![]()
![]()
最新のデータスタックは、ただ古いワインを新品ボトルに入れただけなのか【テッククランチ】
2022年12月12日

寄稿者
Ashish Kakran
Thomvest Ventures代表。プロダクトマネージャー/エンジニアから投資家に転身し、技術的ノウハウ、顧客インサイト、課題への共感、マーケット知識のバランスを取りながら創業者をサポートしている。
かつて郵便受けに入っていた、ケーブルテレビ、電話、インターネットのサービスがセットになった商品を売り込むチラシを覚えているだろうか。これらのオファーは、高度にコンバージョンに最適化されており、オファーの種類や月額料金は近所同士で、あるいは同じ建物内の世帯間でさえ、大きく異なることがあった。
筆者は以前、データエンジニアとしてこの種のオファー最適化のためのETL(データの抽出・変換・格納)パイプラインを構築していたため、この仕組みをよく知っている。暗号化されたデータフィードを解読してデータのない行や列を削除し、フィールドを社内のデータモデルに対応させることも仕事の一部だった。そして統計チームはクリーンな最新データを使って各世帯に最適なオファーを作成した。
これは約10年前のことだ。このプロセスを100倍大きなデータセットで実行すれば、中堅・大企業が今日扱っているような規模になるだろう。
例えば、1回のビデオ会議で数百のストレージテーブルを必要とするログが生成される。クラウドがビジネスのあり方を根本的に変えたのは、手頃な価格で手に入れられる無制限のストレージとスケーラブルなコンピュートリソースがあるからだ。
簡単に言うと、これが古いスタックと最新のスタックの違いだ。

