![]()
最新記事公開時にプッシュ通知します
![]()
AIが「多数決」で正解を決定? 答え合わせなしで正答率を向上させる自律学習手法TTRLとは
2025年10月30日


ITジャーナリスト
生活とテクノロジー、ビジネスの関係を考えるITジャーナリスト、中国テックウォッチャー。著書に「Googleの正体」(マイコミ新書)、「任天堂ノスタルジー・横井軍平とその時代」(角川新書)など。
AIは、自分で性能を向上させ自律進化の能力を獲得し始めている。清華大学と上海AI研究所が開発した強化学習の手法「TTRL(Test-Time Reinforcement Learning、テスト時強化学習)」では、AIに正解が用意されていない問題を与えても、自分で正解を仮定し強化学習ができることが示唆された。AIが自分で学ぶ能力を身につけたことにより、AIの知能の進化が加速をし、シンギュラリティが幕を開けるのではないかと考えられている。
「シンギュラリティ」の定義をめぐる混乱
「シンギュラリティ(技術的特異点)」は、世間一般には「AIが人間の知能を超える瞬間」と言われる。
だが、この定義に違和感を感じている人は多いはずだ。というのも、もともとシンギュラリティという言葉は、数学や物理学の世界において、パラメーターが無限大になり、方程式が成立しなくなる「特異点」を指すからだ。例えば、ブラックホールの中心では理論的に質量が無限大になるため、時空を関連づける方程式が成り立たなくなる。より身近な例で言えば、分数の分母をどんどん小さくしていき、分母が0になると特異点に達し、分数の値を決められなくなる。
人間とAIの「知能」は比較できるのか
そもそも、AIの文脈で使われている「シンギュラリティ」においても、「AIが人間の知能を超える」の「知能」の定義が難しい。計算力なのか、推論力なのか、創造力なのか、知能が何であるかを定義しなければ、AIが人間を上回ったかどうかすら確認できない。
実際、現在行われているAIと人間の「知能」の比較は、的外れなものが多い。例えば、資格試験の正答率を「知能の高さ」の根拠にする事例をよく見かけるが、これはほとんどの場合あまり意味がない。なぜかというと、多くの資格試験は正解がある問題の比重が高く、教科書や参考書などの資料を事前学習したAIにとっては、「教科書持ち込み」で受験しているようなものなので、好成績を取るのは当たり前だからだ。
反対に、小学生レベルの算数の問題で正答を導き出せない場合もある。例を挙げると、「時計を読む」ということは今のAIには難易度が高い。実際に、12時18分37秒の時計を、ChatGPTは「3時ちょうど」と答え、Geminiは「1時20分」と答え、DeepSeekは6段階にわたる推論をした挙句「1:00」と答えた。中国バイトダンスの「豆包」は「12時19分37秒」と1分違いの答えを出した。
