![]()
![]()
【DeNA TechCon 2021 Autumn】ヘルスケア、データ分析基盤の効率化、機械学習の活用、データ品質向上、システム開発グループの取り組みをご紹介【イベントレポート】
2021年11月9日


福島 誠大
2019年にDeNAへ中途入社。前職からソーシャルゲームのサーバサイド開発を行いながら、エンジニアのマネジメントに注力してきた。2020年10月にヘルスケア事業部に異動し、ヘルスケアアプリ「kencom」の開発エンジニアマネージャーを務めている。

内嶋 慶
2021年2月にDeNAヘルスケア事業本部に中途入社。前職ではエンタメから決済システムまで幅広く携わるフルスタックエンジニアとして活躍、テクニカルディレクターも兼任。現在はヘルスビッグデータのインフラ構築およびデータパイプラインのアーキテクト・開発を担当している。

加納 龍一
2018年にデータサイエンティストとして入社。タクシー配車アプリMOVやGOに携わり、交通移動体データの解析や、それらを活用した機械学習システムの社会実装を行ったのち、 現在は「Pococha」のプラットフォーム健全化に取り組んでいる。

野本 大貴
2019年にデータエンジニアとして入社。前職では精密機器メーカーにて制御系エンジニアとして技術・製品開発を担当。入社後はゲーム事業のデータ分析基盤のクラウド移行を経験。現在はデータパイプラインの開発・運用に従事し、データ利用者がより快適にデータ分析できることを目指してデータ品質の向上に取り組んでいる。

小山 達也
2021年5月に中途入社。前職では会計システムを開発する会社でWeb系システムのアーキテクチャ設計やフレームワーク、共通ライブラリの開発を担当した。入社後は会計業務を効率化する社内システム「Rome」の開発を担当。開発工程やチームビルディングにも興味があり、2021年7月からRome開発チームのスクラムマスターを担っている。
最新のテックカンファレンス現場をレポートする本シリーズ。2021年9月29日、DeNAはオンラインで「DeNA TechCon」を開催した。急成長を続けている同社は、様々な分野においてサービス向上のための取り組みを進めている。第2部では5つのテーマ、ヘルスケア事業におけるシステム改善に向けての取り組み、ビッグデータ分析基盤の効率化、アプリ規約違反検知のための機械学習活用、データ品質の向上、システム開発グループにおけるスクラムの導入について順次解説する。
※本稿は第2部のセッション内容です。第1部はこちら。
- kencomにおけるヘルスケアへの取り組みとシステム改善のご紹介【福島 誠大氏登壇】
- ヘルスビッグデータ分析基盤のデータパイプラインの効率化【内嶋 慶氏登壇】
- Pocochaにおける規約違反検知のための機械学習の活用【加納 龍一氏登壇】
- DeNAデータプラットフォームにおけるデータ品質への取組み【野本 大貴氏登壇】
- toBのWebエンジニアからDeNAのコーポレートエンジニアへ【小山 達也氏登壇】
kencomにおけるヘルスケアへの取り組みとシステム改善のご紹介【福島 誠大氏登壇】
DeSCヘルスケア株式会社では、ヘルスケアエンターテインメントアプリ「kencom」を提供している。福島氏は本セッションで「kencom」における社会課題解決のためのデータ活用の取り組みと、データ分析環境をオンプレミスからクラウドへ移行した際に発生した問題やその解決法について紹介した。
