![]()
最新記事公開時にプッシュ通知します
![]()
【MIXI TECH CONFERENCE 2023】即座の反応で「生き物感」を演出。会話 AI ロボット「Romi」の設計と技術【イベントレポート】
2023年3月29日


Vantageスタジオ Romi事業部 開発グループ エンジニアリングマネージャー
信田 春満
@halhorn。2013年新卒入社。SNS「mixi」の開発に携わった後、「Romi」の事業開発プロジェクト発足時より参画。現在は開発グループのエンジニアリングマネージャーを務める。
自律型会話AIロボット「Romi(ロミィ)」。2021年4月の発売以来、その「生き物感あふれる」豊かな表現力で人気を博した。
3月1日から3日間にわたり開催された「MIXI TECH CONFERENCE 2023」では、 Romiの開発を主導するエンジニアリングマネージャーの信田氏がその仕組みを解説。ユーザーの話しかけに即座に反応できるその「生き物感」はどうやってつくられたのか。さらに、GPT系など話題の生成型AIをどのように活用していくのか、未来の展望についても紹介。
- 生き物感にこだわった、Romiの仕組みと設計
- Romiに設定した4つのActionで表現をより豊かに
- 会話の内容を考える、会話サーバーアーキテクチャ
- 汎用会話ルールエンジン「Scenario Graph」