今日のデータ責任者はなぜ最新のデータスタックにこだわるのか
セルフサービス分析
開発経験がほぼないシチズンデベロッパーは、重要なビジネスダッシュボードにリアルタイムでアクセスすることを望んでいる。彼らは業務データや顧客データをもとに構築された自動更新のダッシュボードを求めている。
例えば、製品チームは意思決定のために製品の使用状況や顧客の更新情報をリアルタイムで利用することができる。クラウドによって誰でもデータにアクセスできるようになったが、レガシーで静的なオンデマンドレポートやダッシュボードに比べ、セルフサービス型の分析に対する需要は高いだろう。
予測を提供可能
機械学習モデルが訓練され、使用できるようになったら、組織内のさまざまなチームが簡単にその恩恵を受けられるようにする必要がある。これは通常、リクエストを受け付けてから予測を返すというシンプルなURLで実現される。このようなマイクロサービスを構築し維持することは、1秒あたり何千ものHTTPリクエストを提供する場合において中核的な課題だ。
データのインプレース変換に最適
データサイエンティストは実験を行い、訓練を完了するためにどのバージョンのデータが使われたかを知ることができるよう、古いバージョンのデータを追跡可能にしたいと考えている。このようなニーズから、データのインプレース変換に最適化された製品が人気を集めている。
データの品質が高い
最先端のデータ組織の中には、モデル中心のアプローチよりもデータ中心のアプローチを好むところもある。データが多ければ多いほど良い結果が得られるという考えは、データの品質を重視する考えに取って代わられつつある。
通常、訓練されたモデルは適合率と再現率という2つのパラメータを使って評価される。適合率は予測で実際に正しかったものの割合を示し、再現率は実際に正しいもののうちモデルがどの程度それを予測できたかの割合を示している。ここで、様々なフォーマットで送られてくるリアルタイムのデータストリームに対してデータ品質を確保することを想像してみてほしい。
古いデータスタックと最新データスタックはどう違うのか?
一般的に、最新のデータスタックはクラウドのリソースを活用して、複雑なストリーミングデータをより効果的に分析するものだ。
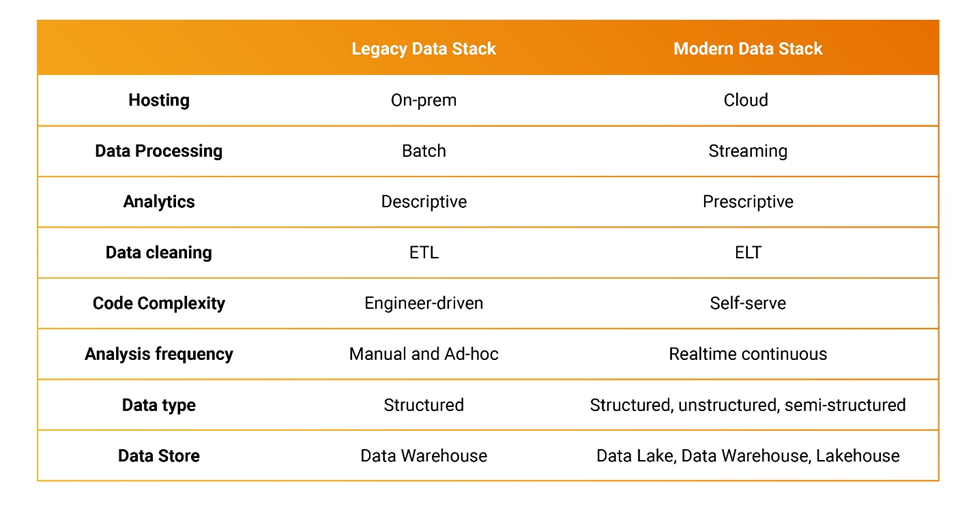
以下では、企業が注意すべき重要なトレンドを紹介する。
・ ETLプロセスはEL(T)化しつつあり、データレイクのような特定の場所で受信したデータがまず処理されることを意味する。この方法では、ストレージシステムは保存されるデータの形式を問わない。いったんデータが保存されると、その場で分析用に処理することができるようになる。こうすることで、連続したデータをより効果的に管理、処理、分析することができる。
・データの可視化は非常に重要だ。データはそのままだと、価値を発揮できない。急速に進化するデータスタックでは、データを監視し、アラートを設定して問題を解決できることが必要だ。スペイン語を学習させたモデルが誤って英単語や欠損データで学習するようなことは避けたいだろう。何百万行ものデータを視覚的に分析し、修正することはできない。