ヘルスケア系のアプリというと、一般的にはウェアラブルデバイスと連携して運動履歴を記録したり、ユーザーのバイタルを記録したりするなど、ライフログをグラフ表示するものが多い。こういった機能に加えて「kencom」は、健康保険組合や地方自治体と連携してユーザーの健康診断結果や医薬品の処方履歴の表示、エンタメコンテンツの提供など、より多様化した機能が備え付けられている。
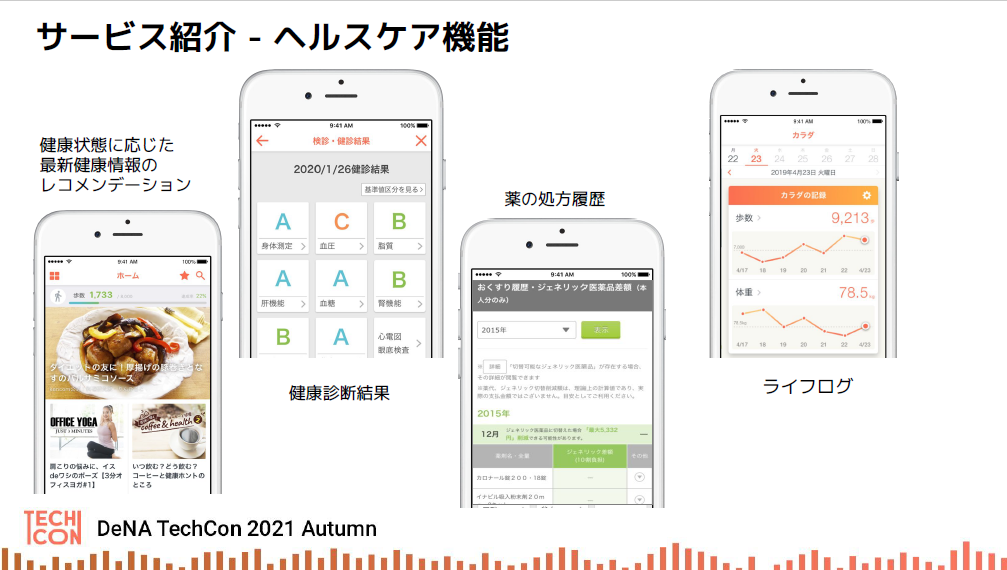
さらに、「kencom」では、ユーザーの検診結果や処方履歴などのビッグデータを分析し、健康増進や疾病の予防に活用する「データヘルス事業」も展開している。取り扱うデータはライフログデータ(歩数、体重など)、健康診断のデータ(身体機能の変化数値)、レセプトデータ(診療報酬明細書など)と幅広い。これらのデータを活かして、一般ユーザー向けにはカスタマイズしたコンテンツをレコメンドし、保健機関向けには医療費効果分析など多種多様なレポートを提供している。また提携している研究機関や民間企業には、二次利用許諾を得たデータを匿名加工のうえ提供することで、社会全体のヘルスケア向上に寄与している。
DeNAでは、昨年全社的なクラウド移行が行われた。「kencom」もデータ分析基盤をオンプレミスで運用していたところ、GCPをベースとしたクラウド環境へと全面移行した。
ヘルスケア事業ではユーザーの個人データを扱うため、独自のセキュリティガイドラインを制定している。健康保険組合や自治体などの顧客からも個人情報の提供に関しては厳しくチェックされている。そこで、クラウド移行に伴い大きな課題となったのは「(クラウドプロバイダであり、データ保管場所でもある)Googleがkencomコンテンツにアクセスされないことを担保する」ことであった。
一般的にはGCPはユーザーデータにアクセスすることはないものの、障害発生などでGoogle側にサポートを依頼する時にはサポートエンジニアがユーザーデータにアクセスする可能性がある。アクセスされた際のログも残らないため、いつ、どんな情報がアクセスされたのかを確認することは不可能になっている。
この課題を解決するために、「kencom」では、GCPの「Access Approval」といった機能を活用している。これを有効化することで、Google側がユーザーデータにアクセスしようとする時に、ユーザーからの明示的な承認が必須となり、アクセス時にログも残るようになる。この取り組みを通して、Google側が無断でユーザーデータにアクセスすることがないと担保(証明)されている。
このように、課題はあるものの、クラウド移行に伴い旧環境(オンプレ)で抱えていた課題もいくつか解決できた。「kencom」では顧客ごとに独自の分析レポートを提供しており、管理しているレポートの種類が多数ある。サービス立ち上げの初期は、アプリケーション開発がサービスの成長速度に追いつかず、分析基盤の責務が増え要件を満たすための変換や中間集計処理が分散している状態だった。それによって中間テーブルの生成フローが不明瞭で似たテーブルが乱立するなどの課題が増え、クエリ調査のコストが肥大化し、集計ミスが起きるリスクも高まっていた。
GCP移行後は中間処理を一本化して変換や修正を最小限にして、分析ログや中間集計テーブルを分析要件に合わせて再定義した。また、これまで分散していた処理基盤をGCP上にまとめることで、明瞭なデータフローを実現し、アプリケーションの変更への対応や障害発生時の原因調査がしやすくなった。ほかにも、GCPのIAMやGoogle Groupを併用することで権限管理も容易になった。
