

LINE株式会社 LINE Platform Data Science Team Data Scientist
大塚 優
2015年にNTTデータに入社。データ活用に関するコンサルティング業務に従事。2019年にLINE株式会社に入社。LINEポイントクラブ、LINEアプリ内のウォレットタブのような複数のサービスにまたがる領域のデータ分析を担当。

LINE株式会社 Machine Learning Solution Team 2 Senior Machine Learning Engineer
渡辺 哲朗
博士(工学)。ゲーム企業やデータ分析受託企業などでの勤務を経て、現在はLINEで、属性推定システムやフィーチャーストアシステムといった全社利用される機械学習システムの開発・運用に従事。チーム内外の利用者の利便性を考慮した開発とPythonが得意。
LINEは、エンジニア向け技術カンファレンス「LINE DEVELOPER DAY 2021」を、2021年11月10日~11日の2日間にかけてオンライン開催した。Opening Keynoteでは、取締役CTO 朴イビン(Euivin Park)氏が登壇し、LINEの技術戦略とビジョンを語り、約60の技術セッションでは、LINEが活用する最新技術や開発事例が発表された。今回は、11月10日のイベントからデータ分析と機械学習開発、属性推定システムのリニューアルの事例に関するセッションをご紹介する。
- データ分析と機械学習によるLINEスタンプのレコメンド改善事例 【LINE Data Scientist 大塚 優氏】
- 属性推定システムのリニューアルで見えた課題とその解決法 【LINE Senior Machine Learning Engineer 渡辺 哲朗氏】
データ分析と機械学習によるLINEスタンプのレコメンド改善事例 【LINE Data Scientist 大塚 優氏】
最初に紹介するセッションは、LINEのデータサイエンティスト大塚優氏の「データ分析と機械学習開発の協業によるスタンプ推薦ロジックの継続的改善」。LINEのデータサイエンティストと機械学習エンジニアの役割と関係や、両者がどのようにプロダクトに貢献しているのか。LINEスタンプの推薦ロジック改善の事例をもとに語られた。
データサイエンス・マシンラーニング組織構造とプロダクト改善の流れ
LINEのData Scienceセンターは、データ活用全般を統括する全社横断の組織。その中で Data Science室は、統計解析などのデータ分析によって、事業の重要な意思決定をサポートしている。一方、Machine Learning室は各事業に対して機械学習のソリューションの提供や、機械学習の共通プラットフォームを開発している。