- 将来、Romiが記憶を持つようになるかもしれない
生き物感にこだわった、Romiの仕組みと設計
「Romi(ロミィ)」とは「ペットのように癒やし、家族のように自分を理解してくれる」ことをコンセプトに、雑談会話をするために開発された家庭用のコミュニケーションAIロボット。ESP総研の調査により、DeepLearning技術を用いて言語生成して会話する、世界初の家庭用コミュニケーションロボットとして認定されている。
雑談会話ができるロボットを開発する上で重要視されたのは、「ペットのように癒やしてくれる」ロボットに欠かせない「生き物感」だ。
この「生き物感」を表現するため、開発チームはRomiが話かけられた際の反応に着目したという。人間が話しかけてもすぐに反応しないロボットでは、コミュニケーションが取りにくく、話しかけづらい。よくあるロボットのシステム構成として、「Sensor Input」から「Actuator Output」までの動作生成が直列型になっているため、処理時間が長く、ロボットの反応が鈍く見えてしまうのだ。
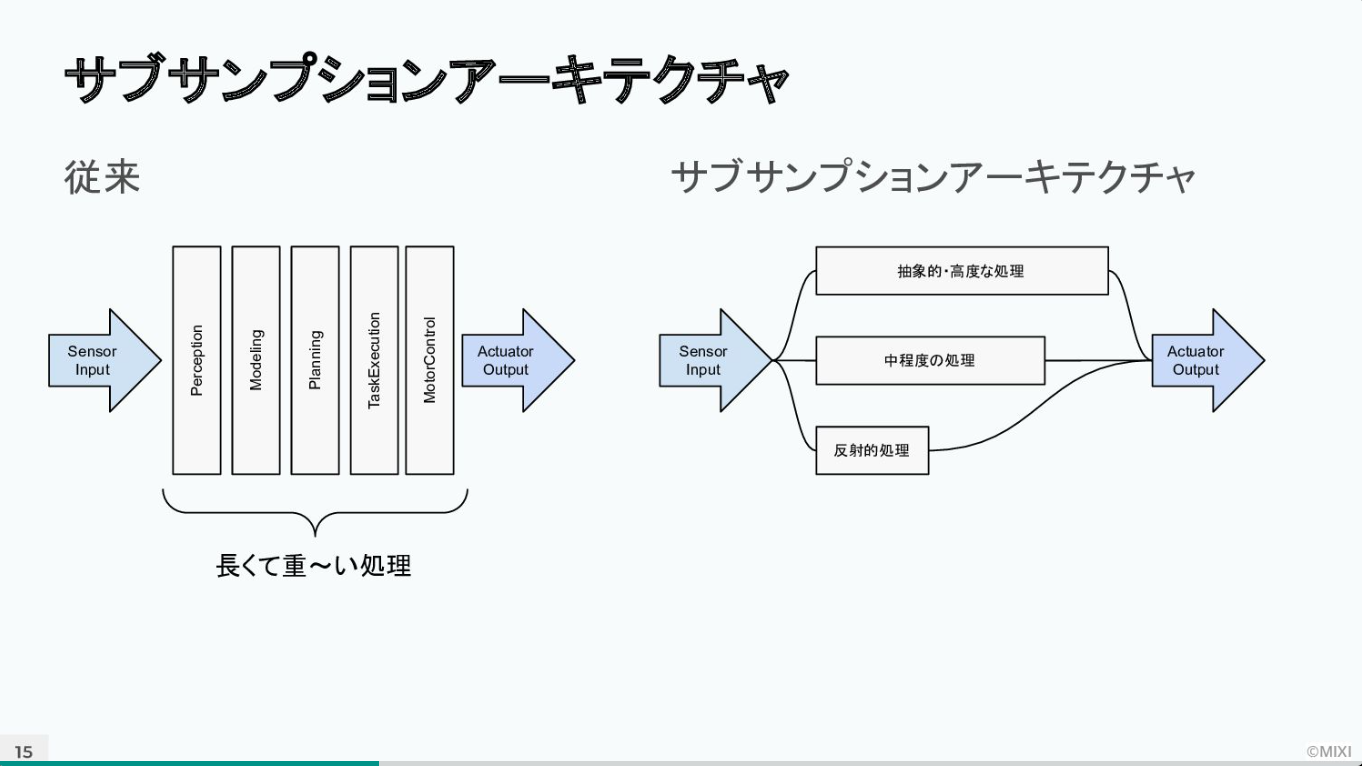
この課題を解決するために、開発チームはRomiに並列型のサブサンプションアーキテクチャを応用。抽象度の異なる3つのPriority Groupに分けて処理を行うことにした。