福島氏は「高いセキュリティ要件を実現するために、今も様々な対策を施しているところだ」と話し、「アプリ以外にもデータを活用したデータヘルスの取り組みを進めており、これらはアプリユーザーやクライアントだけではなく社会全体へも幅広く還元されています」とヘルスケア事業を行う意義について語った。
セッション動画
ヘルスビッグデータ分析基盤のデータパイプラインの効率化【内嶋 慶氏登壇】
DeNAのヘルスケアのミッションは「シックケアからヘルスケアへの転換を実現し、健康寿命を延伸すること」。そのために同社は、ヘルスケアに関係するデータを集約しヘルスビックデータとして統合、活用、提供することに挑戦している。
内嶋氏はこのセッションで、ヘルスケアに関するデータ分析基盤にフォーカスし、ワークフロー自動化やインフラ運用効率化のために活用している技術を解説した。
DeNAのヘルスケア事業は研究機関や製薬会社等と連携して、健康寿命の延伸へとつながる研究活動を支援するために、サービスに集まるヘルスケア関連の各種データを提供している。
しかし、収集したデータをそのまま渡すだけでは分析や研究に使えない。元データを均一のフォーマットに整え、ユーザーの個人情報に対して厳格な匿名加工を施す必要がある。傷病や製薬のマスターが変更されたら即対応することや、データが正しく取り込めているか常にクオリティチェックすることも求められている。データを納品先に安全かつ正確に届けるためにやることは膨大にある。
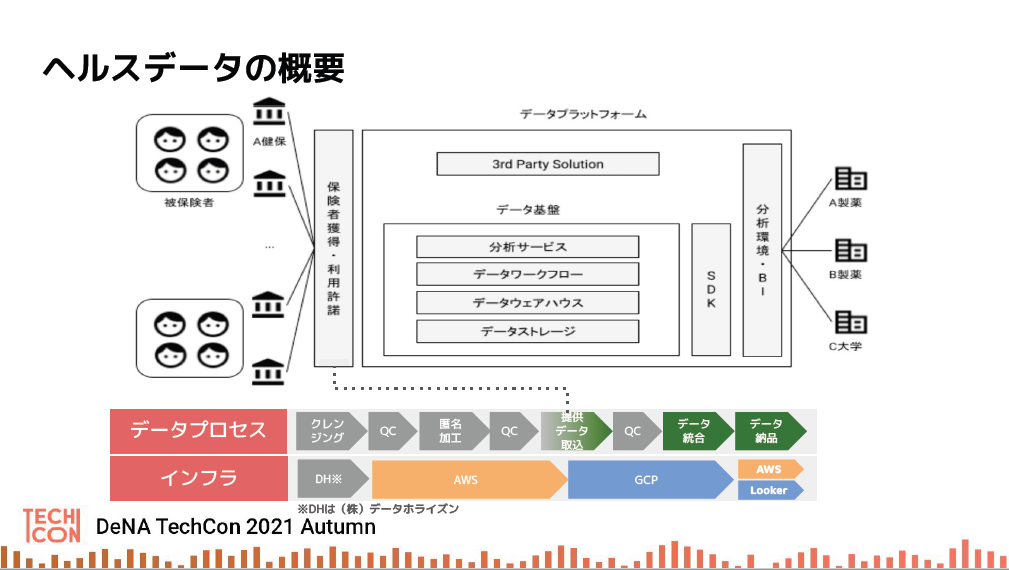
さらに、取り扱うデータは健康保健の被保険者台帳、レセプト、検診問診、kencomからのライフログやアンケートなど、提供者(保険組合や自治体など)ごとに40種類ほどある。このような膨大な規模のデータを取り込む作業は、基本月次で行う。
そこで、運用を効率化するために、ワークフローはAirflowを用いて自動化することにした。さらに、運用の省力化のために、フルマネージドサービスの、Cloud Composerを採用した。実際の運用では、データの取り込みに失敗することもある。取り込みの成否を即時に把握するために、Airflowのタスクを細分化し、トレースのしやすさと処理の並立化に役立てた。
Cloud Composerとは、GCPにおいてフルマネージドでApache Airflowを利用できるサービスで、ワークフローの作成、スケジューリング、モニタリング、管理などを支援している。内嶋氏は「Cloud Composerのフルマネージド機能のおかげで、ログの確認や環境のヘルスチェックがタイムリーに行うことができてワークフローの開発に専念することができました。これからデータやワークフローが増えてもやっていけそうです」と語る。
ワークフローの開発について内嶋氏は以下のポイントを解説した。まずソースコードの構成について、AirflowのDAGファイル(タスク)は同じディレクトリで管理されるため、ソースコードも1ヶ所で管理することが望まれる。チームが複数ある場合は「データレイク(ソース)、データウエアハウス(インテグレーション)およびデータマート(ビジネスモデル)の各レイヤーごとのデータプロセスとレポジトリの関係性のルールを設けるべきだ」と内嶋氏。チーム間でデータプロセスを言語化しておくことで視認性が高まり、開発や障害対応などが効率的になる。
次にマスター構成。マスターとは提供データの種別などを管理するもので、データバージョンマスター、保険番号マスター、保険者テーブルマスターから構成される。マスターはスプレッドシートで管理し、BigQueryと連携している。Airflowでは、1タスク1CPUで実行するため、できるだけタスクを細分化したほうが効率的であり、トレーサビリティやリカバリー効率の向上にもつながる。
