![]()
最新記事公開時にプッシュ通知します
![]()
【DeNA TechCon 2021 Winter】DeNA の MLops エンジニアは何をしているのか。機械学習基盤「Hekatoncheir」を解説【イベントレポート】
2022年2月8日


システム本部データ統括部 AI基盤部MLエンジニアリング第一グループ
川瀬 拓実
東京理科大学大学院卒。入社後はAI基盤部MLエンジニアリング第一グループにてAIエンジニアのサポート。最近は主にKubernetes周りの導入を進めている。好きなことは様々な技術に触れること。
エンジニアを目指す学生に向け、「エンジニアとして企業で働く」をテーマに、DeNAで活躍するスペシャリストたちが語る「DeNA TechCon 2021 Winter」。今回紹介するセッションは、DeNA川瀬拓実氏が語った「DeNAのMLopsエンジニアは何をしてるのか」。DeNAが様々な事業で活用しているAIのモデルを実際に利用するために、機械学習基盤やインフラを用意することや、フロントエンドの開発を行うなど、様々なサポートを行うMLOpsエンジニアは、日々どのような課題と向き合っているのかをお伝えします。
第1弾はこちら
【DeNA TechCon 2021 Winter】新卒4人が語り合う。DeNAで活躍する技術スペシャリストなエンジニアの仕事・キャリアとは【イベントレポート】
DeNAにおけるMLOpsエンジニアとは
MLOpsとは、DevOpsとAIの概念が組み合わさってできた比較的新しい概念で、特にAI周りのサポートをすることを指す。DeNAでは、AI以外の全てをスコープとするエンジニアのことをMLOpsエンジニアとしている。