大塚氏はこの二つの組織によるプロダクト改善の流れを、以下の図をもとに説明した。
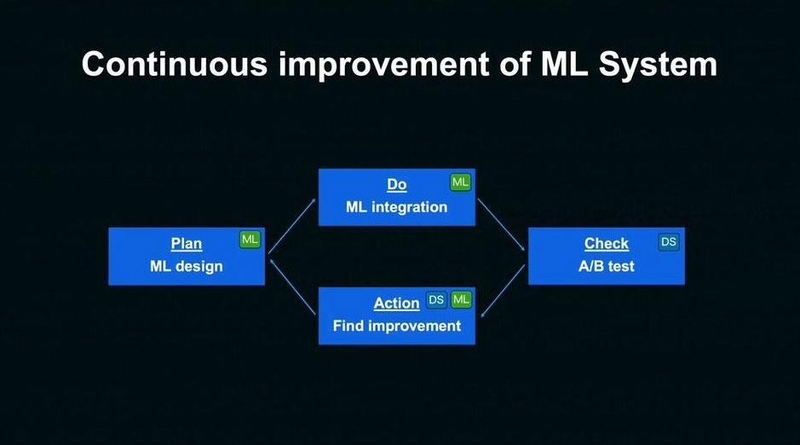 ▲Data Science 室と Machine Learning 室によるプロダクト改善のPDCAサイクル
▲Data Science 室と Machine Learning 室によるプロダクト改善のPDCAサイクル
まず機械学習の設計は、事業サイドの要求を整理し、機械学習で実現することを明確化した上で、目的に合った適切なモデルを検討。開発は、パラメータチューニングや特徴量エンジニアリングを通じてモデルの精度を高め、A/Bテストによってモデル検証を行う。
データサイエンティストはオンラインA/Bテストを通じて、当初の要求を実現できているかについて、定量的な指標に基づき多角的に検証を行っていく。そして、A/Bテストによって得られた知見から、モデルの改善点を見つけ出し、モデル設計をフィードバックする。これらのサイクルを回し続けることで、機械学習の仕組みを継続的に改善している。
LINEスタンプのレコメンドエンジン改善プロジェクト
続いては、具体的な事例として、LINEスタンプのレコメンドエンジン改善プロジェクトが紹介された。
LINEのスタンプショップにアクセスすると、トップ画面に「あなたへのおすすめスタンプ」のリストが表示される。ここにはレコメンドエンジンが活用されており、LINEスタンプ事業において重要な役割を担っている。
トップ画面からの売上の約40%を占め、日次で100万クリック以上の膨大なユーザートラフィック数があり、多くのユーザーのスタンプ購入の接点になっている。
直近では、1000万種類以上のLINEスタンプが販売されており、「レコメンドは必要不可欠な機能である」と大塚氏は言う。
 ▲LINEのユーザーインタフェースの「あなたへのおすすめスタンプ」エリア
▲LINEのユーザーインタフェースの「あなたへのおすすめスタンプ」エリア
この「あなたへのおすすめスタンプ」エリアは長年運用されているが、求められている役割は運用開始時と変わりつつある。LINEのUIが変化しスタンプへの接点が増えたことで、ユーザーはスタンプショップに訪れなくても、LINEアプリを使っているだけでスタンプの情報に触れることができるようになった。
実際のユーザー行動を見てみると、およそ9割のユーザーは、別の購入経路からもスタンプを購入していることがわかる。つまり、ユーザーは複数の接点でスタンプに関する情報に触れているのだ。