続いてDAGファイル(タスク)。実際の運用ではデータを取り込む処理でイレギュラーが発生することもある。例えば、月次のデータ取り込みで普段は1月分のデータを取り込んでいるが、イレギュラーで2ヶ月分取り込むといった事がある。そういった場合、ソースファイルを個別に作成するのではなく、Python global variablesを用いることで、1個のDAGファイルで同じ処理だが、月などの条件を変えて複数プロセスに分けることができる。また、1つのタスクで1つの処理をさせることが開発・運用の効率向上につながるため。Dagのタスク間で変数を受け渡したい場合など、workerが分散されるためメモリ空間が共有されないがXcoms(cross-communications)というメカニズムを取り入れて、タスク間でデータが相互にやりとりできるようにしている
セッションの最後で内嶋氏はインフラ運用の効率化についてTerraformを用いた取り組みを紹介した。Terraformではクラウド上のインフラ環境をコードで宣言し、動的にプロビジョニング、更新、破棄を管理できる。コードはgitで管理され、インフラ環境のバージョン管理も可能。ユーザーリストやアクセス権限の管理を確実かつ効率的に行うには最適と判断している。
「データビジネスにおいて、ナレッジの集約、品質の標準化、継続的な改善が極めて重要です。DevOpsな文化やプラクティスを取り入れ、ソフトウェアで問題を解決していきたいと考えています」(内嶋氏)
セッション動画
Pocochaにおける規約違反検知のための機械学習の活用【加納 龍一氏登壇】
急成長を遂げているライブコミュニケーションアプリ「Pococha」では、プラットフォームとしての健全性を維持するために、規約違反の検知を迅速に行う必要がある。このセッションでは、データサイエンティストの加納氏が機械学習を用いた規約違反検知の手法について紹介した。
「Pococha」の主要機能の一つであるライブ配信機能。動画・音声データ、コメントなどの自然言語データ、ユーザーの行動履歴など、豊富なデータが日々サービスに集まっている。「Pococha」では、こういったデータを活用し、機械学習の手法を用いて規約違反の検知を行っている。
「Pococha」の利用規約では、危険行動(運転中の配信など)、配信者への誹謗中傷や脅迫、出会い目的の利用などを禁止しており、治安維持のために規約違反を迅速に検知して警告やBANなどの対応を行う必要がある。
近頃サービスの成長に伴い配信数は増加し、海外展開が始まったことで監視対象となる言語の多様化が進み、人の力だけでは対応が難しい。そこで監視システムでは、自動チェック+人間チェックという「Human-in-the-loop」の構成を取り入れている。まずは機械学習で規約違反と疑われる配信を検出次第優先度つきキューに入れ、それに対して人間がチェックする。人間の判定結果をフィードバックすることでより精度の高い機械学習モデルを訓練していく構造になっている。
違反検知でキーとなるアクションは事前の予防と発生後の対応だ。事前予防で重要なのは見回り頻度の調整だ。配信量が膨大なため、全配信を均等に巡回するのでは効率が悪い。過去配信履歴や配信状況から違反を起こす確率をユーザーごとに分析し、そこから配信開始から間もないユーザーのほうが、配信回数の多いユーザーより規約違反の可能性が高いことがわかった。そのため、配信回数の少ないユーザーを配信開始から重点的に監視することで違反の発生から対応までに要する時間を大幅に短縮できた。