「提供するAIの数に対して少ない人数でもスケールするように、自動化を目指して頑張るのが、MLOpsエンジニアのメインの業務になっています」(川瀬氏)
具体的にはどのようなスキルセットが必要なのか。それを一覧で挙げたものが以下である。
データサイエンティストがつくったAIをユーザーに提供するためのフロントエンド、バックエンド開発、クラウド、コンテナ技術、CI/CD、セキュリティ、ネットワークアーキテクチャなど、様々な分野のスキルセットが必要とされる。
「これら全てを1人でカバーするのは難しいので、チーム内でお互いの強みを活かしながら、日々の業務を行っています」

DeNAのMLOpsエンジニアとして、いましていること
続いて、川瀬氏が今行っている業務について詳細に紹介した。
まず一つ目に挙げられたのは、データサイエンティストがつくった成果物を提供すること。フロントエンドの開発では、Nuxt.jsで提供されているものを、Next.jsに置き換えている途中だという。バックエンドの開発では、モデルがPythonで提供されているため、FastAPIというフレームワークや、データベースとしてMySQLを使用している。
二つ目のタスクは、WebAPIの運用である。川瀬氏は、ライブコミュニケーションアプリ「Pococha(ポコチャ)」関連で、不正な配信を自動検出するAIを稼働させ、サポートの負担を軽減している。
三つ目のタスクが、本日のメイントピックでもある機械学習基盤「Hekatoncheir」の開発である。川瀬氏のチームは、このWeb API サービング機能の整備を行っている。
機械学習基盤「Hekatoncheir」とは
機械学習基盤「Hekatoncheir」とは、社内のデータサイエンティストがつくったモデルをプロダクション環境に持っていく際に、ハードルとなる課題を解決するために開発された仕組みだ。例えば、モデルをWebAPIとして使えるようにしたり、古くなったモデルやデータセットの継続的な更新を行っている。
