![]()
最新記事公開時にプッシュ通知します
![]()
離れたところから自分の3Dアバターを自由に動かせる手法「D3GA」 ヒラヒラな服や表情も精巧に再現【研究紹介】
2023年11月17日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
Meta Reality Labs Researchやドイツのダルムシュタット工科大学などに所属する研究者らが発表した論文「D3GA – Drivable 3D Gaussian Avatars」は、リアルタイムで人間の3Dアバターの動きを再構築するアプローチを提案した研究報告である。動きに応じて生じる服のヒラヒラする動きや、細かい表情まで再現される。

研究課題
現在の技術では、フォトリアリスティックな人間のイメージを生成するために、多角度からの詳細なデータが不可欠である。複雑な前処理に大きく依存しており、精密な3Dの位置合わせが含まれている。この位置合わせを実施するためには、繰り返し行われるプロセスが必要であり、これを全体の工程に組み込むのは困難である。また、3Dの正確な位置合わせを必要としない「Neural Radiance Field」(NeRF)を基盤とする手法は、リアルタイムでの描画には遅すぎるか、衣服の動きを表現する上で問題を抱えている。
最近の研究において、「3D Gaussian Splatting」(3DGS)が発表された。3DGSは、3D空間におけるデータポイントを滑らかな「斑点」(splat)に変換するための手法である。この手法により、点状のデータが連続的な形状に変換され、物体の形状や表面の細かな特徴がより理解しやすくなる。NeRFよりも高品質な画像を迅速にレンダリングできるが、この技法は静的なシーンに限定されている。
動的なシーンのレンダリングに関して、さらに「時間条件付き3DGS」が提案されているが、これらは過去に観測された内容のみを再現でき、新しい動きを表現するのには適していない。
研究内容
この問題を解決するために、本研究ではNeRFの代わりに3DGSを採用し、3Dの人間の外観と変形を標準空間でモデリングする新しいアプローチである「Drivable 3D Gaussian Avatars」(D3GA)を導入している。この方法は高性能であり、複雑なカメラレイのサンプリングも必要としない。
技術の核心は、3D空間で定義された3DGSを用いることである。簡単に言うと、3D空間にあるガウス分布を2Dの画像平面に映し出して、人間の形や衣服などを表現する。この方法は、よりリアルで細かい描写を可能にする。
D3GAでは、体、顔、衣服などのモデルを四面体のケージでモデル化し、これを変形させることでアバターの動きや表情を表現する。このケージは、多視点イメージからセグメント化されて作成され、3Dガウス分布の効率的かつ正確な変形を可能にする。この方法は、従来の線形ブレンドスキニングに比べて、より自然でリアルな変形を実現する。
D3GAアバターは、初期状態では体のメッシュ表面にサンプリングされたガウス分布で構成される。その後、変形勾配を用いて動的に変形させることができる。これにより、体、顔、衣服などを個別に制御可能な多層の構造が実現される。この変形は、多層パーセプトロンによって制御され、より高度なアニメーションと表現が可能になる。
D3GAのトレーニングプロセスには、複数の損失関数が用いられる。主なものは、推定されたRGBイメージと実際のRGBイメージ間のカラーロスであり、これにより視覚的な忠実度が保証される。さらに、衣服の分離と四面体の形状の規則化を目的とした損失関数が加わる。
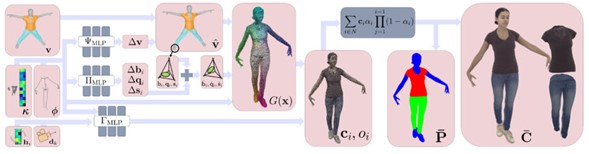
D3GAの性能評価は、複数の基準を用いて行われている。これらには、レンダリングされたアバターの品質、リアルタイム性能、そして他の先進的なアバターモデリング技術との比較が含まれる。評価には、実際の多視点ビデオデータセットを基にした実験が行われている。
結果として、他の最先端の多視点ベースのアバターモデリング技術と比較して、D3GAは動的なシーンや複雑な衣服のモデリングにおいて優れた結果を示している。複数層の衣服を個別に制御することが可能であるため、アバターの表現の柔軟性とリアリズムが大幅に向上している。特に、ゆるい服装の表現において優れていることが確認されている。衣服のドレープや風による動きなど、現実的な服装の動きを再現する能力が高い。

評価
この手法は、従来のアバターモデリングの技術的な制限を克服し、リアルタイムで高品質な人間アバターのレンダリングを可能にするものである。特に、衣服や表情のリアルな動きの再現、複雑な形状の変形への対応力が高い点が特徴的である。この進歩は、ゲーム、映像、VR/AR、テレプレゼンスアプリケーションなどの分野で新しい応用の可能性を開くものである。
Source and Image Credits: Wojciech Zielonka, Timur Bagautdinov, Shunsuke Saito, Michael Zollhöfer, Justus Thies, Javier Romero. Drivable 3D Gaussian Avatars.
関連記事

「顔を少し若返らせて動画配信」 人の若さ具合を自在に変えられる映像編集ツール、Disneyが開発【研究紹介】

3Dシーンの「要らない物」だけを消せる技術「3Dインペインティング」 カナダの研究者などが開発【研究紹介】

Adobe、動画内の人やモノを認識し分離するビデオセグメンテーション機能「DEVA」を発表【研究紹介】
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