予防も重要だが、実際に違反が発生しているものに対しては迅速な確認と対応が求められる。「Pococha」では動画から画像を切り出し、その画像を画像・動画分析サービス「Amazon Rekognition」にポストすることで、健全性スコアを算出し、違反を早期に検出できるようにしている。
なお車を運転しながらの配信など、ライブ配信ならではの違反に対しては、独自モデルを作成している。配信動画を学習用データとして入力し、どのようなカテゴリで違反を受けたか学習している。
ただし、独自モデルの開発にも多くの課題がある。実際に規約違反が起きている配信は全体のなかでは極一部であるため、少量なサンプルを正確に抽出できているかきちんと評価する必要がある。データセットがあまりに巨大で愚直に実験していると時間がかかりすぎることもある。そこでGPUを使用するGKEクラスターを独自に運用したり、ダウンサンプリングなどの手法でデータを前処理したりすることで効率化を図っている。
さらに、人間の目では検出が難しいNG例もあることがわかっている。新しくAI判定のモデルを導入する際に、既存判定結果との比較を行っているが、既存ではOKになっているものの、AI判定ではNGとなるケースがある。その場合、改めて人間判定をすると、NGと認められることも多い。人間の判定では見逃してしまったものの、AIは見逃さずに違反を検出できたのだ。これに関して加納氏は「クリーンなデータセットを作るためには、泥臭くデータを眺め、監視チームと連携することが重要」と言う。
これまでは配信者側の規約違反について取り上げてきたが、視聴者側の違反行為に多いのは、コメントにおける誹謗中傷、個人情報の暴露などだ。これまではワードマッチで違反を検出していたものの、海外展開による多言語化で対応が追いつけなくなっている。
多言語でも柔軟に扱える仕組みをつくるべく、どの言語であろうとも、言葉の意味が同じなら近いベクトルになるように変換することにした。例えば「ようこそ」を意味する「welcome(英語)」も「bienvenue(フランス語)」も似たベクトルになるようにチューニングする。こうして変換後のベクトルを入力して、学習や推論を実施していく。つまりベクトル化で言語の壁を埋めておいてから、「OK」、「誹謗中傷」、「公序良俗違反」などのカテゴリ分類を学習する。
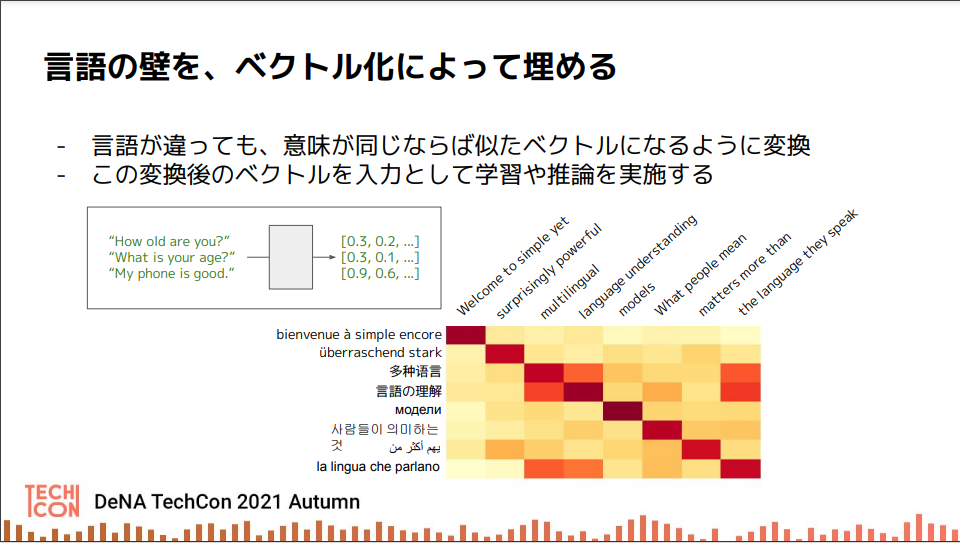
今後、多言語対応の違反検出モデルでは、より幅広いカテゴリで検出できるようにするため、追加データのファインチューニングが不要となるZero–shot Learningの活用を検討している。Zero-shot Learningは機械が見たことのないものを予測するための機械学習の技術の1つで、教師あり学習に比べると精度は劣るが手軽さがある。
加納氏は「今日紹介したものの他にも機械学習分野では様々な取り組みが行われている。これからもHuman in the loopの構成を活用して違反を素早く見つけることで健全なプラットフォームの運用に貢献していきたい」と話した。
セッション動画
DeNAデータプラットフォームにおけるデータ品質への取組み【野本 大貴氏登壇】
DeNAではデータプラットフォームを刷新するクラウド移行を終えた。その過程で、これまでのデータ運用に関する課題を改善すべく、データ品質向上に取り組んだ。野本氏はこのセッションではその取り組みのプロセスやモニタリング方法について解説した。