「Hekatoncheirの責務は、学習から推論用のWeb APIサーバーのDockerイメージ(アーティファクト)の生成まで行うこと。現在、Google Cloud Platform(GCP)上に構築された一連のパイプラインとして、データサイエンティストに提供しています」
Hekatoncheirのアーキテクチャは、GCPを活用したパイプラインとなっており、Cloud FunctionsというDockerにコードデプロイすると関数として動くDockerイメージを使っていると、川瀬氏は補足する。
「クラウド上のビルドを行うCloud Buildや、ユーザーがデプロイしたコードを動かすAIプラットフォーム、Pub/Subと呼ばれるメッセージングサービスを活用しながら、パイプラインを構築しています」
パイプラインの概念については、以下の図が示す通り、ユーザーが開発したコードをSubmitすると、まずGCP上に構築されたHekatoncheirでTrainingが行われる。次にEvaluation、最後にArtifactが生成される。Dockerイメージとしてビルドされたものが、コンテナレジストリの方に登録されるという仕組みだ。
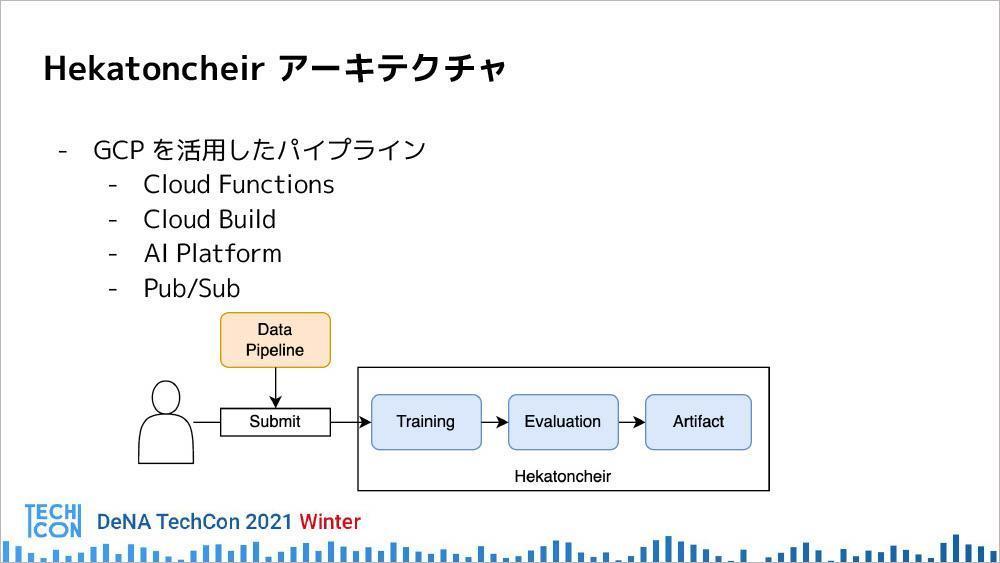
モデルの継続的な更新のためには、新しいデータをどんどん入れて精度を高めていく必要がある。そのためデータを更新した場合は自動的にSubmitが行われ、パイプライン上で一連の動きが行われる構成になっている。
