![]()
![]()
Adobe、動画内の人やモノを認識し分離するビデオセグメンテーション機能「DEVA」を発表【研究紹介】
2023年9月12日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
米イリノイ大学アーバナ・シャンペーン校と米Adobe Researchに所属する研究者らが発表した論文「Tracking Anything with Decoupled Video Segmentation」は、動画の中でさまざまな物や人を認識し分離するビデオセグメンテーション技術を提案した研究報告である。この技術は映像が再生されている間も追従し、物や人を分割し続けることができる。この技術のことを「DEVA」と名付けている。

研究背景
ビデオセグメンテーションとは、動画の中の物や人を認識し、再生されても追跡してそれを分ける技術のことである。ビデオセグメンテーションは、ビデオ内のオブジェクトを分割し、関連付けることを目的としている。これはコンピュータビジョンの基本的なタスクで、多くのビデオアプリケーションにとって非常に重要である。
従来の多くのアプローチは、YouTube-VISやCityscape-VPSのような特定のデータセットに特化して学習する方法が主流である。しかし、これらのデータセットがカバーする物体のカテゴリは限定的であり、例えばYouTube-VISは40のカテゴリ、Cityscape-VPSは19のカテゴリしか持っていない。そのため、これらのアプローチが大規模なカテゴリを持つデータや実際のオープンな環境のデータにどれだけ効果的に適応できるかには疑問が存在する。
研究内容
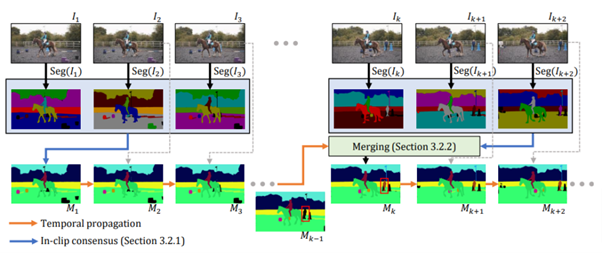
本研究では、これらの制約を克服する新しい手法を提案している。具体的には、ビデオ全体を通じての学習のみに依存するのではなく、静止画における物体分割技術とそれをビデオ全体で時間的に展開する技術を組み合わせる「分離型ビデオセグメンテーション」というアプローチを提案している。
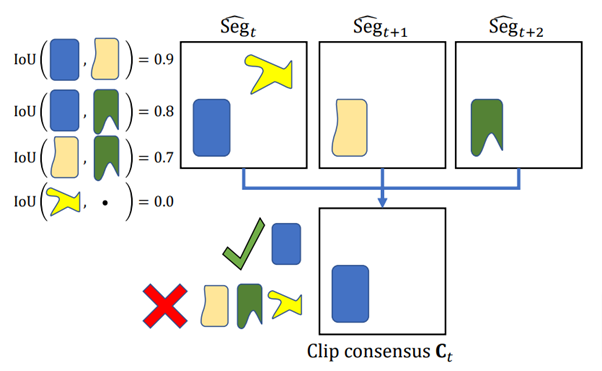
これは、画像内に存在する物体を動画全体で追跡することを意図している。最初の1枚の写真から出発し、その写真に何が映っているのかを特定する。ただし、1枚だけの参照では誤認識の可能性があるため、直後の写真も参照し、正確な物体認識のための方法(in-clip consensus)を採用する。
その後、それを連続的に動く画像(動画)に適用する。新しい物体が動画の中に登場した場合、再度その新しい部分を分析し、以前の結果と統合する。この手法を用いることで、過去の情報と新しい情報の双方を活用することが可能となる。このアプローチを「bi-directional propagation」(双方向伝播)と称している。
この技術によって、画像分割のノイズを除去するとともに、時間的に伝播した分割と静止画の分割を効果的に統合することが可能となる。
このアプローチには、一度学習させたモデルを様々なシチュエーションやタスクに適用できる利点があり、特にビデオデータが不足している場合や新しい大規模なデータセットにも効果を発揮する。また、米MetaのSAMのような既存の画像分割モデルへの組み込みも可能である。
この手法の狙いは、既存のビデオセグメンテーション手法を置き換えることを目的としているわけではない。実際には、充分な動画トレーニングデータを持つ特定の動画タスクに特化したフレームワークの方が、本手法よりも優れた性能を持つ可能性がある。しかし、画像モデルが利用可能である一方で動画データが不足している場合には、本手法が非常に効果的である。
この考え方は、大規模言語モデルのプレトレーニングとその後の特定のタスクへのファインチューニングに類似している。動画内のオブジェクトの動きを予め学習し、それを特定のタスクに応用する。結果として、本手法は大規模な動画データセットや新しい種類の動画データにおいても良好な性能を示し、一部の動画タスクにおいては最先端の結果を達成している。
Source and Image Credits: Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, Joon-Young Lee. Tracking Anything with Decoupled Video Segmentation.
関連記事

映像内のあらゆる動く物体を追跡し分離できるAI「SAM-PT」 点を数か所指定するだけの簡単操作【研究紹介】

生成型AIのネクストステージ。セキュリティが保証された小規模な特化型大規模言語モデルの可能性【テッククランチ】

虫の細い触角も抜き取れる。画像内の物体を超高精度で背景と分離する技術「HQ-SAM」
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