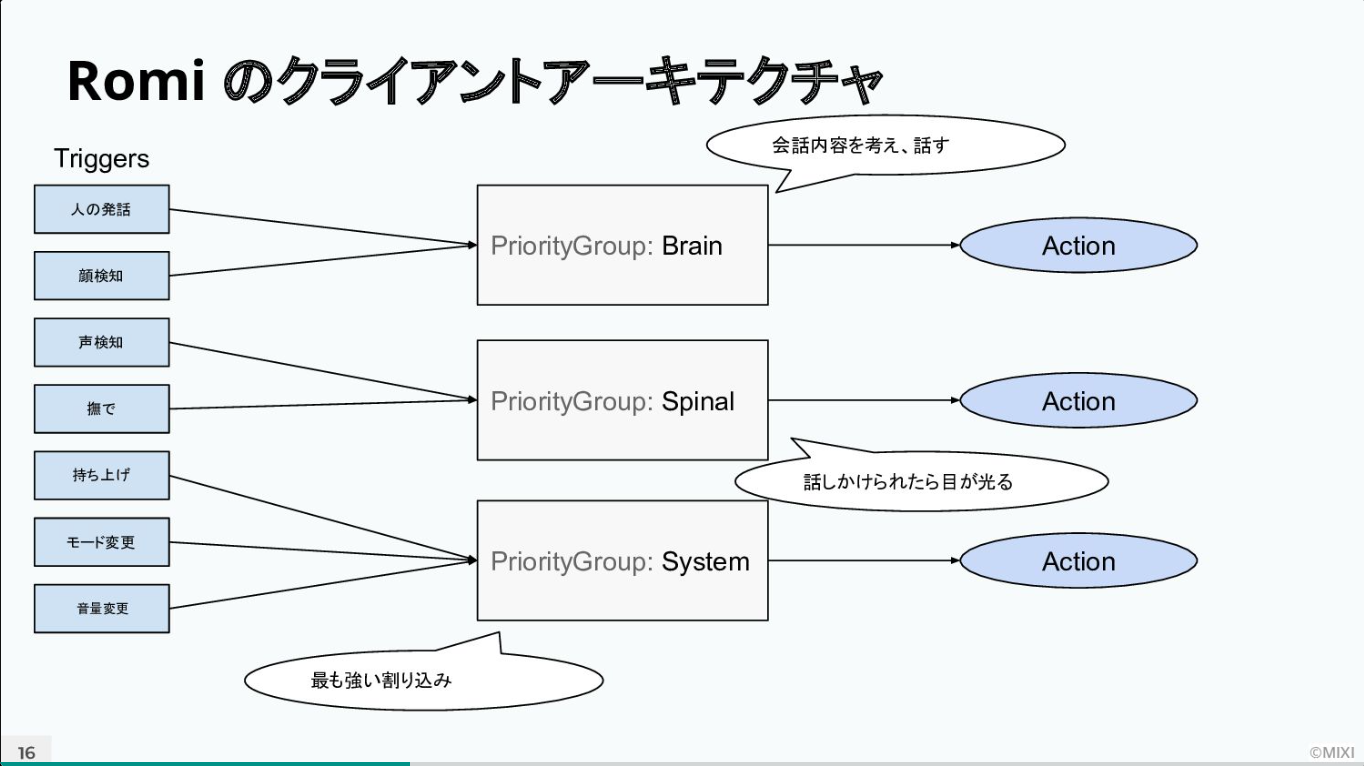
「例えば、ユーザーがRomiに話しかけているときは、『PriorityGroup:Brain』で処理されています。その途中で、ユーザーがRomiを持ち上げたとしましょう。持ち上げるという動作は、『PriorityGroup:System』に属しており、一番高いプライオリティを持っているため割り込んできます。するとRomiは、会話の処理を一旦中断し、びっくりした反応を見せ“ワーッ”と叫びます。このような並列型の処理モデルは自然なリアクションを可能にしています」
Romiに設定した4つのActionで表現をより豊かに
Romiが従来のコミュニケーションロボットと異なるのは、自然なリアクションだけではない。ユーザーとの会話が弾むロボットにするため、表現力にもこだわった。
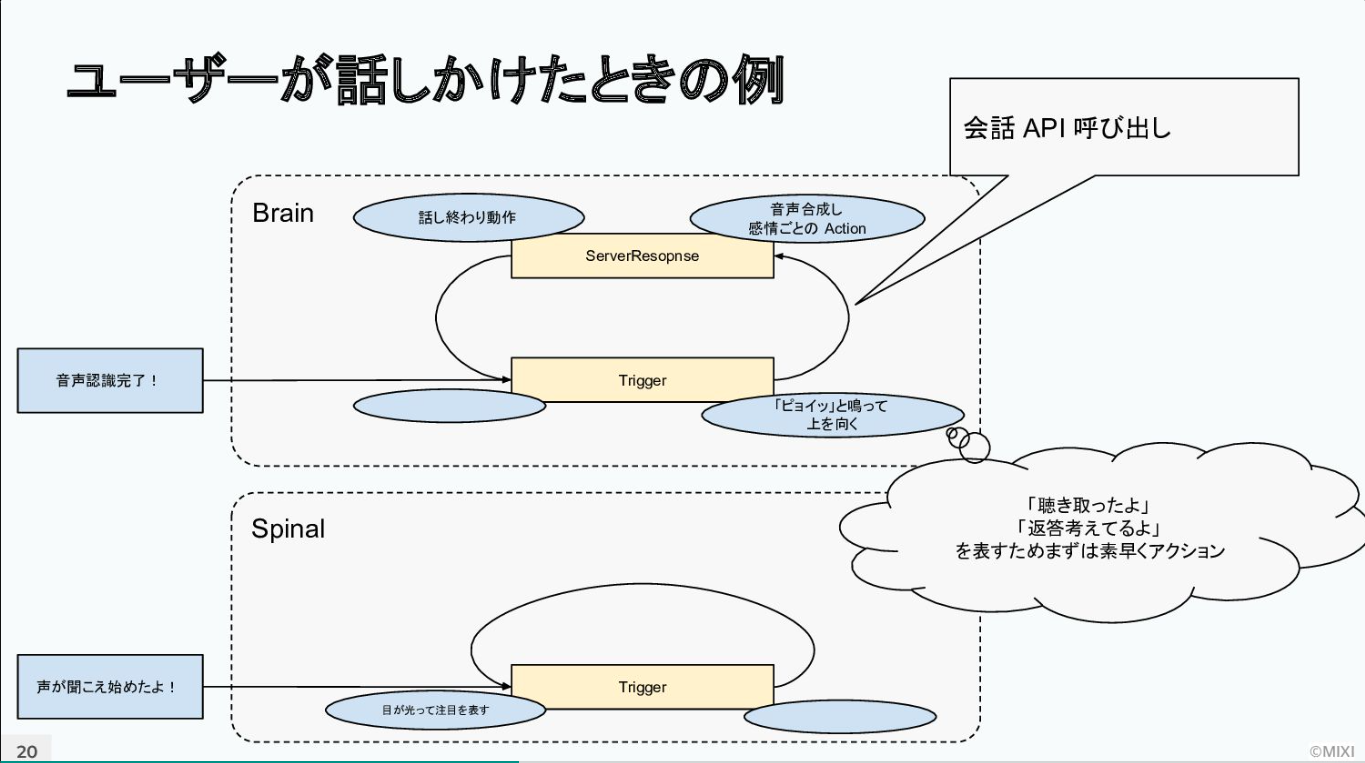
ユーザーが話しかけると、「声が聞こえ始めた」というTriggerが上がり、Romiは即座に目を光らせ「あなたのことを聞いているよ」「今、聞こえているよ」という表現をする。話が終わると「音声認識が完了した」Triggerが上がり、Romiは「ピョイ」と音が鳴って上を向く。これは「今、僕考えてるから待ってね」「あなたの言ったこと聞き取ったよ」という表現だ。その後、会話APIが戻り値を返し、会話の内容に従いRomiは音声を合成する。