また前述の通り、Hekatoncheirはアーティファクトの生成までを責務としているシステムであり、その運用は、各事業部が個別に行う必要がある。そのサポートとして、WebAPIの運用までもスコープに入れようとする取り組みが「Hekatoncheir Serving」である。
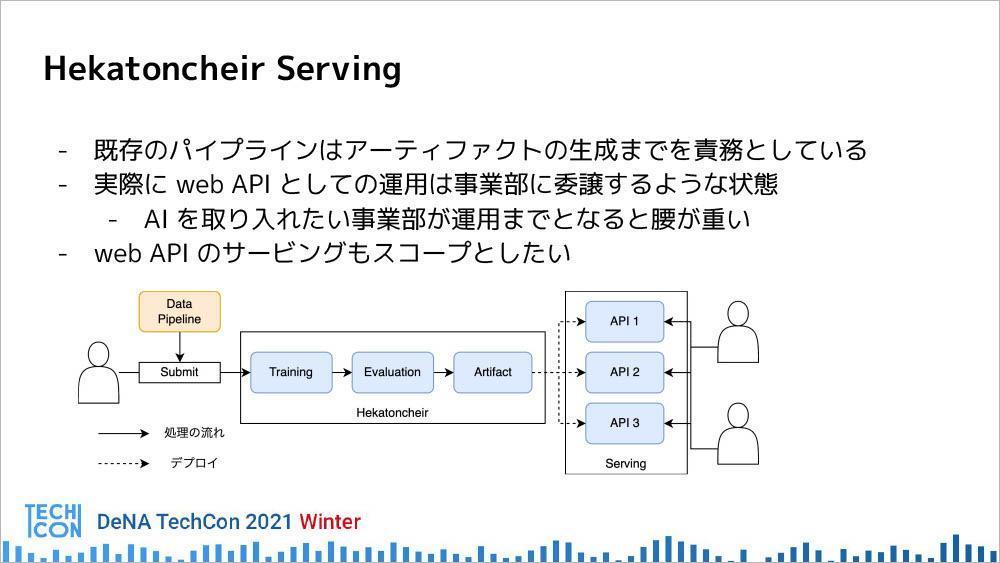
要件として挙げられるのはまず、既存のパイプラインの延長として、WebAPIとしてサービングすることである。二つ目が、AIの数に対してMLOps エンジニアの数が限られるため、自動化して、スケールするように持っていくこと。具体的には、以下のような対策を行っている。
- ・認証機構を入れてアクセス制限をする
- ・動的にWebAPIを作成、更新、削除ができる
- ・アクセス数に応じてスケールさせる
これらの要件を検討した結果、Google Kubernetes Engine (GKE)を使って、 Kubernetes上でサービスを構築している。
Hekatoncheir Servingの問題点としては、生成したアーティファクト、DockerイメージがきちんとWebAPIとして動くかどうかはデプロイするまでわからないこと。例えば、Dockerファイルに必要なモジュールやライブラリが入っていなかったり、アプリケーションのコードが間違っていたりするなど、何かしらの理由でWebAPIとしてのDockerイメージがきちんと動かない場合がある。それらを発見するタイミングはHekatoncheir Servingの場合はどうしても遅い。
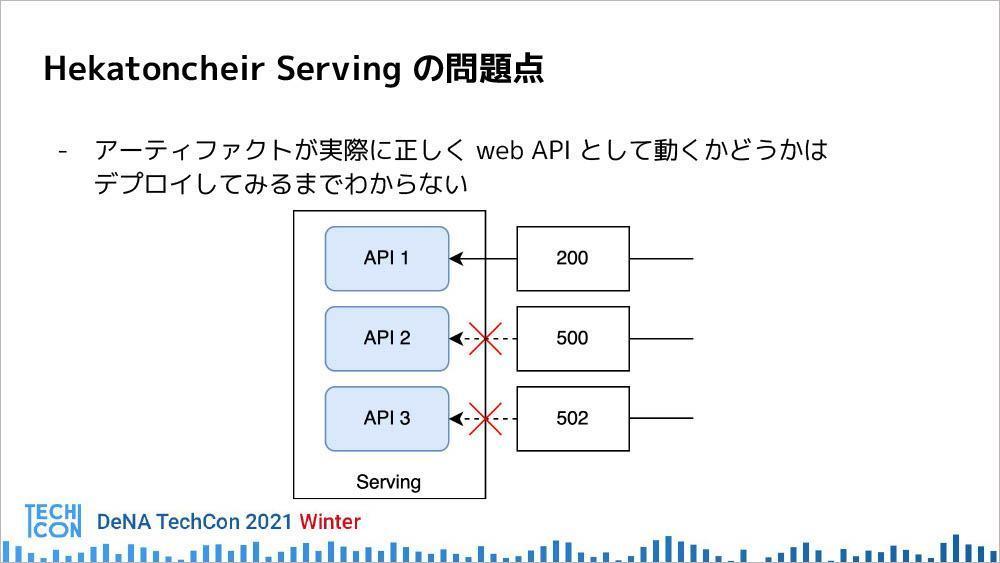
この問題点を解決する方法としてつくられたのが、アーティファクト生成後に有効なWebAPIかどうか確認するために、デプロイしてヘルスチェックする検証機構である。
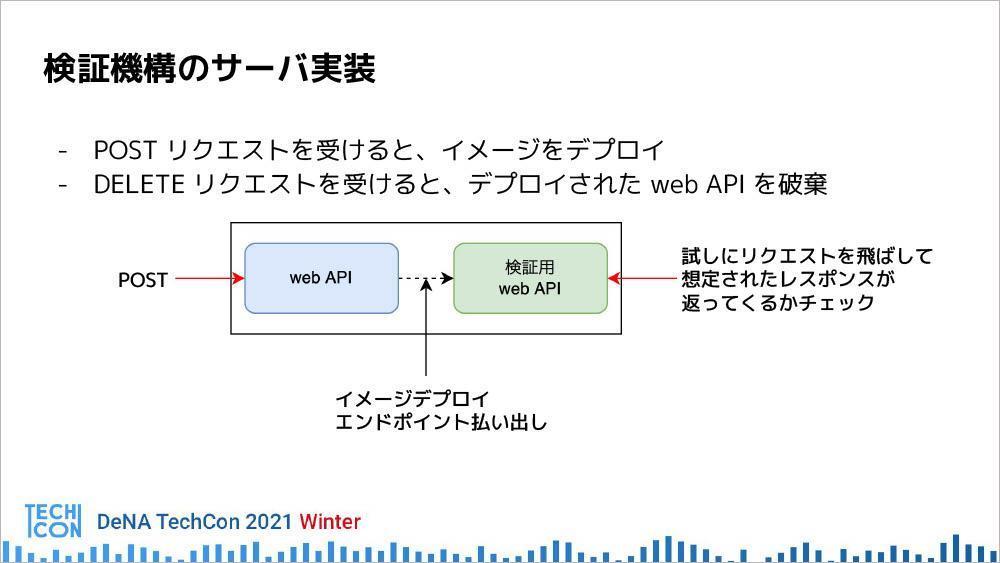