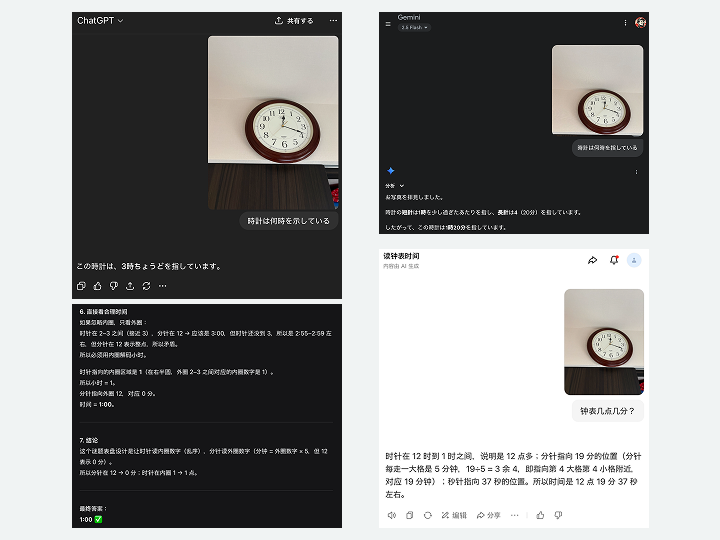
▲主要なチャット型生成AIで試したところ、正解したAIはひとつもなかった。12時18分37秒を指す時計の画像から時刻を尋ねた際のChatGPT(上段左)、Gemini(同右)、DeepSeek(下段左)と豆包(同右)による回答
これは、AIの開発者たちが必要な事前学習をさせていないだけだと考えられる。
AIの自律的な強化学習に関する研究が注目される
上記のような背景から、AIが人間の手を離れ、自律的学習能力を身につけたときにシンギュラリティが始まる、という考え方がある。
AIに自律学習能力があれば、人の手を借りずに、自分で学習素材を探し出し、学習を進めることができる。さらには、答えのない問題についても推論をもとに一定の結論を導き出し、今度はその結論を踏み台にさらに推論を積み上げていくことができる。
これが可能になったとき、その時点で人間の知能を上回っているかどうかは関係なく、シンギュラリティが始まるというのだ。自律学習ができれば、遅かれ早かれ人間を超越することになると考えられるからだ。そこで、多くの研究者が強化学習を自律的に行う仕組みの研究開発に注目している。
「答えなし」で自ら学ぶ手法TTRL
今回紹介するのは、清華大学と上海AI研究所が開発した強化学習方法「TTRL(Test-Time Reinforcement Learning、テスト時強化学習)」だ。TTRLはシンプルな仕掛けで自律学習を重ね、正解がない/わからない問題を解けるようになるというものだ。その成果は「TTRL: Test-Time Reinforcement Learning」として公開されており、関心を集めている。
多くの場合、数学の問題1つにつき、正解を導き出すための解法は複数ある。例えば、角度を求める幾何の問題を解くときに、直角二等辺三角形や正三角形、対角、錯角などを使って幾何学的なアプローチで解くことができれば、線分をベクトルとして捉えて代数学的なアプローチで解くこともできる。囲碁の手を考える時に、パターン認識アプローチもあれば、盤面評価関数を使って探索木を使うアプローチもある。あるいはそのような複数の手法をうまく組み合わせることも考えられる。
一般的な強化学習では、まず、正しい答えがわかっている問題を複数アプローチで解かせる。正解すれば報酬を与え、不正解であれば減点をすることで、正解にたどり着きやすいアプローチをAIに学習させる。使われる教材は、さまざまな研究者が公開しているベンチマークテスト集が基本になる。これは、問題と答えがセットになったもので、AIの性能評価に使われる。これをAIに解かせて、正解にたどり着きやすい手法を学ばせる。
TTRLの研究チームは、このようなベンチマークの答えをわざと隠してAIに複数アプローチで解かせて強化学習を行ったという。
となると、どうやって報酬を与えるべき解法を判定するのだろうか。