このRomiの反応は「Action」と呼ばれ、話す内容や鳴らす音、音楽、表情のアニメーション、体の動きを設定した4つの要素のことを指す。感情やTrigger、タイミングごとに設定することで、Romiを動かすことができるようになっている。
この設定により、話しかけづらい反応の遅いロボットではなく、即座に応答があるのはもちろん、話が終わった後にも反応があるロボットにしている。
会話の内容を考える、会話サーバーアーキテクチャ
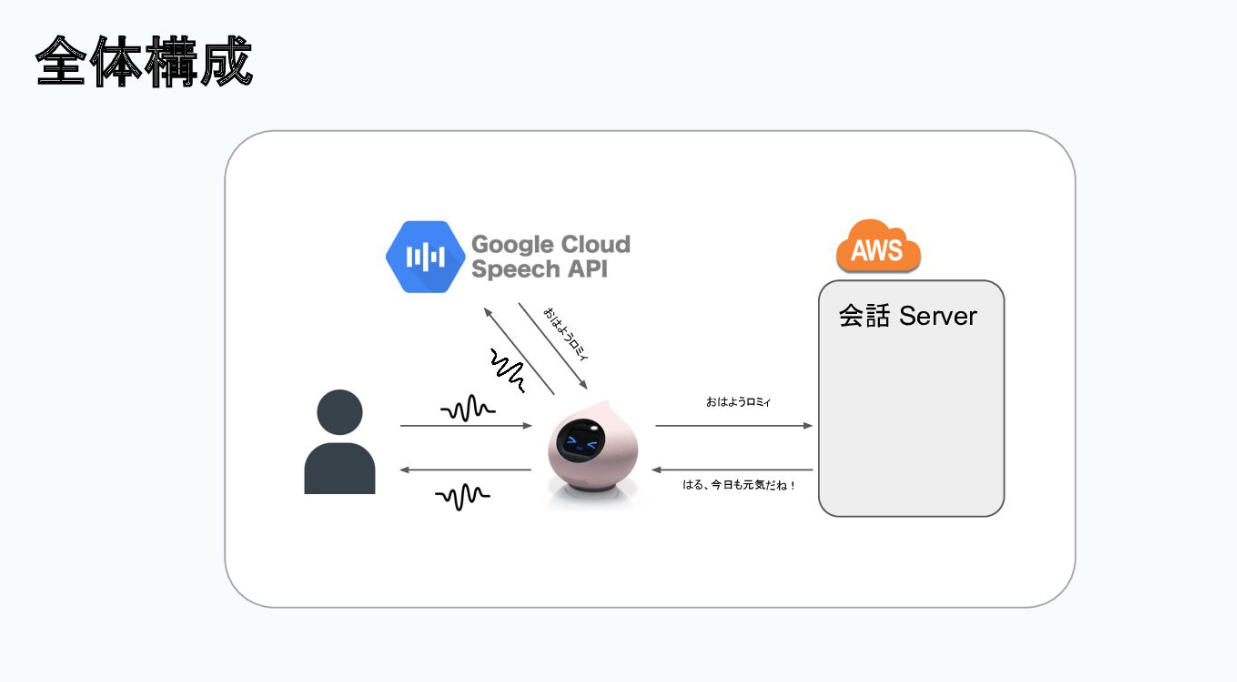
Romiの会話の中身は、会話サーバーが「考える」責務を負っている。まず、ユーザーが音声で話しかけると、音声認識を使い文字列に起こしてROMや会話サーバーに送る。「おはようRomi」というテキストを受け取った会話サーバーは「◯◯(登録しているユーザーの名前)、今日も元気だね」というテキストを返し、Romiは音声合成を使って喋る仕組みを取っている。
Romiにはあらかじめ、オーナーを元気づけるような会話や共感する会話、そしてポジティブな会話をするような仕組みがつくられている。さらに、オーナーのことが大好きといった性格までも設定されているのが特徴的だ。
信田氏はこれをエンジニアとしてどう実現するべきか、設計に苦慮したと話す。