現在のDeNAのデータプラットフォームはGCP上に構築されており、BigQueryをフル活用し、サービスごとに横展開できる構成になっている。規模としてはプロジェクトが100以上、テーブルは60万以上もある大規模なものだ。
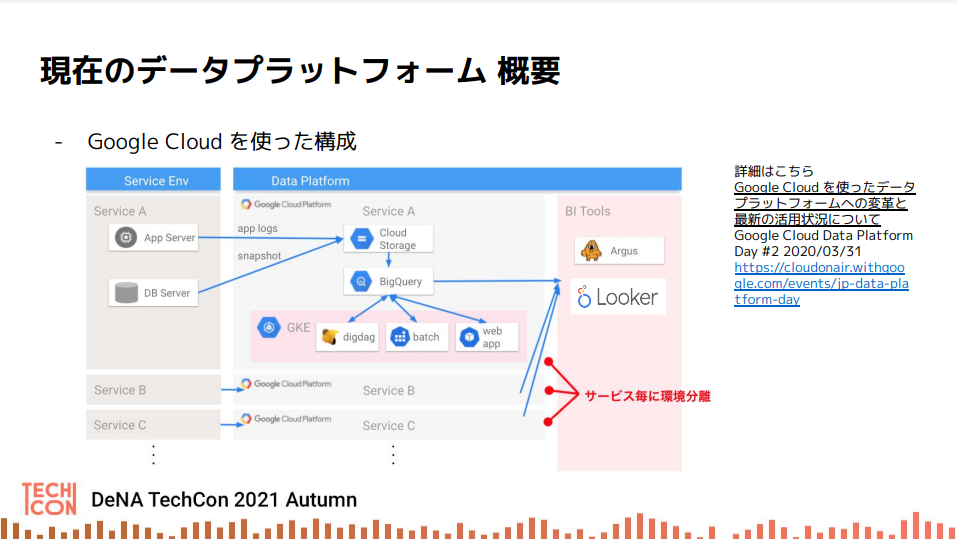
データマネジメントのこれまで取り組みとしては、BigQueryの分析コスト最適化、Lookerを活用したデータの民主化とデータガバナンスの強化などを実施しており、直近ではデータマネジメント知識体系ガイド(DMBOK)への準拠を進めながらデータ品質向上などに取り組んでいる。
データ品質向上に力を入れて取り組んでいる理由は、クラウド移行の過程において、元データの型が変わったことで集計エラーが発生したり、データ件数が異様に増減したり、データ抽出が遅れて次の処理に支障を来したりするなど、データ品質に起因する苦労や混乱が経験したからだ。データの品質が悪ければ、正しくない集計から正しくない意思決定を導き、機会損失や信頼低下など、組織を成功から遠ざけてしまうことにもなりかねない。
そこでデータエンジニアリングチームはデータ品質を向上させ、正しい集計に基づき適切な意思決定ができて、ビジネスを成功に導けるようにすることを目指した。
以下では、実際にデータ品質向上のために行った取り組みをPDCAの順で紹介する。
PLANではゴールである利用者の業務とデータに求められる基準を明確化し、その結果をもとに対象データやその評価軸、目標を設定した。利用者のデータに期待することは暗黙的な場合が多く、「正しいデータ」の基準は明文化しない限り、業務ニーズの変化によっていつの間にか利用者側と提供者側でギャップが生じてしまうこともある。
そういった要件を明確化するために、利用者へのヒアリングやメタデータ分析を通して、どういった業務が重要で、どのデータテーブルを使用し、約束事項(SLA)は何か、違反時の影響範囲は何かを明確にしていった。これをもとに、売り上げといった主要KPIのレポートといった重要な業務・データを優先度高く設定し、計測可能な評価軸・目標を決定するようにした。
続いてDOとしてモニタリングシステムを構築し、対象データの依存関係の把握を行った。上流のデータでモニタリングをする際、データ数が多く依存関係の把握が難しいため、メタデータから依存関係を抽出し可視化を行った。その際、Lookerなどのツールを用いて依存関係を把握し、ダッシュボードでデータ品質維持に重要な項目を可視化できるようにした。Null/重複、データ件数の変動、テーブル間の整合性、遅延の検知などLookerで可視化することでデータエンジニアや利用者がモニタリングをできるようになった。
例えば主キーとなるカラムにNULL/重複があるなどの異常をチェックするために、異常を検出するクエリを作成し、ダッシュボードでその件数を可視化した。データ件数の急増や激減も異常の兆候となるため、データ件数の変動具合もダッシュボードで簡単に視認できるようにしている。
テーブル間の整合性チェックについては、中間テーブルで誤った集計がされていないかを確認している。例えば元データが複数商品の購入履歴で、中間テーブルでは種別ごとにその個数を集計したものとする。その場合、集計前後で総和を比較することで不整合が生じていないかを確認している。
遅延の検知においては、ユーザーにスケジュール通りにデータを届けられているか確認している。一般的に日が経つ(データ量が増える)につれ、更新時間が少しずつ延びてしまう。ストレージの空き容量が徐々に減るように、予定通りに提供するための時間の余裕が少しずつ減っていくのだ。テーブル更新にかかる時間の推移をグラフ化することで、予定していた時間を超過する兆候を把握できるようになり、事前に対策が打てるようになった。