「これまでは、ユーザーの嗜好を広く浅くとらえたシンプルなレコメンドが求められていました。しかし、スタンプへの接点が多様化したことで、能動的な姿勢でスタンプを探しているユーザーが増加。今まで以上にユーザーの嗜好を深く捉え、多種多様なスタンプをレコメンドすることが必要となります」(大塚氏)
大塚氏は、キーワードは「レコメンドの多様化」だと強調し、その実現に向けて行った具体的な取り組みを紹介した。
これまでのレコメンドモデルは、特徴量間の従属性を扱わないことで、パラメータ数を抑えたシンプルなイーブベイズモデルを利用していた。レコメンドの多様化を実現するための新たなモデルとして、最初に検討したモデルはグラフニューラルネットワークである。
「ユーザーとアイテムの情報を高次元の特徴ベクトルにすることで、従来のナイーブベイズモデルと比べ、ユーザーの嗜好をより深く捉えることができます」(大塚氏)
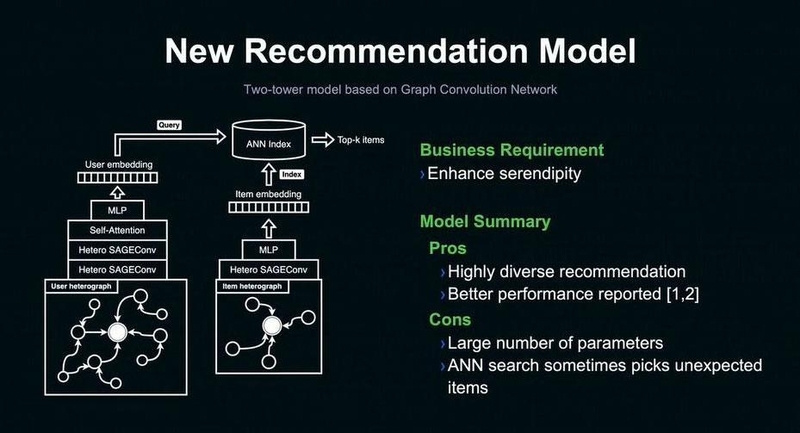 ▲ユーザーの嗜好をより深く捉えた新しいレコメンドモデル
▲ユーザーの嗜好をより深く捉えた新しいレコメンドモデル
データサイエンティストがモデルの検証を行う際は、まずモデルの評価指標を選ぶ。これにはいくつかのパターンが挙げられる。一つ目の指標候補は、レコメンド経由で発生した売上である。A/Bテストにおいてよく使われるものだが、レコメンド以外から発生する売り上げへの影響を見逃してしまう可能性があるため、誤った判断をしてしまう可能性もある。
二つ目の指標の候補は、スタンプショップ全体の売り上げ。漏れがないという点では良いが、レコメンドの多様化が実現できているのかを検証することができないデメリットもある。三つ目の指標の候補は、メジャーなスタンプ、マイナーなスタンプといったアイテム別の売り上げだ。レコメンドの多様化を検証するための指標として適している。
 ▲レコメンドモデルの3つの評価指標候補
▲レコメンドモデルの3つの評価指標候補
それらを検討した結果、現在は全体の売上と、メジャー・マイナーのアイテム別売上の二つの指標を併用して、モデルの検証を行っていると大塚氏は語る。
「このように目的によって適切な評価指標は変わるため、事業のデータを理解しているデータサイエンティストが指標検討することは、モデル検証の重要なプロセスです」(大塚氏)
実際にA/Bテストを行って、モデルを評価したグラフが以下である。中央の青い棒グラフを見ると、狙い通りマイナーなスタンプの売り上げが伸び、レコメンドの多様化が確認できる。同時に全体の売り上げも向上している。
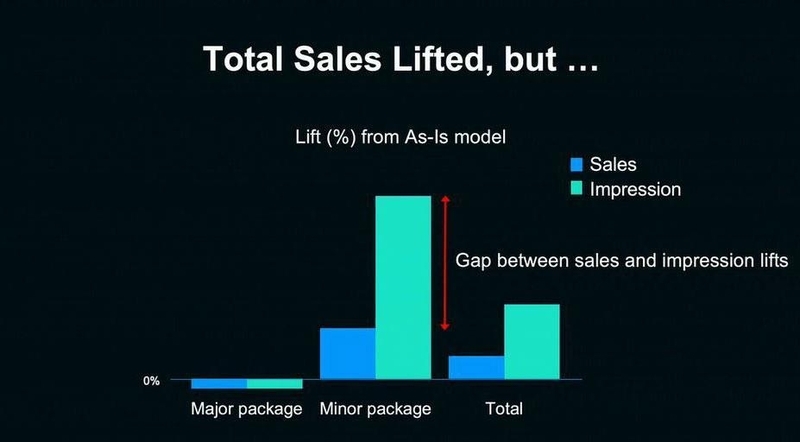 ▲A/Bテストの結果
▲A/Bテストの結果