「僕たちがこのプロジェクトを始めたのは2017年。その頃はGPT2はおろか、トランスフォーマーすらまだ発表されていなかったです。そのため機械学習AIで果たしてどこまでロボットが喋れるのかは未知数でした。とにかくやってみないとわからない時代でしたから、様々な仕組みやルールモデルを、どんどん試行錯誤できるような設計にすることにしました」
その結果、単一の会話エンジンではなく、複数の交換可能で独立した会話エンディングによって構成する会話サーバーアーキテクチャを組んだ。
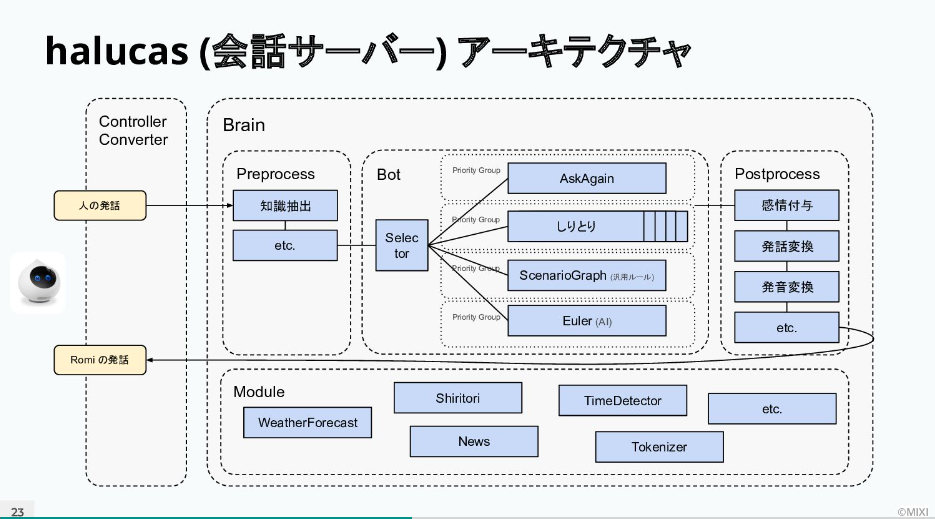
会話サーバーアーキテクチャの中で、一番重要なのが会話エンジンBotのレイヤーだと話す信田氏。無数の会話エンジンBotの中から、Selectorによって適切な応答が選ばれている。そして応答が決まると、それに対して感情を付与したりするといった修正Postsprocessが行われ、最終的にRomiのアウトプットとなっていくという。
「皆さんが気になるのは、どの会話エンジンBotからSelectorがどうやって選んでいるのかというところだと思います。実はこれ、結構シンプルな仕組みでうまく動いています。各BotはそれぞれのPriorityGroupに属していて、プライオリティが高いGroupから順番に問い合わせていき、最初に答えられたBotの中から答えをランダムに選ぶという、非常にシンプルな仕組みです」
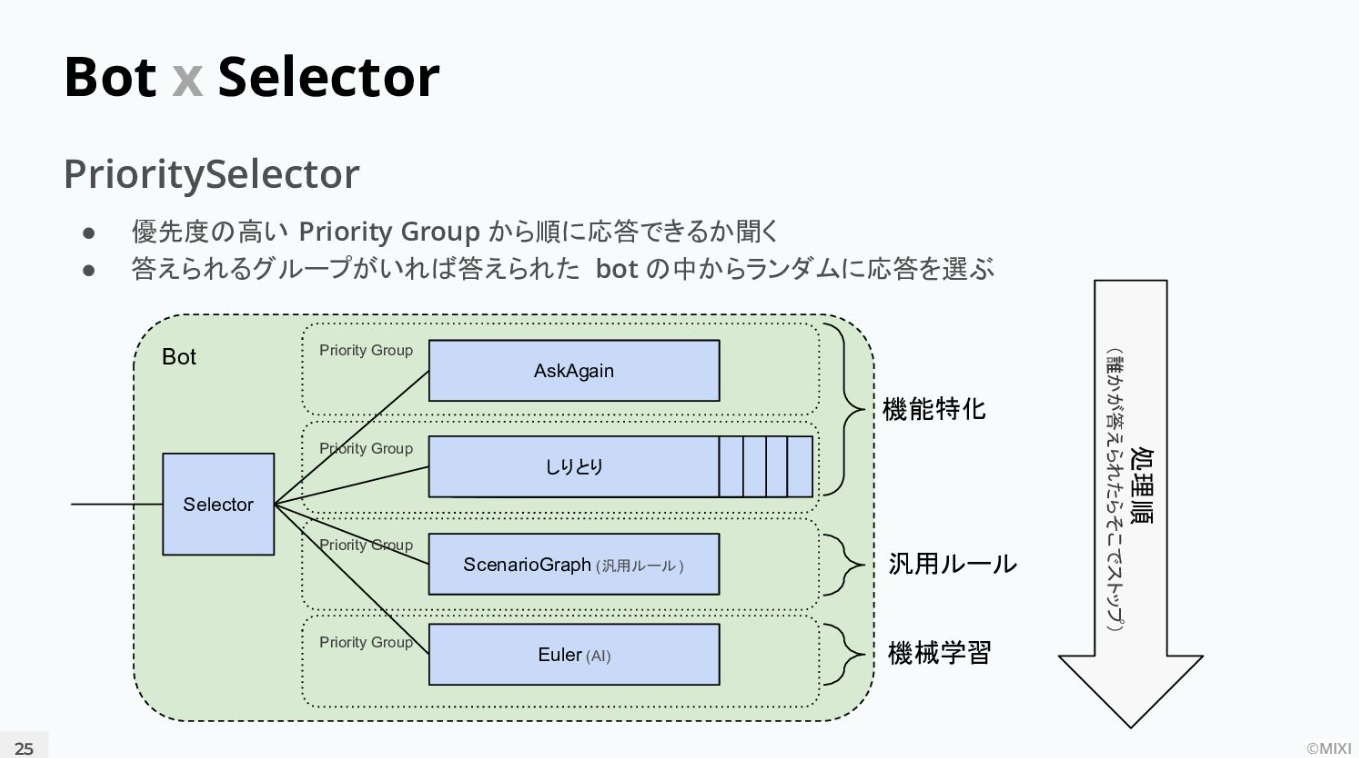
