビューの割合を1.8%未満の誤差で推定できることがわかった。また、訓練データに用いたものとは異なるカンファレンスのデータでも、良好な性能を示した。
研究結果
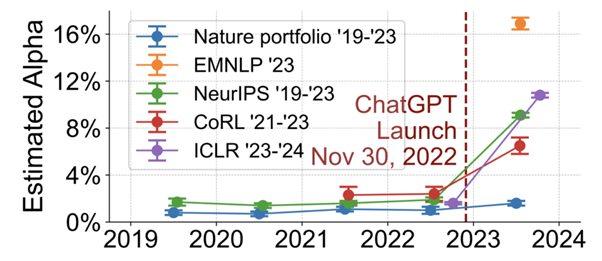
次に、ChatGPT(2022年)のリリース前後で、カンファレンスの査読のうち、AIによって大幅に修正されたとみられるものの割合がどの程度変化したかを調べた。その結果、AI関連のカンファレンスのレビューテキストの6.5〜16.9%では、ChatGPTのリリース後にAIによって大幅に修正されている可能性があることがわかった。一方、Nature誌では、そのような増加は見られなかった。
この結果の信憑性を高めるために、単なるタイプミスやスペルミス、文法ミス、すなわち校正にLLMを使っている割合も調べて、その差を比較した。その結果、校正でLLMが使われた割合は低く、よって単なるミスの修正以上の大幅な編集が行われたことが示唆される。
内容として以下のような傾向がわかった。まず、ChatGPTのリリース後、AI関連のカンファレンスのレビューにおいて、特定の形容詞の使用頻度が大幅に増加している。例えば、commendable(立派な)、innovative(革新的な)、meticulous(几帳面な)、intricate(複雑な)、notable(顕著な)、versatile(多様な)などだ。LLMで生成されたレビューでは、これらの形容詞が不自然なほど高い頻度で使われる傾向がある。
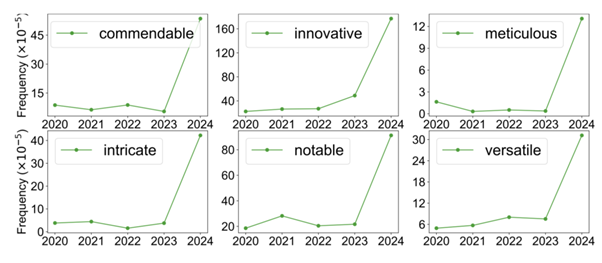
最後に、LLMの推定使用率と相関する要因についても分析を行った。その結果、締め切り3日以内に提出されたレビューほどLLMの推定使用率が高いこと、人間レビューの方が具体的なフィードバックや他の研究の引用が多いこと、著者との議論(リバッタル)が活発なレビュアーほどLLMを使用する可能性が低いこと、他のレビューと内容が似通ったレビューほどLLMの推定使用率が高いこと、レビュアーの自信の低さとLLMの使用率に負の相関があることなどがわかった。
なお、この研究では、AIを使って生成されたレビューが、元来の査読に相当するかについて議論はしていない。また論文のレビューにAIを使用することが必ずしも悪いことであるか、あるいは良いことであるかについて、価値判断を下すものではない。加えて、多くのレビュアーがレビュー全体にわたって完全にAIを使って書いているとは主張していない。
Source and Image Credits: Liang, Weixin, et al. “Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews.” arXiv preprint arXiv:2403.07183 (2024).
関連記事
AIが自分自身に報酬を与えて進化する「自己報酬型言語モデル」 米Metaなどが開発、実験でGPT-4を上回る【研究紹介】

「自分の絵を画像生成AIから守る」――学習される前に絵に“ノイズ”を仕込みモデルに作風を模倣させない技術「Glaze」【研究紹介】

GPT-4にWebサイトを“自律的に”ハッキングさせる方法 AI自身が脆弱性を検出、成功率70%以上【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


