![]()
![]()
リアルアバターの動きに応じた「複雑な光の当たり方」をリアルタイム合成 Facebookなどが深層学習フレームワークを開発【研究紹介】
2021年11月26日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
米カリフォルニア大学サンディエゴ校とFacebook Reality Labsの研究チームが開発した「Deep Relightable Appearance Models for Animatable Faces」は、アニメーション可能な3Dアバターに対して、その動きに応じたフォトリアリスティックなリライティング(再照明)を実現する、深層学習フレームワークだ。異なる表情や視点、さまざまな新しい照明環境下でリアルタイムに駆動する。
また、VR HMD(ヘッドマウントディスプレイ) に搭載するカメラで撮影した映像を基に復元した、リアルな装着者の顔へのリライティングにも成功している。

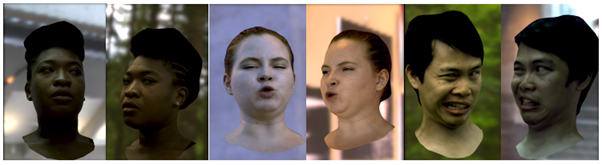

近年、リアルアバターの作成において学習ベースの手法の運用が顕著に増加している。深層学習で一般的な関数近似器を使用して、人間の顔の外観を忠実にモデル化する手法だ。しかし、これまで学習ベースの技術を用いて作成されたアバターは、静的なアバターへのリライティング研究は行われてきたが、動的なアバターへのリライティングは難しかったため、あまり探究されてこなかった。
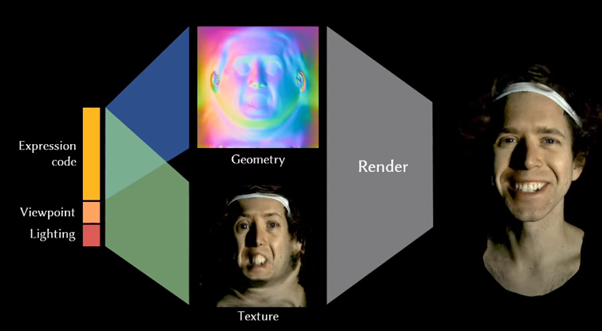
本研究ではこの課題に挑戦するため、リライティング可能な動的な3Dアバターを構築するための学習モデル「DRAM」(Deep Relightable Appearance Models )を提案。このモデルは、アバターの新しい視点や表情のレンダリングをサポートするだけでなく、その動きに応じた複雑な光の当たり具合(鏡面、反射、屈折、吸収、内部散乱など)を復元する。
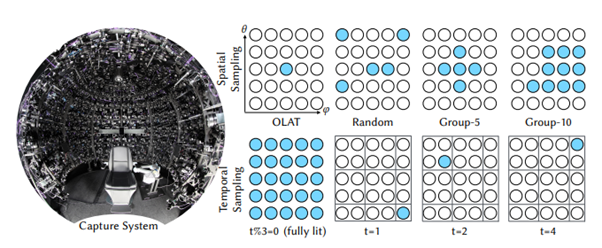
ネットワークでは、顔の表情、視点、照明条件の3つの情報を入力に、対応する形状情報(ジオメトリ)およびテクスチャを変分オートエンコーダー(Variational auto-encoder/VAE)を用いて生成する。このようなネットワークの学習を実現するには、学習用の画像データが大量に必要だ。研究チームは、顔の画像データを取得するために、異なる視点を持つ140台のカラーカメラと460個のLED光源を搭載する球形ドーム型キャプチャーシステム「Light Stage」を活用。Light Stageの中に入った被写体の顔をさまざまな角度と照明条件から効率よく取得する。その際、サイクルタイムが長いOLAT (One-Light-at-A-Time)ではなく、空間的に階層化されたランダムサンプリングを用い、光の方向を時間的にサンプリングしている。
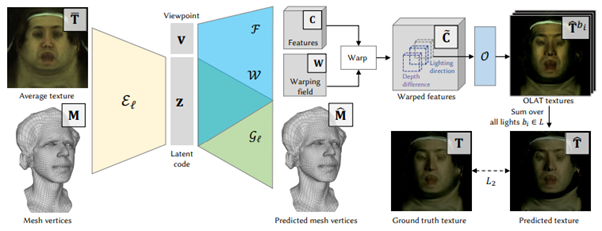
リアルタイム性が求められるVRなどのインタラクティブなアプリケーションに対応するため、ネットワークではTeacher/Student Frameworkを採用している。Teacher Networkで学習データを大量に生成してから、Student Networkを学習する2段階パイプラインで、低い計算コストの維持やオーバーフィッティングを回避しながら、リライティングモデルにおける高品質なリアルタイムレンダリングを実現し、一般的に示す汎化の限界を克服したという。
実験では、グループ化された点光源のキャプチャのみを用いて学習したにもかかわらず、本モデルが、屋内外の自然光、近距離照明、遠距離の指向性照明を含む幅広い照明に対して高いリライティングに成功した。また最先端の類似モデルと比較したテストでも、既存モデルの性能を上回る結果が得られた。一方で、髪の毛などの細部のメッシュでは不正確な部分もあり、今後の課題としている。
VR HMDを装着した状態のユーザーの顔を復元するデモンストレーションでも、HMDに搭載するカメラからの映像を基に顔の表情や視点を忠実に再現すると同時に、新しい照明環境下でのリアルタイムなリライティングを行い、その有効性を強調した。
Source and Image Credits: Sai Bi, Stephen Lombardi, Shunsuke Saito, Tomas Simon, Shih-En Wei, Kevyn McPhail, Ravi Ramamoorthi, Yaser Sheikh, and Jason Saragih, “Deep relightable appearance models for animatable faces” ACM Transactions on Graphics, Volume 40, Issue 4, August 2021, Article No.: 89, pp 1–15, https://doi.org/10.1145/3450626.3459829
関連記事
相手IDやペアリング、外部機器不要。机上のスマートフォン間だけで「その場限り」の無線データ共有を実現【研究紹介】

VR空間に籠もって仕事ができる個室 部屋内で起きる実世界の出来事をリアルタイム再現・後から3D再生可能に【研究紹介】

YouTubeなど動画内の人を3Dモデルで抜き取る技術 米ワシントン大とGoogle Researchが「HumanNeRF」開発【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