だが、レコメンドの表示回数(中央の緑の棒グラフ)の変化を見てみると、マイナーなスタンプの表示回数が大きく増加していることがわかる。表示回数が増えた一方で、売り上げに結びついていないのだ。
その原因を探ったところ、スタンプの特徴が過度に抽象化されているのではないかという仮説にたどり着いた。
「例えば、関西弁のスタンプを購入したユーザーに対し、他の地域の方言のスタンプをレコメンドしているケースが見られました。方言という抽象的な意味では似ていますが、実際に両方購入するユーザーは少ないと考えられます」(大塚氏)
そこで、特徴量の抽象化レベルを抑制することで、レコメンドの精度が改善するという仮説をMachine Learning室にフィードバックし、再度モデルの検討を行った。特徴量の抽象化レベルを抑制するために、よりシンプルなネットワーク構造のモデル、「Light Graph Convolution」と呼ばれる畳み込み層を導入したのである。これにより、レイヤー内での特徴量変換が簡素化され、シンプルなネットワーク構造となった。
再びA/Bテストによりモデルの評価を行った結果がこちらである。2番目のモデルでは、マイナーなスタンプの売り上げがさらに改善。売り上げとレコメンド表示回数の増加率のギャップが小さくなり、レコメンドの精度はより向上している。さらに、全体の売り上げの増加率も約2倍に改善する結果が得られた。
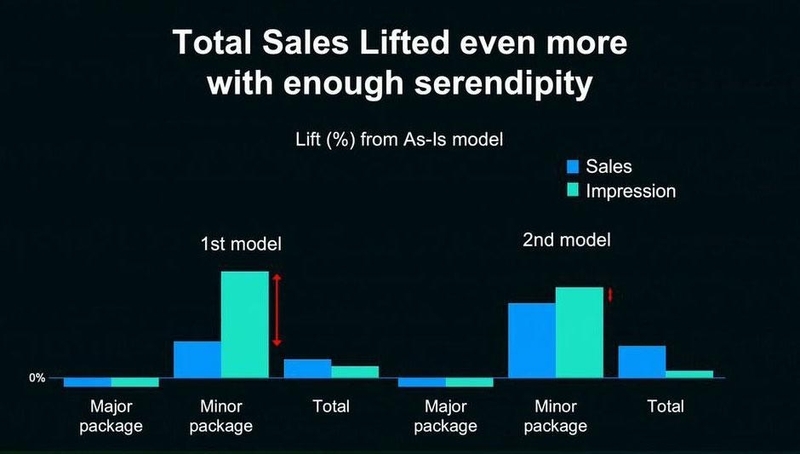 ▲左右のグラフで2回の評価結果を比較してみると、売上の改善は明確にわかる
▲左右のグラフで2回の評価結果を比較してみると、売上の改善は明確にわかる
「このようにLINEでは、機械学習エンジニアが高度な技術に基づいて開発したモデルを、データサイエンティストが事業全体の視点から検証し、改善点をフィードバックする。これらのサイクルを繰り返すことで、継続的にプロダクトの改善を進めています」
最後に大塚氏はこうまとめ、セッションを締めくくった。
属性推定システムのリニューアルで見えた課題とその解決法 【LINE Senior Machine Learning Engineer 渡辺 哲朗氏】
続いて紹介するのは、機械学習エンジニアとしてLINEユーザー属性の推定をするシステムの開発や、フィーチャーストアシステムの開発・運用に携わっている渡辺哲朗氏のセッション。今回は「属性推定システムのリニューアルで見えた様々な課題と、その解決の事例紹介」と題した発表を行った。
LINEのユーザー属性推定システムと取り組み
