![]()
![]()
「3D化した顔を巧妙に仮装」 呪文で3Dシーンをスタイル変換するモデル「NeRF-Art」【研究紹介】
2022年12月26日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
香港城市大学、香港理工大学、Snap、Netflix、Microsoft Cloud AIに所属する研究者らが発表した論文「NeRF-Art: Text-Driven Neural Radiance Fields Stylization」は、事前に学習されたNeRFモデルのスタイルを、簡単なテキストプロンプトで操作するテキスト駆動型NeRFスタイライゼーションを提案した研究報告である。数枚の画像から生成した3Dシーンに対して、詳細にスタイル変換を行う。

研究背景
NeRF(Neural Radiance Field)は、3Dシーンの強力な表現手段として、マルチビュー画像からの高品質な新規ビュー合成を可能にするモデルである。しかし、NeRFの優れたシーン再構成品質を享受する一方で、高密度のMLPネットワークによってパラメータ化され絡み合う、外観と形状の高度なボリューム表現によって、NeRFは色と形状を共同で変換するスタイライズがより困難になっている。
NeRFスタイライゼーションのこれまでの研究では、ターゲットスタイルを指定するための一つの一般的な方法として採用されているものの、すべてのシナリオに対して必ずしも完璧な解決策とはなっていない。ましてや今回のように、テキストプロンプトに応じたNeRFのスタイル変換はより難しい。
研究内容
本研究ではこの困難な課題に対して、CLIPとNeRFを組み合わせたテキスト駆動型NeRFスタイライゼーション手法「NeRF-Art」を提案する。事前に学習されたNeRFモデルと単一のテキストプロンプトが与えられると、指定されたスタイルに準拠した、外観と形状の両方を変換した一貫した新しいビュー合成を可能にする。見た目だけでなく、NeRFのジオメトリも調整する。
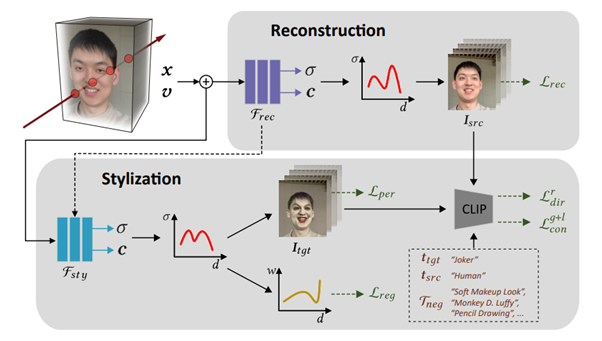
これはCLIPとNeRFを組み合わせることで実現されるが、このままでは所望のスタイル強度を確保するためには不十分である。この問題に取り組むために研究チームは、CLIPベースのコントラスト損失を設計して、結果をターゲットスタイルに近づけ、ネガティブサンプルとして事前に定義された他のスタイルから遠ざけることで、スタイライゼーションを適切に強化している。
さらに、シーン全体のスタイルの均一性を保証するために、コントラスト制御をグローバルとローカルのハイブリッドフレームワークに拡張し、グローバル構造とローカルディテールの両方をカバーする。さらに重みの正則化を採用して、密度場を変更する際に発生するアーティファクトとジオメトリノイズを効果的に抑えている。
実証実験
実験では、さまざまなシナリオにおいて、多様な類似モデルと比較することで本手法のテキストプロンプトによるスタイライゼーションの有効性を評価する。

結果は、実際の顔と一般的なシーンにおける広範な実験により、本方法がスタイライゼーションの品質とビューの一貫性の両方において効果的かつロバストであることが示された。さらにユーザー調査を行い、本手法が最先端の類似手法と比較して、最も視覚的に好ましい結果を達成することが示された。

Source and Image Credits: Wang, Can, Ruixia Jiang, Menglei Chai, Mingming He, Dongdong Chen and Jing Liao. “NeRF-Art: Text-Driven Neural Radiance Fields Stylization.” (2022).
関連記事

YouTubeなど動画内の人を3Dモデルで抜き取る技術 米ワシントン大とGoogle Researchが「HumanNeRF」開発【研究紹介】

サンフランシスコの街を画像からリアルに3D化 Waymoなど「Block-NeRF」開発【研究開発】

写真から「立体的なアート作品」をAIが自動作成 米Adobeなどが開発【研究紹介】
人気記事

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?

Rubyへの型導入、実際にどんな利点がある? 壊さず進める大規模コード改善の実践知