具体的な実装では、内部動作との間にDockerイメージのパスをPOSTリクエストする。Kubernetes上にデプロイされたときに、返ってきたレスポンスと定義されたレスポンスが合致するかどうかを確認し、合致すれば検証成功となる。
もし失敗した場合は、パイプラインを落としてエラーを吐く。検証が終わった後はDELETEリクエストによってWebAPIを破棄するという、非常にシンプルな構成になっている。
「サーバー実装についてはHelmを使っています。レイヤードアーキテクチャによるGo APIのサーバーを作り、そのAPIに対してリクエストすることによって、そのイメージのデプロイで破棄を実現しています」
Servingにどのような技術を使っているのかについても説明が行われた。
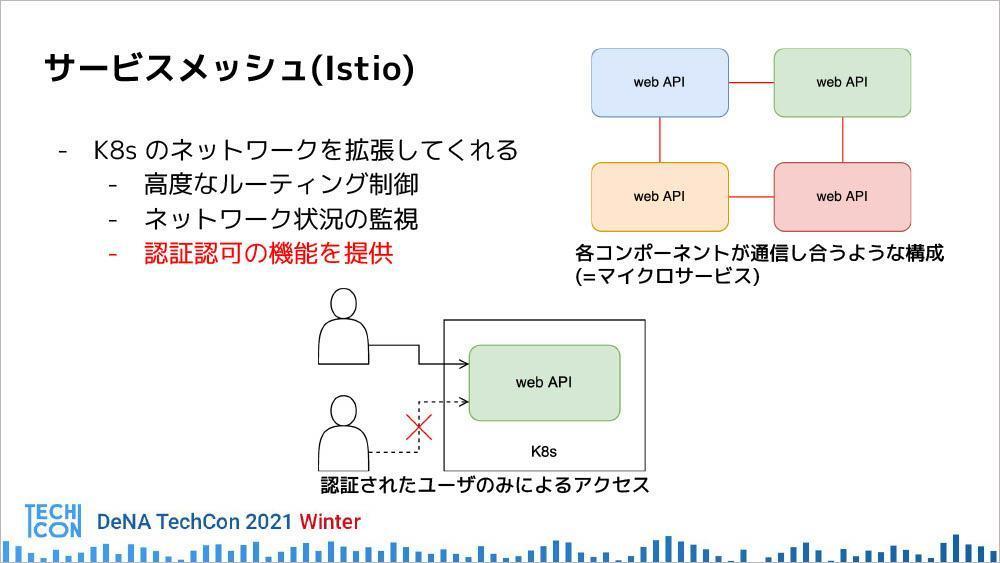
サービスメッシュ
サービスメッシュを入れることによって、高度なルーティング制御、ネットワーク状況の監視、認証認可の機能など、 Kubernetesのネットワークの拡張が実現できる。DeNAでは、Istioを採用。複数のコンポーネントで複雑な通信が行われる場合に有効で、最近ではマイクロサービスなどに活用されている。
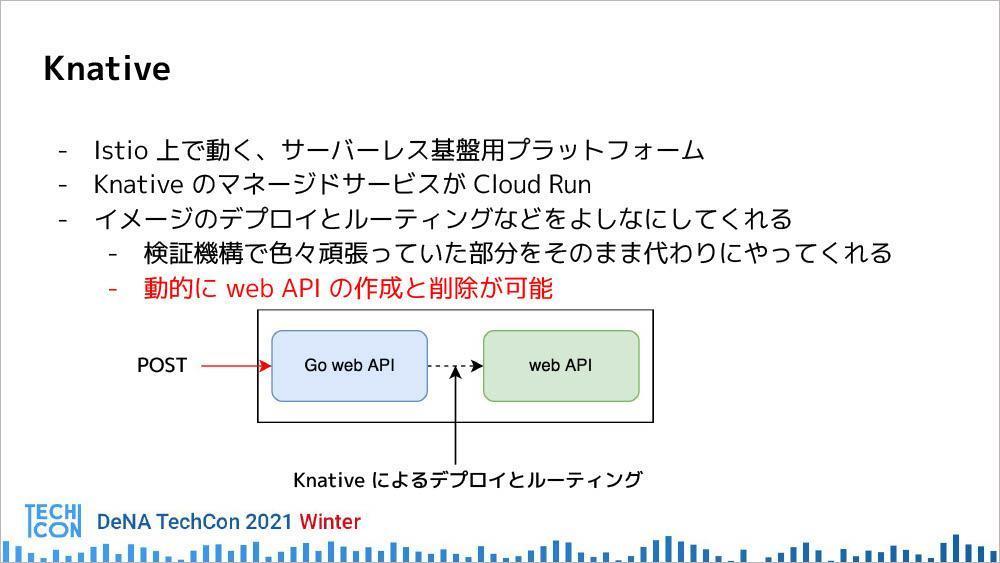
Knative
Istio上で動くサーバーレス基盤用プラットフォーム。KnativeのマネージドサービスがCloud Runであるため、KnativeはCloud Runと同じようなインターフェイスで使えるアプリケーション。Kubernetes上にデプロイしたWebAPIに対して、イメージのデプロイとルーティングをよしなにしてくれる。これを使うことによって、動的にWebAPIの作成と削除が可能となる。