渡辺氏が属するMachine Learning室が推定するユーザー属性とは、性別・年齢層といったデモグラフィック属性だけではなく、興味関心などの心理的な属性も含む。許諾を得たユーザーのサービスログを用いて、機械学習の手法によって推定され、LINEの様々なサービスで活用されている。
LINE広告では、外部の広告主がどのようなユーザーに広告を届けたいか、その配信ターゲットを推定属性で指定することができる。例えばLINE公式アカウントでは、アカウントのオーナーとなる企業や店舗が、複数のユーザーに向けてプッシュメッセージを送る際に、ターゲットを指定してメッセージを一斉配信することができる。
こうした機能によって、アカウントのオーナーは適切なユーザーにコンテンツを届けることができ、ユーザーも自分に合う情報を得る可能性が高まるというわけだ。
一般的に新しいサービスをスタートする際は、ログデータの蓄積量は非常に限られていることが多い。アイテムをおすすめしたくても、十分なログデータがないため、適切なレコメンドを生成できない。いわゆる「コールドスタート問題」だ。
しかし、LINEにはこの推定属性のユーザーデモグラフィックスデータがあるので、新しいサービスでもユーザーの属性を推定して、適したアイテムをおすすめすることが可能となる。LINEの属性推定システムの強みと言えるだろう。
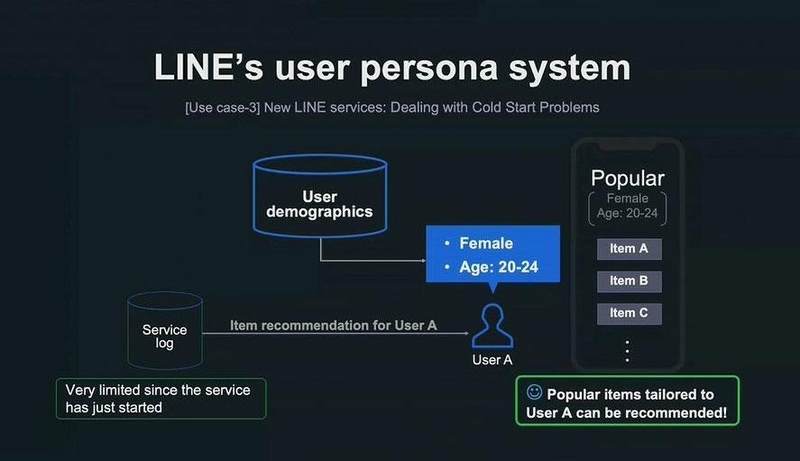 ▲LINEのユーザー属性推定システムの仕組み
▲LINEのユーザー属性推定システムの仕組み
この属性推定システムは、LINEの主要なリージョンを対象に推定属性を提供しており、日本では月間アクティブユーザーは約8900万人(2021年9月時点)。機械学習に用いる特徴量データの次元数は480万以上と、非常に規模の大きいシステムとなっている。
推定属性システムのコアとなる、機械学習に利用されるデータについても説明が行われた。以下の図は、LINEが開発・運用するフィーチャーストアについて、その生成の仕組みを図式化したもの。主に緑色の囲まれた「z-features」と呼ばれるサービスは、横断型の特徴例データを利用している。
許諾を得たユーザーのサービスログだけを抽出し、フィルタリング処理を施した上で、利用が許可されているデータだけをサービス横断で収集。それらを統合してフィーチャーストアとして格納した特徴量データが「z-features」である。「z-features」を利用することで、属性推定システムの機械学習モデルは学習と推論を実施する。
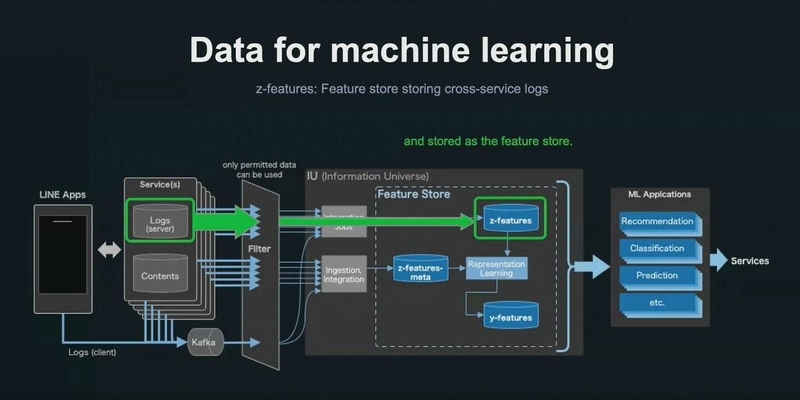 ▲LINEが運用開発する機械学習のフィーチャーストアが生成される仕組み
▲LINEが運用開発する機械学習のフィーチャーストアが生成される仕組み