CHECKでは品質レベルの共有と通知を行った。現在は基本的に月次で品質レベルの共有を行っている。例えばターゲット内のテーブルで主キーにNullがあったテーブルや、更新時間が伸びる傾向にあり近いうちに予定時間を超過しそうなテーブルを検知や通知を行った。検知の通知はLookerのアラート機能かBigQueryのAssert関数を用いて、Slackに連携して通知している。
ACTではCHECKで把握できた課題に対して地道に改善を行った。その結果、主キーにNullがあったものはほぼ解消し、更新時間は予定時間を超過する前に対処することができた。
今後はオープンソースのCloud Data Quality EngineやData Validation Toolの活用や各サービスに横展開するなどを検討している。野本は「データ品質向上では利用者の協力体制が重要になります。これからもより便利で安全なデータプラットフォームを目指していきます」と話した。
セッション動画
toBのWebエンジニアからDeNAのコーポレートエンジニアへ【小山 達也氏登壇】
このセッションでは2021年5月からDeNAに入社した小山氏が、配属先となるIT戦略部システム開発グループでスクラムを導入した経緯を紹介している。社内の情報システム部門でWebアプリ開発者に近い体験を創出するためにどのような取り組みを行ったのか。
DeNAではシステム開発を完全に内製しており、インフラやサポートも専門のチームが行っている。組織図上社内情シスと同じ位置づけの「システム開発グループ」は、純粋に社内で必要なシステムを開発する部署だ。対象となるのは約60システムほどあり、全体では8人のメンバーでやりくりしている。小山氏がいるチーム「Rome」は工数管理と経理業務サポートを4人で担当している。

開発体験は「良い意味で、前職のtoB向けWebアプリ開発と同じレベル」と小山氏は言う。例えば、CI/CDにおいては、自動テストのカバレッジは70%を確保しており、GitHubにマージすることで自動的に検証・本番環境にデプロイされる仕組みを構築している。エラー発生時は自動でメールやSlackの通知が届くなど、モニタリング環境も最新鋭だ。
チームにとってのクライアントやユーザーは同じDeNA社員なので「社内業務をより低コストで効率化したい」と利害関係が一致しており、互いに投資効果も考慮して必要なシステムを開発できる。開発対応が完了したらすぐにフィードバックが返ってくるため、ユーザーと一緒にシステムを作りあげる実感がある。また、プロダクトを開発したら終了ではなく、様々なサービスやアプリケーションを組み合わせて全社に最適なシステムをデザインすることで、より上流のシステム設計にも挑戦できる。
ただし課題もある。よりOOP(オブジェクト指向プログラミング)に、よりクラウドネイティブなアーキテクチャへと改善できる余地がある
また、新規メンバーの受け入れ体制が整えておらず、開発環境の構築が複雑で開発手順書がない状態だった。小山氏はまず、開発環境のDockerコンテナ化などを実施し、データベースやバッチ処理をローカルで再現できる環境を構築することで、エンジニアがすぐに開発に参加できるようにした。テストデータに関しても管理を開始し、個人に依存したテストデータの作成を行わず、予め基本的なテストデータを作成し、Dumpしたものを共有するようにした。結果として、開発環境の構築を1時間程度で行えるようになった。
