![]()
![]()
なびく動きがリアルな「デジタルかつら」。フルウィッグ合成システム「NeuWigs」 Meta含む研究者らが開発【研究紹介】
2023年11月14日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
米カーネギーメロン大学や米Reality Labs Research(Meta)などに所属する研究者らが発表した論文「NeuWigs: A Neural Dynamic Model for Volumetric Hair Capture and Animation」は、リアルな髪の動きを再現するための合成モデルを提案した研究報告である。このモデルは、髪の詳細な動きをスムーズにする技術を用いることで、頭部の動きに応じた髪の揺れや飛び出る毛束を自然に見せることができる。

研究課題
人間のアバターを現実に近づけるためには、髪の毛の詳細を高い精度で再現することが鍵となる。なぜなら、髪の毛は個性の一部を表しており、そのリアリズムは形状や見た目だけでなく動きにも関係しているからである。
髪の毛の動きを捉えることは、動きの複雑さや髪同士が互いを隠すことによる困難さから、難しい作業である。また、頭部の動きだけから髪の毛のリアルな動きを作り出すことも同様に困難である。髪の毛の動きには頭の位置だけでなく、重力や慣性の力も大きく影響する。制御技術の観点からも、髪の毛の動きは頭の位置に対して直線的には反応しないため、そのダイナミクスをモデル化するためには単純なシステムでは不十分である。
これらの課題は、リアリスティックな髪のアバター作成において二つの大きな問題を引き起こす。それは、3Dで髪の毛を捉えることと、動きのモデリングである。現代のシステムは、実際の観察から得られた限られたデータを用いて、髪の形状と外見を高い忠実度で再構築するが、新しい動きを生成する問題を直接的に解決するわけではない。それを実現するためには、単に再構築することを超え、捉えたデータを使用して制御可能な動的な髪のモデルを作成する必要がある。
従来のアニメーションにおいては、アーティストが手動で3Dの髪の形状を作り出し、物理シミュレーションを用いて動きを生成している。このプロセスは専門知識を必要とするものである。
一方で、データ駆動型の手法は、髪のキャプチャとアニメーションを自動化し、写真のようなリアリティを維持しながら実現しようとしている。これらの手法は、髪の動きのダイナミクスを直接モデル化することなく、各フレームの信号から直接レンダリングできる密な3Dヘアの表現を学習する。しかし、データ駆動型の手法には、髪のアニメーションにおける実用性に限界がある。これらの手法は、入手が難しい複雑なデータに依存しており、観察した髪のデータに基づいてのみレンダリングが可能であり、新しい髪の動きを生成することは困難である。
研究内容
この研究は、既存のデータ駆動型の髪のキャプチャとアニメーションのアプローチに存在する制約に対処するため、頭の動きと相対的な重力の方向を基にして髪を高忠実度でアニメーションすることができるニューラルダイナミックモデルを提示する。このようなダイナミックモデルを構築することで、フレームごとの髪の観察に依存せず、初期の髪の状態から将来の状態へと髪の動きを進化させることが可能となる。
ダイナミックモデルの構築には二段階のアプローチが用いられている。第一段階では、トラッキングアルゴリズムを使用した多視点ビデオキャプチャから髪のオートエンコーダーを学習し、状態圧縮を行う。この方法では、頭と髪が動いているビデオから、時間的に一貫したレンダリング可能な髪の体積表現を捉えることができる。異なるタイムスタンプを持つ髪の状態は、オートエンコーダーを介して意味のある埋め込み空間にパラメータ化される。
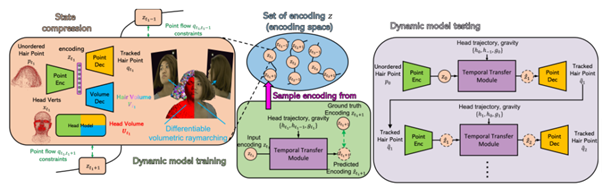
第二段階では、意味のある埋め込み空間から時間的に隣接するペアをサンプリングし、与えられた前の頭の動きと重力の方向に基づいて、埋め込み空間内の各状態間の髪の状態遷移を実行できるダイナミックモデルを学習する。このダイナミックモデルを使用すると、既存の髪の観察に依存しない方法で髪の状態進化とアニメーションを行うことができる。
これらの技術により、地毛をまとめるキャップをつけた動く頭部のシングルビューキャプチャー上(一つの視点から撮影された)で異なる髪型のリアリスティックな髪のアニメーションを生成することが可能となる。

実証実験
提案された髪のアニメーションモデルは、複数の実験を通じてその性能が検証されている。髪と頭の動きをうまく分離する能力についてのテストでは、セグメンテーション技術を用いることで、髪の細部まで詳細に再現できることが確認された。特に、髪のボリュームと非髪部分との間でのテクスチャの混在が少なくなる効果がある。
また、レンダリング品質を改善するための実験では、適度な重みで損失を追加することで、視覚的にも細部がはっきりとした再構築が可能になることが分かった。しかし、重みを大きくしすぎると、その効果が逆転してしまうことも明らかになった。
さらに、別の実験では、ポイントクラウドの最適化を進めることで、髪の動きの不自然な揺れを減らすことが示された。これは、アニメーションがより滑らかで安定した動きを示すことを意味している。
最終的なダイナミックモデルの評価では、モデルがフレームごとの髪の観測データを使用せずに、リアルな髪の動きを生成できることが示された。定量的なテストでは、フレームごとの髪のデータを使用する従来のモデルと比べて優れた結果を出しており、質的な評価では、頭の動きだけから新しい髪のアニメーションを作り出すことに成功している。これらの実験結果から、提案モデルが高い再現性と実用性を有していることが確認された。
Source and Image Credits: Wang, Ziyan, et al. “NeuWigs: A Neural Dynamic Model for Volumetric Hair Capture and Animation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
関連記事

「いらない人やモノ」だけを映像からキレイに消す技術「ProPainter」 シンガポールの研究者らが開発【研究紹介】

「顔を少し若返らせて動画配信」 人の若さ具合を自在に変えられる映像編集ツール、Disneyが開発【研究紹介】

キャラクターの新しい動きを永遠に生成できるモデル「GenMM」テンセント含む研究者らが開発【研究紹介】
人気記事

ワークス同期たちの、今だから話せる「原点」。カミナシCTOとKyash、タイミーVPoEが新卒時代に得たもの、失ったもの

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?