この特徴量データとともに、モデル学習時に必要となる正解データを用意すべく、さらに別のモデルを開発した事例もあると渡辺氏は解説を続ける。
「人手でラベル付けし、アノテーションされた少量の広告のデータから、自動でラベル付けするモデルを開発しました。その広告を閲覧したユーザーを正解データとする方法です」(渡辺氏)
例えば、広告に「ゲーム」というラベルが人手で付けられたとする。付与されたラベルを正解データとして、広告の画像データとテキストデータからその広告のジャンルを予測する、広告用の機械学習モデルを学習する。
この学習された広告用のモデルを使って、自動でジャンルを推定してラベルを付与する。この広告をクリック(タップ)したユーザーはゲームに興味関心があるユーザーだとして、「ゲームに興味あり」というラベルが付与されるという仕組みだ。
そして、今度は個々のユーザーに与えられたラベルを正解データとして、先ほどのフィーチャーデータ、z-featuresと合わせて、ユーザーの興味関心を推定。ユーザー用の機械学習モデルを2段階目として学習することで、自動で属性推定することができる。
こうした仕組みによって、ユーザーアンケートを行わなくても、広告のクリックデータを正解データとして、ユーザーの属性を推定することが可能となる。
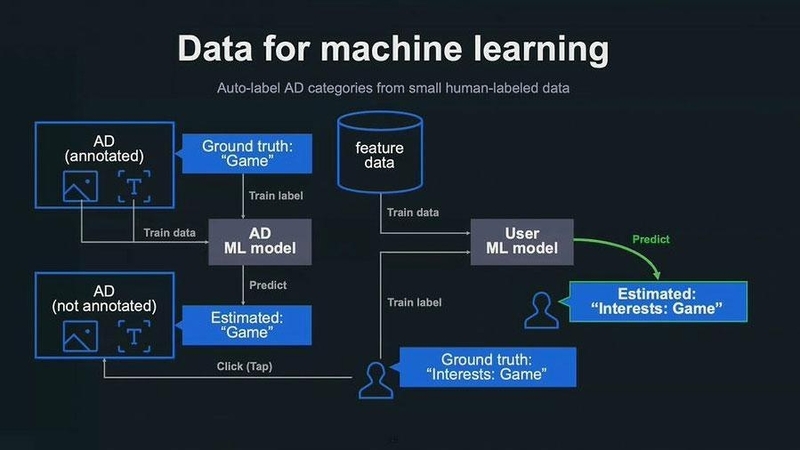 ▲アノテーションされた少量の広告のデータから、自動でラベル付けするモデルの仕組み
▲アノテーションされた少量の広告のデータから、自動でラベル付けするモデルの仕組み
LINEの属性推定システムは、2014年にニューラルネットワークのコードをスクラッチで実装するところからスタートした。大規模なデータをシステムとして扱うために、MPIによる並列処理の仕組みや、本格的な深層学習や分散処理の仕組みが導入された。
2016年にCPUで計算をするMesos clusterとTheanoをベースにして稼働していたが、時間の経過とともに、システムが古くなり、メンテナンスが難しくなるという課題が出てきた。さらに、PyTorchなどのライブラリが適用できないなど、モデルの更新ができないという問題も発生。2020年から大規模なリニューアルが実施されることになった。
リニューアルはまずGPUのクラスターを導入してGPUを使えるようにし、Mesos clusterをKubernetes clusterに移行。こうした環境をさらに最大限に活用するために、gheeと呼ばれる分散処理が可能な内製ライブラリを新たに開発して導入した。
「この大規模なリニューアルを通じて、属性推定システムの様々な改善ポイントが見えてきました」(渡辺氏)