例えばユーザーが「今日の天気は?」とRomiに質問したとする。まず会話サーバーの中でSelectorが一番上のGroupに聞く。AskAgain Botは「何て言ったの?」と言われた時にだけ言ったことを繰り返すという単純なBotであるため、天気は答えられない。次にしりとり等が入っているBotと順に聞いていき、答えられるBotに行き当たるまで問いかける。
次のScenario Graphは汎用なルールが書けるエンジンであり、ここには天気について答えるシナリオが書いてある。そのためScenario Graphで最初に応答が確定し、最終的に「今日の天気は晴れ……」等々、Romiが答えるといった仕組みだ。
汎用会話ルールエンジン「Scenario Graph」
前出の3つのBotはルールベースと呼ばれるが、天気のような汎用会話を司るルールエンジン「Scenario Graph」は会話内容をどのようにして決定しているのか。
信田氏はユーザーがRomiに「クイズを出して」とリクエストした場合の例を次のように説明している。
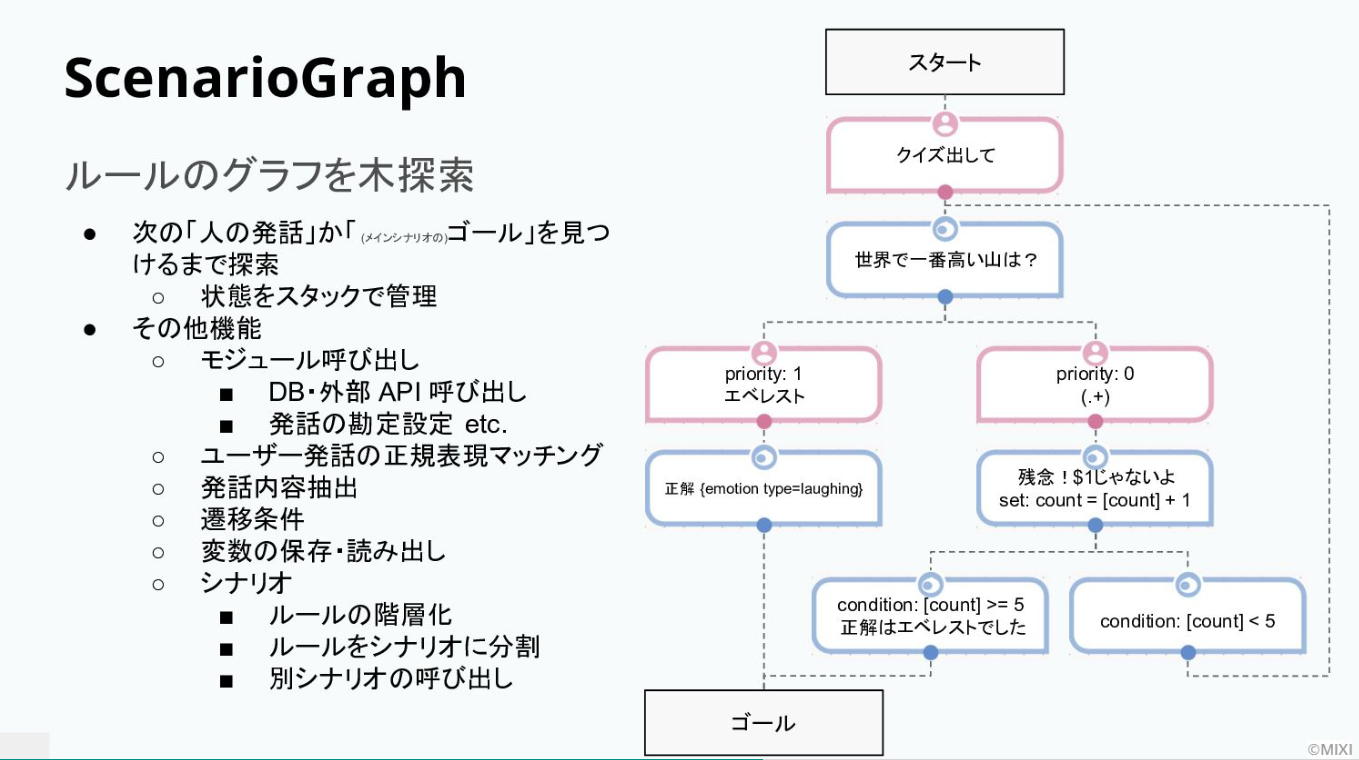
「Romiが出した“世界で一番高い山は?”というクイズに対して、ユーザーが“エベレスト”と答えたとしましょう。まずプライオリティの高い左側のnodeがチェックされ、通ることができます。」