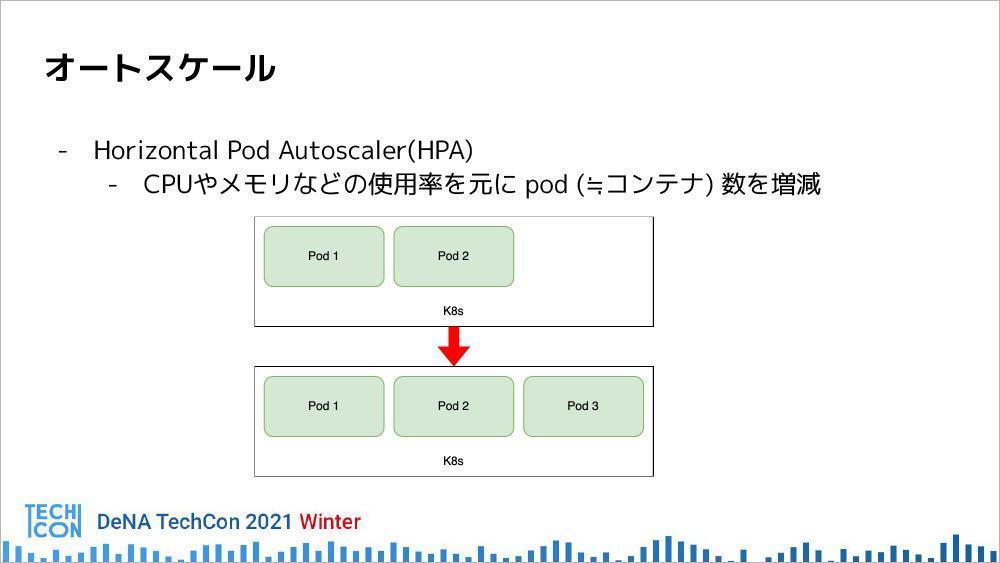
オートスケール
常に大量のトラフィックに備えて、強いサーバーを用意しているとコストがかかるため、トラフィックに応じてサーバーのスケールをアップさせる機能。以下では
- ・Horizontal Pod Autoscaler
- ・Cluster Autoscaler
- ・Node Auto-Provisioning
という3つの機能について説明されている。
Horizontal Pod Autoscaler(HPA)は、CPUやメモリの使用率をもとに、Pod数を増減するオートスケーラーである。
「PodはDockerコンテナとだいたい同じもの。例えば、今二つのPodが動いているとしたときに、トラフィックが増えてCPU使用率が上がってきた場合は、CPU平均を下げるようにPod数を増やす動作をします。逆に、トラフィックが落ち着いてきた場合は、CPU平均使用率が下がってくるので、Pod数を減らす動作を行います」
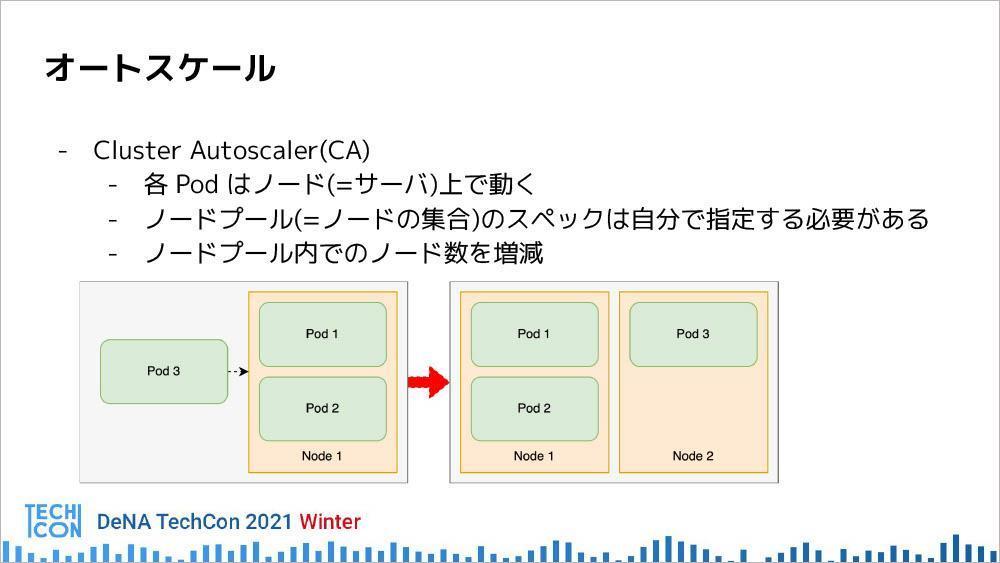
Cluster Autoscalerの場合は、ノードをPodの立ち上げ前にあらかじめ用意する必要がある。同じスペックのノードを指定すると、ノードプールのノード数を自動で増減してくれる仕組みである。
HPAでPod数が増えてきて、あるノードにPodがこれ以上入りきらない場合は、新しくノード増やし、Podが減ってノードが空いた場合はそれを自動で減らすという動作をする。