さらに、チーム内では担当システムごとに担当者がいて作業が属人化しており、優先順位が不明確なところも課題として挙げられた。改修したいシステムがあっても、担当者が忙しければ、手の空いた人がいても着手されないままという状態になっていた。
こうした課題を解決するために、小山氏が前職のWebエンジニアとしての経験を生かしてスクラム定着を進めていった。チームにはスクラム経験者がいなかったため、まずはスクラムのフレームワークの理解から始めた。スクラムイベント毎にドキュメントを作成し、そのイベントで各自がどのような役割を担っているか、打ち合わせでは常にそのドキュメントを見ながら進めるようにした。
スクラムを定着するため、小山氏は「チーム意識を醸成し、自己組織化が進むのを根気強く待つことも大事」と説く。メンバーの成長を待てずにリーダーがあれこれ指示してしまうと、リーダーを頂点としたヒエラルキーが形成されてしまい、スクラムの文化にそぐわない。チーム意識の醸成のために、毎日全員でソースレビューをする時間を確保する、レトロスペクティブ(振り返り)でベロシティ向上を本気で議論し続けた。
スクラムを開始した5月から2ヶ月経過した7月にはデイリースクラムを開始し、各自の進捗を全員が把握できるようになった。その後にペアプロ・モブプロを導入し、スプリント毎に最低1タスクの実施をルール化(平均3タスク行われた)。8月にはタスクのアサインを徐々に各自に委ねる状態へと進められた。
そして、スクラム導入から5ヶ月後の現在、部分的な属人化の解消、優先順位の明確化、当事者意識の醸成ができてきたという。
優先順位の明確化に関して、今では優先順位の高いものをチーム全員で取り組む体制ができている。当事者意識については「このシステムは○○さんが担当だから」という「他人ごと」のような認識は消滅し、各自がより効率的にタスクを消化できるようにするために互いに声をかけあえるようになった。
属人化については、複雑なドメイン知識が必要になることもあるため、まだ課題として残るところもある。しかし新規案件なら全員が保守できる状態となった。
小山氏は「DeNAのコーポレートエンジニアは本当の意味でのエンジニア集団です。社内業務効率化のためにユーザーと協力して、自分たちで手を動かしながらシステムで解決します。そしてDeNAでは社歴などによるヒエラルキーが全くなく、合理性があればどんどん改善していけます。DeNAのコーポレートシステムをより良くしていくために、様々な視点を持つエンジニアを募集しています」と話す。
セッション動画
関連リンク
DeNA Engineering
文 : 加山恵美
関連記事

【DeNA TechCon 2021 Autumn】デジタルコレクティブ、世界展開、データベース運用、QCDコントロール。企業成長でつけられた課題にDeNAはどう挑んだのか【イベントレポート】

【DeNA TechCon 2021 Winter】DeNA の MLops エンジニアは何をしているのか。機械学習基盤「Hekatoncheir」を解説【イベントレポート】

【DeNA TechCon 2021 Winter】新卒4人が語り合う。DeNAで活躍する技術スペシャリストなエンジニアの仕事・キャリアとは【イベントレポート】
人気記事

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?

Rubyへの型導入、実際にどんな利点がある? 壊さず進める大規模コード改善の実践知