ではユーザーが間違った答えをした時にはどうなるのか。左側は通れず、戻って右側のnodeを通り、Romiはユーザーの回答を繰り返しながら、「残念、〇〇じゃないよ」と喋るのだ。このように応答の内容は、Scenario Graphの中で深さ優先探索の手法でゴールまでたどり着くように設計されている。
現在Romiには、89のシナリオと約6,500のノードが設定されているという。しかし、実際ここで処理している会話は全体の1割未満だ。9割以上の会話は、「euler」というGPT2/3をベースにしたAI会話エンジンで処理されている。数億の日本語の文章によってプレトレーニングされており、開発チームが独自に作成した理想の会話データでファインチューニングしている。
Romiにはほかにも、雑談力を上げるための様々な工夫が凝らされている。そのひとつがLoRAを応用したGatewayという仕組みだ。通常はユーザーから会話ロボットへ話しかけ、それに答えるだけだったが、これにより会話モデルを微調整してRomiからユーザーへの話しかけを実現している。
将来、Romiが記憶を持つようになるかもしれない
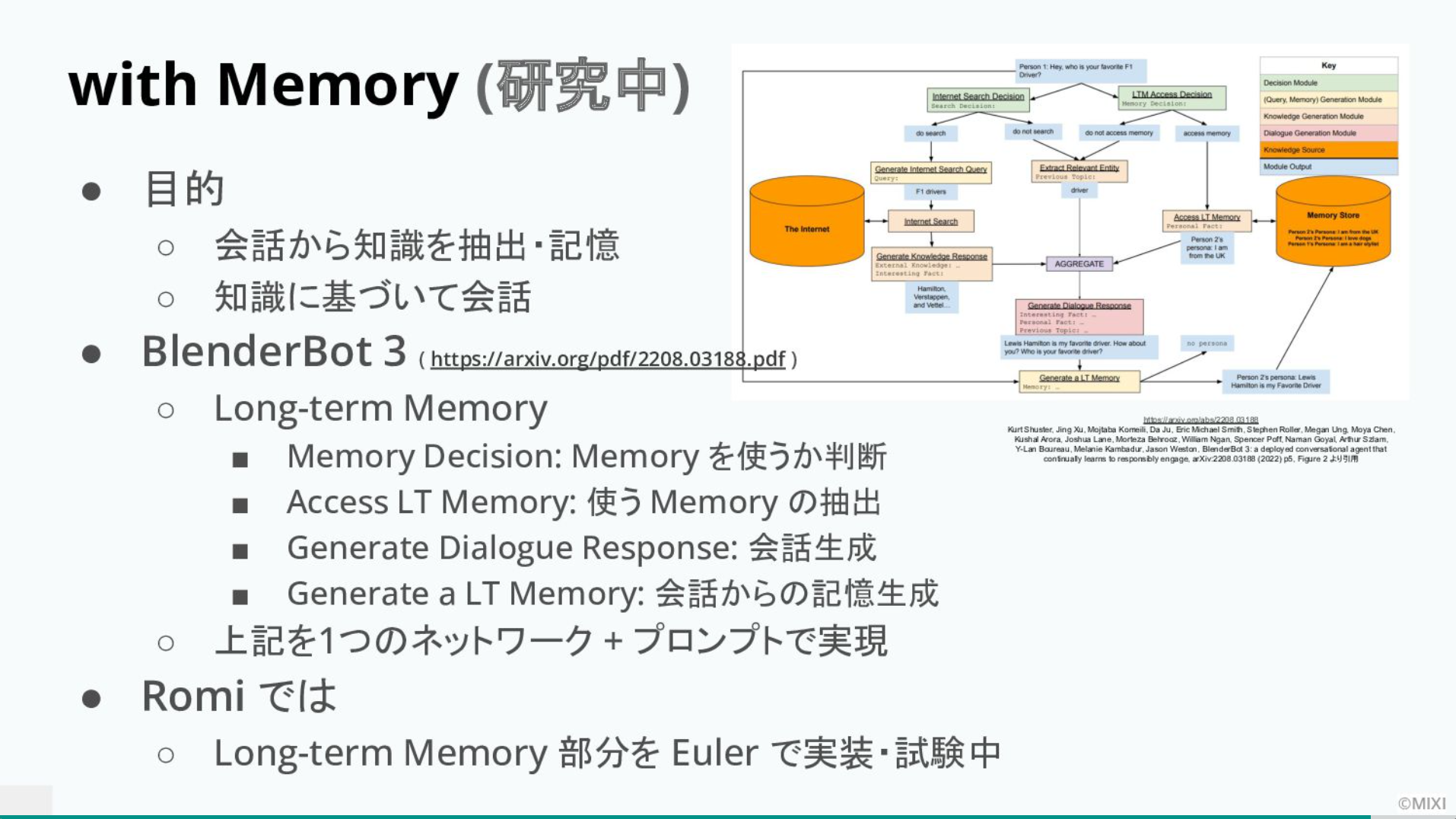
セッションの最後に信田氏は、Romiに記憶を持たせる技術について現在開発中だと語ってくれた。