・データ/人工知能(AI)/データ&アナリティクス最高責任者が登場している。データは非常に複雑なため、最高情報責任者(CIO)は今や最高デジタル責任者(CDO)/最高総務責任者(CAO)/最高データおよび分析責任者(CDAO)を部下に持つようになった。21世紀にはデータが競争優位を持つようになったが、今は管理されていないデータが有害になる時代だ。データの使用・共有・取り扱いについて規制法がある。データがどこに、どのような形で保存されているのかなどを知らずして顧客からの全データ削除の要求にどうやって応えられるだろうか。
企業データパイプラインを構築する際、実行者は選択肢に困ることはない。
データ分析プロセスの各ステップは崩れつつある。先見の明がある創業者たちは、新たなデータカテゴリーで勝ち抜くためにクラウドネイティブのツールを開発している。だた、既存企業の対応は遅れている。データパイプラインまたはMLパイプラインのいずれを構築する場合でも、今日の組織はさまざまなオープンソースとクローズドソースのテクノロジーから選ぶことができる。
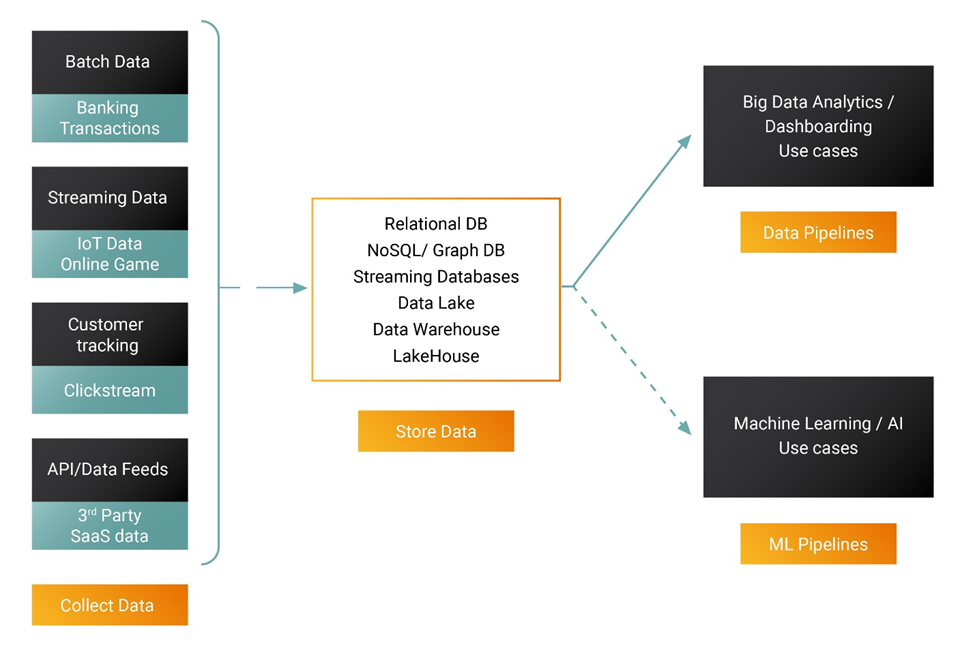
データエンジニア、データベース開発者、データサイエンティストにとって効率的なデータスタックは4~5年で変わる。企業はプライベートデータセンターで大規模なデータセットを分析するためにビッグデータ分析に移行し、多くの利益を約束したが、ビッグデータの実装は技術的に複雑なままだ。最新のデータスタックはクラウドのスケール、信頼性、レジリエンスを活用することでこれを簡単なものにしている。
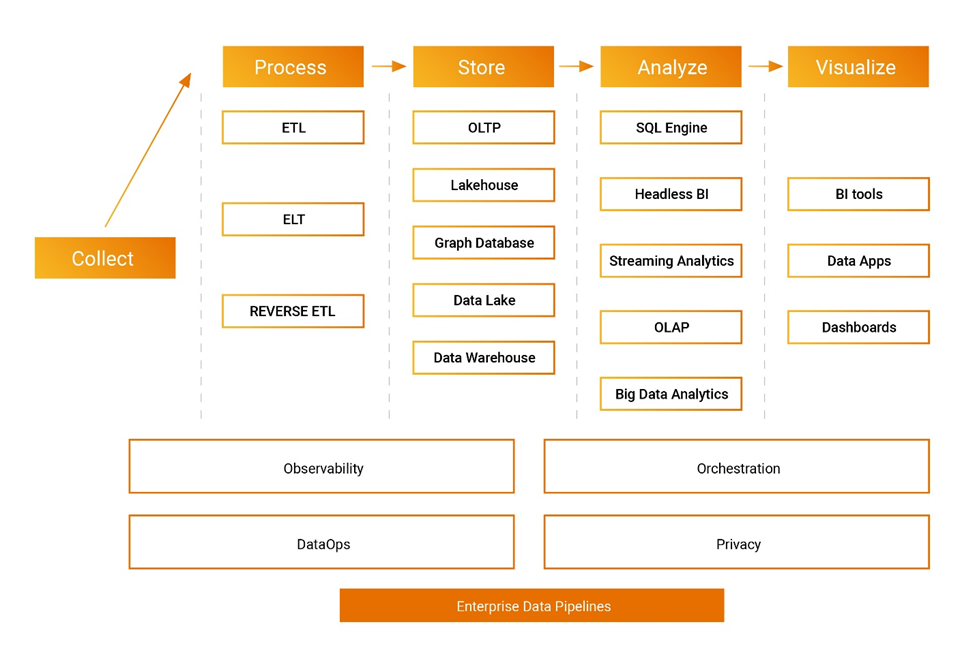
競争優位のためにデータをどのように利用するかについて、ルールが書き換えられつつあり、間もなく勝者が現れるだろう。既存企業は古いソフトウェアをクラウド上で動作するように再設計しているが、先見性のある創業者が率いる機敏なチームに軍配が上がるのではないか。
From TechCrunch. © 2022 Verizon Media. All rights reserved. Used under license.
元記事:Is the modern data stack just old wine in a new bottle?
By:Ashish Kakran
翻訳:Nariko
関連記事

【DeNA TechCon 2021 Autumn】デジタルコレクティブ、世界展開、データベース運用、QCDコントロール。企業成長でつけられた課題にDeNAはどう挑んだのか【イベントレポート】

生存戦略のカギは「ビジネス力」。業界のトップランナーが語る、データサイエンティストがビジネスを考えられる強み

【Lookerハッカソンで世界2位】好きこそものの上手なれ。モンストの凄腕データエンジニアがハマる「データで遊ぶ」醍醐味とは
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


