![]()
最新記事公開時にプッシュ通知します
![]()
1枚の写真からTiktokトレンドダンスを躍らせる動画生成AI「DisCo」。Microsoft含む研究者らが開発【研究紹介】
2023年7月28日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
シンガポールの南洋理工大学とMicrosoft Azure AIに所属する研究者らが発表した論文「DISCO: Disentangled Control for Referring Human Dance Generation in Real World」は、1枚の静止画から人物が踊るリアルなビデオを生成する手法を提案した研究報告である。この手法は、TikTokの動画でトレーニングされており、画像内の人物を動かしてTiktok風のダンスを自動生成することができる。
「DisCo」と呼ぶこのモデルは、入力画像を背景、前景、そして人物のポーズという3つの異なる部分に分割することで機能する。これらのコンポーネントを分析し、一連のポーズに変形させ、個々のフレームを作成することで、その結果として人物が踊るリアルな映像が生成される。
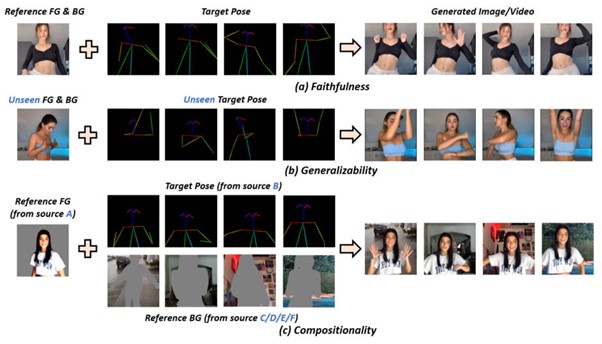

研究背景
人間のダンス合成には長い歴史があるにもかかわらず、既存の手法は、合成されたコンテンツと実世界のダンスシナリオとの間のギャップに大きく悩まされている。GAN(Genera tive Adversarial Network)の時代から、研究者は、ダンスの動きをソースビデオからターゲット人物に転送するために、Video-to-Videoスタイルの転送を拡張してきたが、多くの場合、ターゲット人物の人間特有の微調整を必要とする。
最近では、事前に学習された拡散ベースのモデルを利用して、テキストプロンプトを条件とするダンス動画を生成する研究がある。しかし、このような条件では、制御性の程度が大きく制限され、被写体の動きを正確に指定することは困難である。
画像内の人物ポーズを指定できる「ControlNet」の登場も大きく、導入の価値は高い。しかし、ControlNetはテキストプロンプトに依存しているため、参照画像における人物の外観などの一貫性をどのように確保できるかは不明確なままである。さらに、限られたダンス映像データセットで訓練されたほぼすべての既存の手法は、限られた被写体属性または過度に単純化されたシーンと背景のいずれかに悩まされており、未見の人物、ポーズ、背景の構成に対するゼロショットの汎化性の低さにつながっている。
研究内容
この研究では、実世界で人間のダンスを生成するための新しいアプローチ「DisCo」を提案する。DisCoは2つの主要な設計に基づいている。
まず、1つ目の設計は、分離制御を使った新しいモデルアーキテクチャで、忠実性と構成性を向上させることを目指している。これにより、前景と背景の見た目を参照画像に一致させつつ、正確なポーズを追従させることができる。
次に、2つ目の設計は、より良い汎化性を実現するための効果的な事前学習戦略である。これにより、未知の被写体に対しても前景、背景、ポーズを処理できるようになる。また、さまざまなソースから得られた情報を自由に合成することが可能になる。
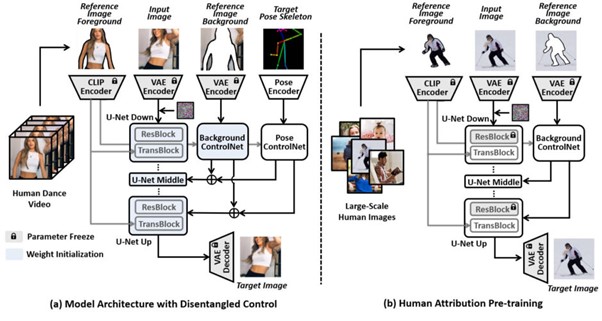
研究チームは、TikTokから取得した約70万枚の一般的な人物画像でDisCoを訓練し、ポーズや前景と背景の分離方法を学習させた。さらに、1本10秒から15秒のTikTokダンス動画約350本からなるデータセットでトレーニングを行い、ダンス中の人の動きについてより深い知識をモデルに与えた。
DisCoの性能を評価するために、既存の類似モデルである「DreamPose」などと比較を行った結果、DisCoは他のどのモデルよりもリアルさの指標で高いスコアを達成し、その有効性が示された。
Source and Image Credits: Wang, Tan, Linjie Li, Kevin Lin, Chung-Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu, and Lijuan Wang. “DISCO: Disentangled Control for Referring Human Dance Generation in Real World.” arXiv preprint arXiv:2307.00040 (2023).
関連記事

Adobeなどの研究者らが開発 「動く落書き」を動画内に溶け込むように描ける編集技術「VideoDoodles」【研究紹介】

映像のみから動けるリアル3Dアバターを作成 服の動きまで精密に再現【研究紹介】

キャラクターの新しい動きを永遠に生成できるモデル「GenMM」テンセント含む研究者らが開発【研究紹介】
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