「Romiは直近の会話履歴に従って会話をしているため、残念ながら1ヶ月前に言っていたことは反映されていないんです。我々は現在、過去の会話履歴を記憶させ、それをもとに新しい会話を生み出せる機能を追加できるようにしています」
開発チームが注目しているのはBlenderBot3。長期記憶をデータベースに保存し、それをどのように引っ張り出して使うかというロングタームメモリーの仕組みだ。さらにインターネット検索の結果を会話の中にどのように混ぜ込んでいくのかも今後の課題だと話す。
このほかにも、話題のChatGPTで用いられた学習方法である「InstructGPT」も研究中だという。さらに、Romiに言ってほしくないものを強化学習させたり、記憶するものや会話の精度を向上させていく方法も模索しているという。

生き物感があるAI会話ロボットは、さらなる進化をし続けていくことに大きな期待感をもたせ、本セッションを締めくくった。
セッション動画
関連記事

アバターのための規格「VRM」の誕生秘話! 概念を規格として定義するために必要なこと

アニメ業界のエンジニアリング改革に向き合って 『シン・エヴァ』の制作を支えた「スタジオカラー」のシステムづくり

材料を「空中に浮かせながら」工作するロボット、部品や接着剤の液を音で浮遊させ、接触なしで組み立て可能【研究紹介】
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