Node Auto-Provisioning(NAP)は、あらかじめどんなスペックのノードを用意すればいいかわからない場合に有効な手段で、ノードプールそのものを自動でつくってくれる機能である。Podの要求するスペックを考慮し、最適なノードプールを立ち上げてくれるため、Hekatoncheir Servingのシステム構築でも活用しているという。
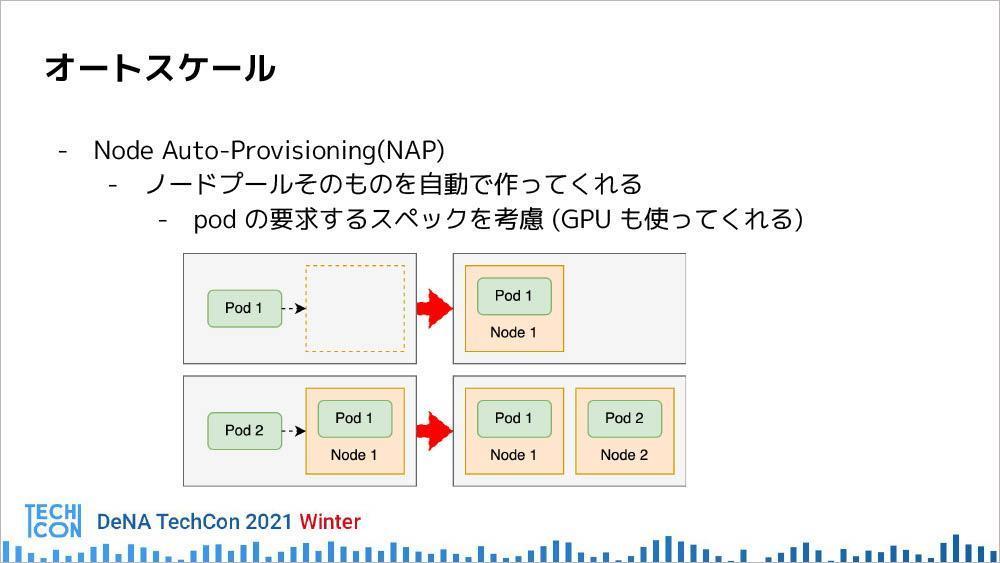
また、実際にHekatoncheirを運用していく上で、様々な課題が出てきたため、現在はリファクタリングや新規開発などを行っているという。
「具体的には、CLIでいろいろな機能を実現するために、WebAPIをつくってサーバー側に処理を移行したり、複雑なユースケースに対応できるように、既存のパイプラインではなく、Vertex Pipelinesと呼ばれるワークフローツールを使って移行しようとしています」
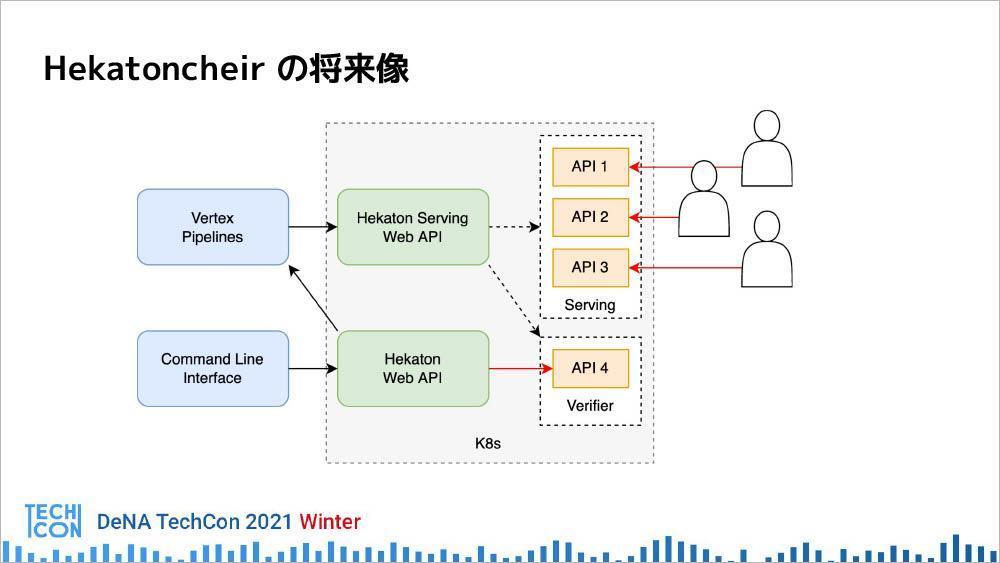
最後に川瀬氏は、Hekatoncheirの将来像となるアーキテクチャを以下の図を示しながら、現在も開発を続行中であることを語り、セッションを締めくくった。
文:馬場美由紀
セッションアーカイブ
関連記事

【DeNA TechCon 2021 Autumn】ヘルスケア、データ分析基盤の効率化、機械学習の活用、データ品質向上、システム開発グループの取り組みをご紹介【イベントレポート】

【DeNA TechCon 2021 Winter】新卒4人が語り合う。DeNAで活躍する技術スペシャリストなエンジニアの仕事・キャリアとは【イベントレポート】

【LINE DEVELOPER DAY 2021】LINEにおけるデータ分析と機械学習開発、属性推定システムリニューアルの事例紹介【イベントレポート】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋

