![]()
![]()
ざっと落書きした絵をリアルな3Dモデルに変換する技術 米カーネギーメロン大が開発【研究紹介】
2023年2月28日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
米カーネギーメロン大学に所属する研究者らが発表した論文「3D-aware Conditional Image Synthesis」は、2次元コンテンツに応じた3次元オブジェクトを自動生成するpix2pix3D手法を提案した研究報告である。セグメンテーションや手書きによるエッジマップなどの2次元ラベルマップが与えられると、異なる視点から対応する画像を合成するように学習する。
研究背景
近年、生成モデルを用いたコンテンツ制作は大きな進展を見せ、ユーザーが制御可能な高品質な画像・映像合成が可能となっている。しかし、既存の画像間変換手法は、コンテンツの3次元構造を明示的に推論することなく純粋に2次元で動作する。
2次元情報を入力に3次元コンテンツを合成することは、非常に難しいのが現状だ。なぜなら、モデル学習のために、ユーザー入力とその出力がペアになった大規模なデータセットを入手するのにコストがかかるからである。また別の手法では、ユーザーが異なる視点から取得した2次元画像を複数枚必要としなければならないため手間がかかる。
研究内容
この研究では、ユーザーによる単一の2次元情報を入力に、3次元コンテンツを自動生成するモデルを提案する。このモデルは、生成だけでなく3次元での視点操作や編集も可能にする。
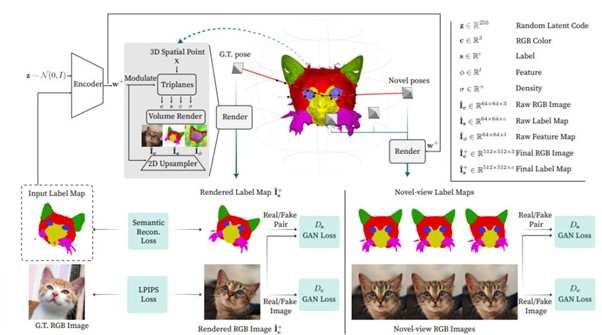
提案モデルは、2次元ラベルマップ(セグメンテーションマップや手書きによるエッジマップなど)、ランダムな潜在コード、カメラのポーズを入力とし、生成器がラベルマップと新しい視点からの画像をレンダリングする。
具体的には、まずエンコーダで入力ラベルマップと潜像コードの両方をスタイルベクトルにエンコードする。次に、変換したベクトルを用いて3次元表現を変調し、空間点から色、密度、特徴量、ラベルを出力する。最後に、ボリュームレンダリングと2次元アップサンプリングを行い、高解像度ラベルマップとRGB画像を得る。
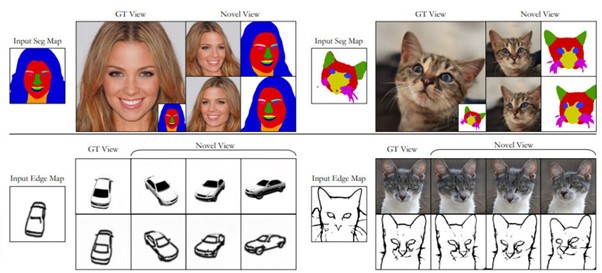
学習したモデルは、セグメンテーションや手書きのエッジマップなどの2次元ラベルマップに応じた、異なる新しい視点からの3Dオブジェクトを出力する。

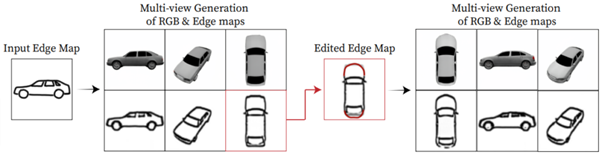
また、推定された3Dラベルにより、任意の視点からラベルマップをインタラクティブに編集できる。
例えば、次の画像だと、車のスケッチから生成した車の3次元オブジェクトに対して、2次元スケッチをグリグリ視点方向を変えられる。
さらに、そのスケッチに対して後から部分的に消して書き加えることができる。書き加えたスケッチは3Dオブジェクトにも反映され、編集後の3次元オブジェクトが新たに生成される。例では、車のボディを丸くする編集を2次元スケッチに書き加え、丸みのある3Dボディを生成している。
評価結果
本手法の出力結果を評価するため、既存の先端研究(Pix2NeRF variants、SoFGAN、SEANなど)の2次元及び3次元のベースラインと比較実験を行った。結果、本手法が既存の手法よりも優れた画質と位置合わせを実現しており、その性能の有効性を示した。
また、様々な設計上の選択の影響を明らかにし、クロスビュー編集や意味やスタイルに対するユーザー制御など、本手法の応用も実証し、実用性を示した。

Source and Image Credits: Kangle Deng, Gengshan Yang, Deva Ramanan, Jun-Yan Zhu. 3D-aware Conditional Image Synthesis
関連記事

「3年前に戻れるなら、同じ意思決定はしない」マネージャーをなくしたサイボウズから学ぶ、フラット型組織でできないこと

イスラエルと米国の研究者らが開発 3Dモデルを簡単編集できるAIシステム「GeoCode」【研究紹介】

カメラ1台で多人数の全身の動きを3Dモデルで復元する技術 背景の3Dシーンも一緒に再現【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