どのような改善ポイントが見えてきたのか。次の章では、いくつかの事例を紹介していく。
改善ポイントは大きく三つに分類される。一つ目は、機械学習モデルのさらなる改善、二つ目は、推定属性の安定供給とモニタリングのためのシステム構築。そして三つ目は、データとモデルの再利用性のさらなる向上だ。
1.機械学習モデルのさらなる改善
リニューアル当初は、以下の図に示したシンプルなディープニューラルネットワーク(DNN)をモデルとして採用。サービス横断で収集された特徴量データを一つのEmbedding レイヤーに投入し、Embeddingレイヤーを一括してモデルに投入するスタイルだった。
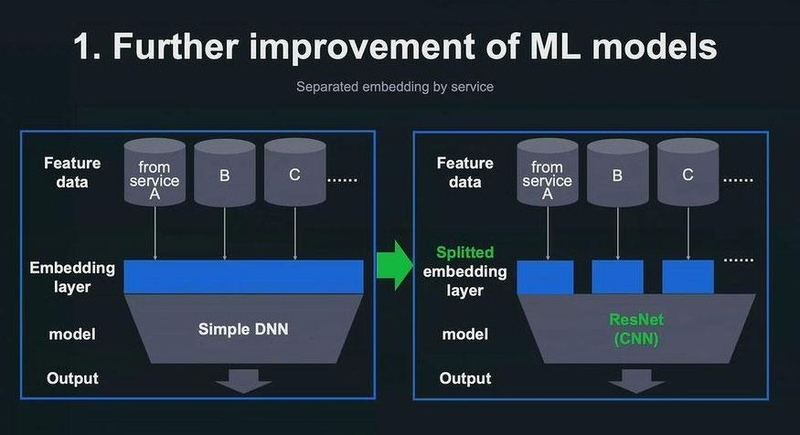
それを、右の図のようなモデル構造への改良を実施。一つのレイヤーで一括して行っていたEmbedding処理を、特徴量データのもととなったサービスの種類別に処理できるように、Embeddingレイヤーを分割。ResNetを用いた畳み込みニューラルネットワークに変更した。
さらに、最新手法であるMLP-mixerというモデルを導入し、サービス単位でドロップアウトできるアイディアも取り入れた。こうしたモデル改善の結果、モデル精度を向上させることに成功した。
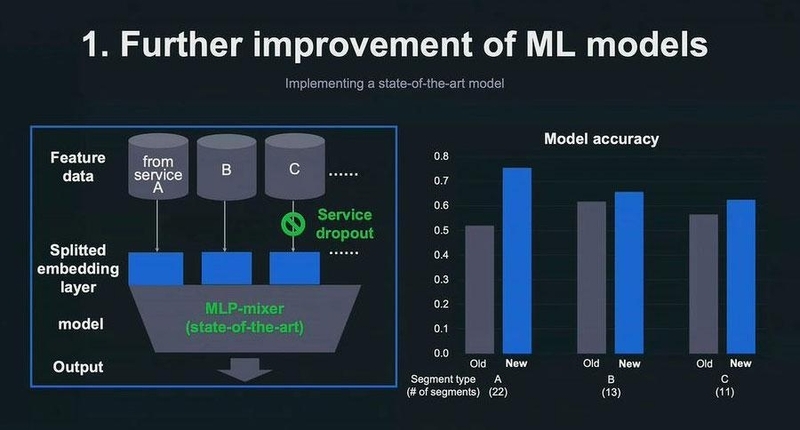
2.推定属性の安定供給とモニタリングのためのシステム構築
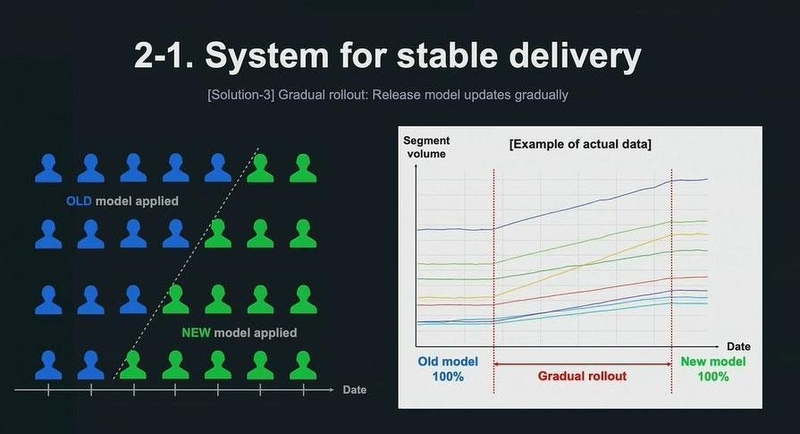
2つ目は、出力されるセグメントのボリューム、つまり属性ごとに推定されたユーザー数の変動が大きくなると、事業側に不便を生じるという課題だ。例えば、以下の図のように、折れ線で示した属性推定ユーザーの人数が、ガクッと減っている日があることがわかる。配信設定を変えていないのに、大幅な配信数の減少が起きてしまうのは、事業にとって不利益が生じる。
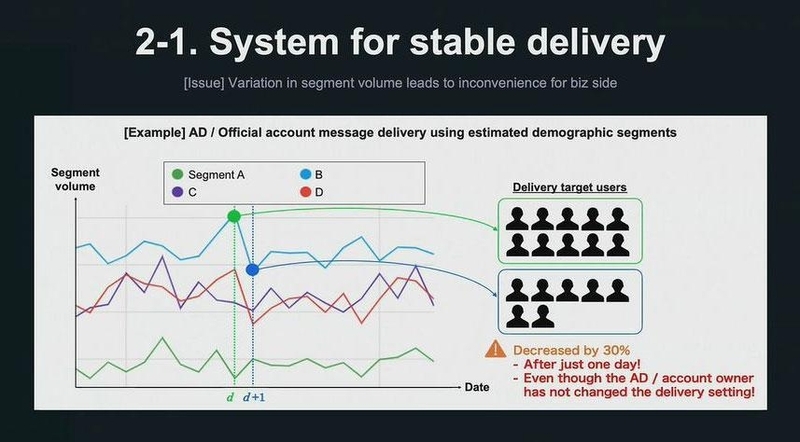
「この解決策の一つ目は、平滑化(スムージング)による日々の変動の抑制です。このスムージング処理をより簡単に行えるように、スムージングAPIを開発しました。面倒なSQLクエリを一切記述することなく、このスムージングの処理を行うことを可能としました」(渡辺氏)
二つ目の改善策は、セグメントボリュームのキャリブレーションによって、大きすぎる変動を抑制したり、一定以上のボリュームが必ず確保したりする処理を施すというもの。例えば、1日ごとに許容されるボリューム変動を前日より±20%までと設定したとすると、それを超える変動が抑制されるように、推定属性が調整される。
