![]()
最新記事公開時にプッシュ通知します
![]()
テイラー・スウィフトを中国語で歌わせる!? 音声変換もできる新音楽生成ツールキット「Amphion」【研究紹介】
2023年12月21日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
香港中文大学などに所属する研究者らが発表した論文「Amphion: An Open-Source Audio, Music and Speech Generation Toolkit」は、テキストや歌詞から音楽を生成する機能や、歌声の変換など、音楽や音声を総合的に取り扱うオープンソースの音楽生成ツールキットを提案した研究報告である。リポジトリはこちら。
▲中国語で歌う音声を米国歌手のテイラー・スウィフトさん風に変換したデモンストレーション動画
研究背景
音楽生成AIの分野では、歌詞や曲調を文章で指示すると音楽を生成する「Suno」や、ループ音源に応じて別パートを複数生成し統合する「StemGen」などの多くの研究が報告され注目されている。しかし、これらのリポジトリは分散しており、品質もばらつき、初心者には使いにくい状況がある。
今回、新たに登場した「Amphion」は、音楽だけでなく、音声やオーディオ全般の生成にも対応している統一されたフレームワークを提供する。このツールキットは、生成モデルの内部メカニズムを理解しやすくするための視覚化機能を備えており、音楽や音声の生成分野に新たに参入する研究者やエンジニアに向けた入門ツールの提供を目的としている。
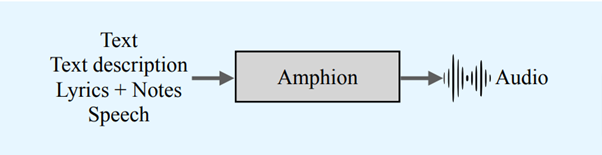
研究内容
Amphionには、テキストから音声に変換する「TTS」(Text to Speech)、歌声変換「SVC」(Singing Voice Conversion)、テキストからオーディオに変換する「TTA」(Text to Audio)の機能が含まれている。
今後予定されている機能として、歌声合成「SVS」(Singing Voice Synthesis)、音声変換「VC」(Voice Conversion)、テキストから音楽に変換する「TTM」(Text to Music)がある。
テキストから音声合成(TTS)においては、非自己回帰型の「FastSpeech 2」、エンドツーエンドの「VITS」、ゼロショットTTSアーキテクチャの「Vall-E」、潜在拡散モデルを使用する「NaturalSpeech 2」など、様々なアプローチをサポートしている。これらは、テキストから自然に聞こえる音声を生成するために設計されており、各モデルには独自の特徴がある。
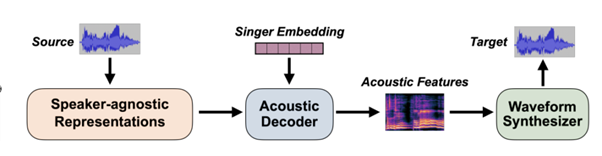
歌声変換(SVC)に関しては、Amphionは話者に依存しないコンテンツベースの表現と抑揚ベースの表現をサポートしている。具体的には、WeNet、Whisper、ContentVecから抽出された特徴を利用し、複数のコンテンツ特徴の組み合わせも可能である。また、ピッチや調子、音声の音量、強弱、アクセントのパターンなどの特徴もサポートしており、話者エンベディングはトレーニング中に学習可能である。音響デコーダーには、拡散ベース、トランスフォーマーベース、VAEおよびフローベースの様々なアーキテクチャが含まれている。
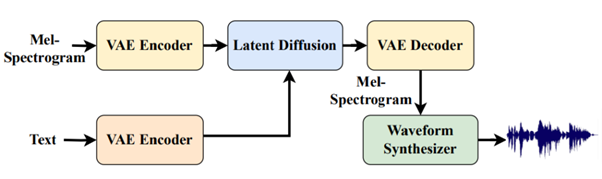
テキストからオーディオへの変換(TTA)においては、潜在拡散モデルに基づくアプローチが採用されている。このモデルは、入力されたメルスペクトログラムを効率的な低次元潜在空間に投影するVAEモジュール、記述的テキストを受け入れてテキスト条件のエンベディングを得るためのT5テキストエンコーダー、出力オーディオを生成する拡散ネットワークから構成されている。
評価
総じて、Amphionはオーディオ生成、音楽生成、音声生成の分野において重要なリソースを提供し、研究者やエンジニアが生成モデルの理解を深めるのに役立つツールとなっている。初心者にも使いやすい設計と視覚化機能により、この分野の研究と開発を大きく促進することが期待される。
Amphionのデモンストレーションとして、中国語で歌う音声をテイラー・スウィフト風に変換した出力結果を冒頭の動画で示している。
Source and Image Credits: Xueyao Zhang, Liumeng Xue, Yuancheng Wang, Yicheng Gu, Xi Chen, Zihao Fang, Haopeng Chen, Lexiao Zou, Chaoren Wang, Jun Han, Kai Chen, Haizhou Li, Zhizheng Wu. Amphion: An Open-Source Audio, Music and Speech Generation Toolkit.
関連記事

「3D化した顔を巧妙に仮装」 呪文で3Dシーンをスタイル変換するモデル「NeRF-Art」【研究紹介】

「いらない人やモノ」だけを映像からキレイに消す技術「ProPainter」 シンガポールの研究者らが開発【研究紹介】

「他人の“顔”で動画配信」——リアルフェイスマスクを映像内の動く自分に滑らかに適合できる技術 ディズニーなどが開発【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