「多数決」で正解を仮定し、正答率を改善
チームは複数アプローチで出された解答を集め、いちばん多かった解答を正解とみなした。その(仮の)正解と一致した解答に報酬を与えた。多数決で決めるようなものなので、当然ながら誤答の可能性もあるが、「正解である可能性は高い」と言える。
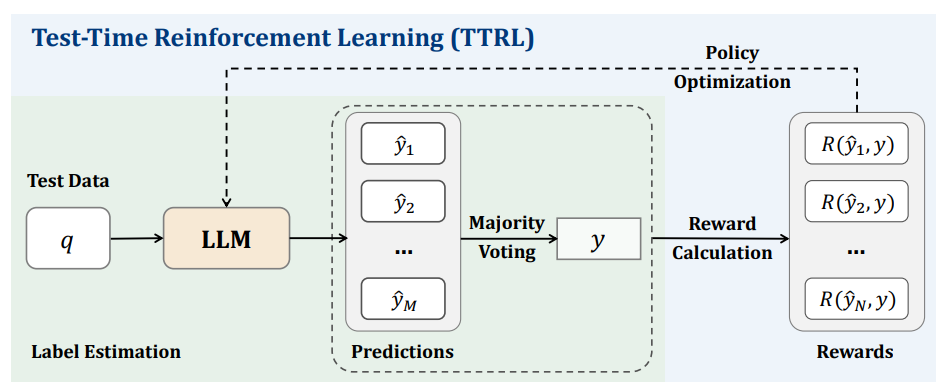
▲TTRLの仕組み(画像出典:https://arxiv.org/pdf/2504.16084)
実際に既存の大規模言語モデル(アリババのQwen、メタのLLaMa)に、複数のベンチマークを教材に、この単純な手法(TTRL=テスト時強化学習)で強化学習をさせると、いずれも強化学習以前と比べて正答率が向上した。Qwen2.5-Math-1.5Bの場合、4つのベンチマークの正答率が23.5%だったものが、41.0%にまで向上した。
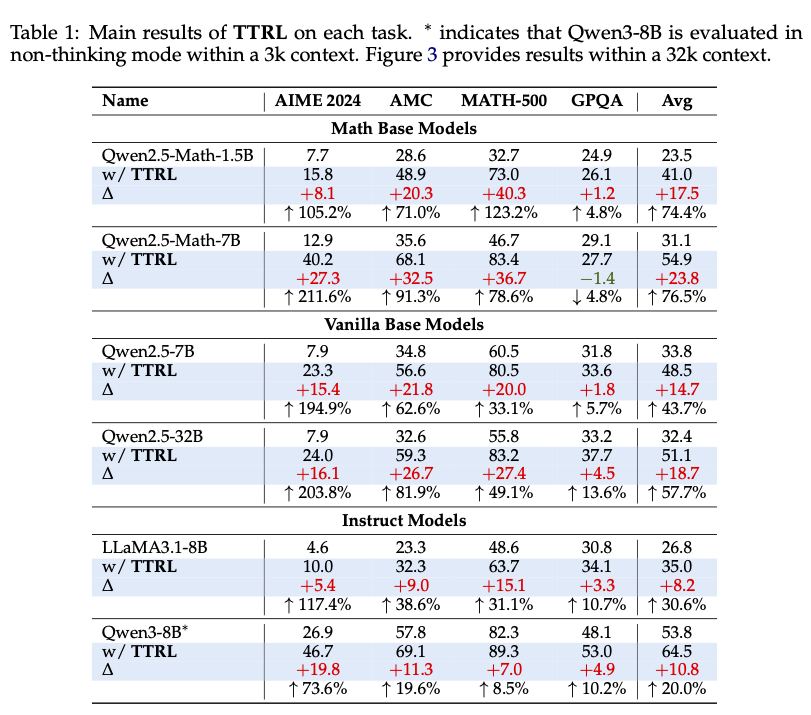
▲TTRLで学習を進めた効果。縦軸はQwen、LLaMAなどのオープンソースAIモデル。横軸はさまざまなベンチマーク。最上段のQwen2.5-Math-1.5Bの場合、TTRL学習前は4つのベンチマークの平均スコアが23.5であったものが、TTRL学習を施す(w/TTRL)と41.0にまで向上した。(画像出典:https://arxiv.org/pdf/2504.16084)
つまり、このTTRLは、正解のない問題を学習させても正答率を上げられる可能性がある手法であると考えられる。
TTRLへの期待
現在のTTRLは、数学系のベンチマークテストの正答率を向上させることができる程度でしかない。ベンチマークも、中学程度の数学から競技数学までの問題と解答を集めたものにすぎないが、今後、TTRLで鍛えたAIは解答がない問題、例えばリーマン予想のような人類がまだ解いていない問題を解いてくれる可能性がある。
そこに至るには膨大な強化学習が必要で、長い時間がかかるかもしれない。しかし、高速に処理ができるAIは疲れることを知らない。私たち人類の時間軸では長いとは言えない年月で、人類未到の問題を解決してしまうかもしれない。
関連記事
AIが自分自身に報酬を与えて進化する「自己報酬型言語モデル」 米Metaなどが開発、実験でGPT-4を上回る【研究紹介】

GPT-4にWebサイトを“自律的に”ハッキングさせる方法 AI自身が脆弱性を検出、成功率70%以上【研究紹介】

生成AIはなぜ簡単な計算問題を間違えるのか。トークナイザーから見るLLMの計算プロセス
人気記事

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋

人間のコードレビュー力を鍛えるために。AIコーディング時代の「ペアプロ・モブプロの心得」