先ほどのスムージングと合わせて併用することで、スムージングではカバーしきれない変動が起きてもそれを抑制することができる。さらに、ボリュームが小さくなりすぎて、配信のターゲットがいなくなってしまうことも防止できる。
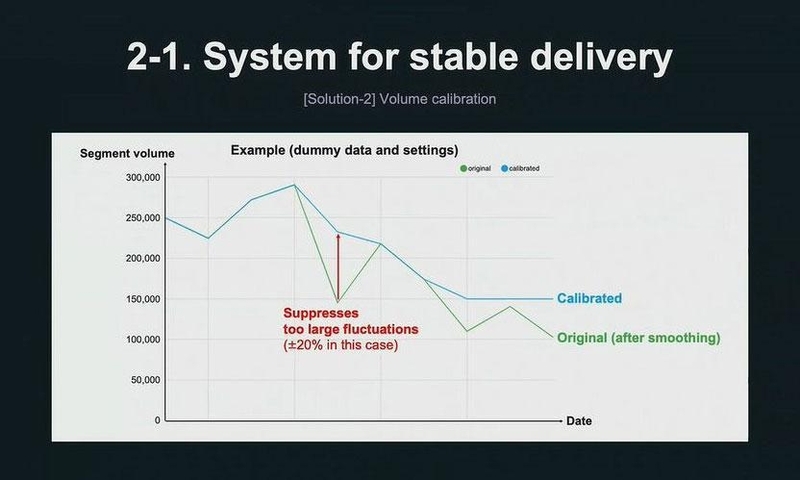
三つ目の解決策は、新しいモデルをリリースする際に、推定属性ユーザーの割合を少しずつ増やしていく「Gradual rollout」という仕組み。この仕組みによって、モデルをリニューアルする際にも、推定属性セグメントボリュームが一気に変動することを防ぐことができる。
LINEでは、この取り組みを社内のダッシュボードツール「OASIS」を駆使して実現している。OASISでは、SQLのクエリを登録することによって、可視化の処理を設定したスケジュールで自動的に実行してくれる仕組みだ。
3.データとモデルの再利用性のさらなる向上
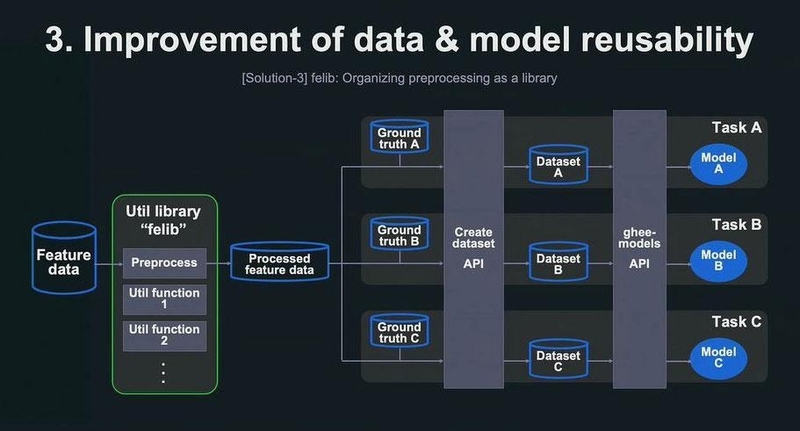
LINEには推定属性の種別に応じて複数のタスクが存在している。しかし、開発時期が異なるなどの理由から、似たような処理なのにバラバラに実装されており、無駄なメンテナンスコストや計算コストがあった。
この課題を解決するために、まず各所で個別に実施していた特徴量データに対する前処理を一元化。次にデータセットを生成する処理はAPI化を行った。そして、モデルの学習推論に関する部分もAPIを共通化し、このAPIを呼び出すだけでモデルの学習推論を実行できる形に統一を行っている。
LINEが独自に開発している機械学習モデルのライブラリ「ghee-models」では、各モデルの学習推論がAPIとしてシンプルに呼び出して利用できるように整備を進めている。このghee-modelsAPIを本格的に今回導入したことで、データとモデルの再利用性をさらに高めることができた。
特徴量データに対する前処理の部分は「felib」というライブラリにまとめ、特徴量データの前処理を容易に行うことが可能になった。また、機械学習モデルを集めたライブラリ「ghee-models」でも、学習前の前処理や推論後の後処理を統合し、より機動的に迅速にモデルの検証や更新を可能にしていくという。
最後に、Auto-persona(オートペルソナ)と呼ばれる計画が発表された。「サービスに特化したオリジナルの属性推定を可能にするためのプラン」と、渡辺氏は明かす。
さらに、「今後もLINEのユーザーにより有用なコンテンツを届けるために、属性推定システムを活用していきたい」と決意を語り、セッションを締めくくった。
文:馬場 美由紀


