![]()
最新記事公開時にプッシュ通知します
![]()
普通の映像から“動いている3Dシーン”をリアルタイム生成できる「4D Gaussian Splatting」【研究紹介】
2023年10月18日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
華中科技大学とHUAWEIに所属する研究者らが発表した論文「4D Gaussian Splatting for Real-Time Dynamic Scene Rendering」は、2Dの映像から動的な3Dシーンをリアルタイムで生成する手法を提案する研究である。この技術は2D映像から動くキャラクターの3Dモデルや動的な3Dシーン全体を生成し、単一の視点だけでなく、多くの異なる視点から3Dシーンを閲覧することができる。
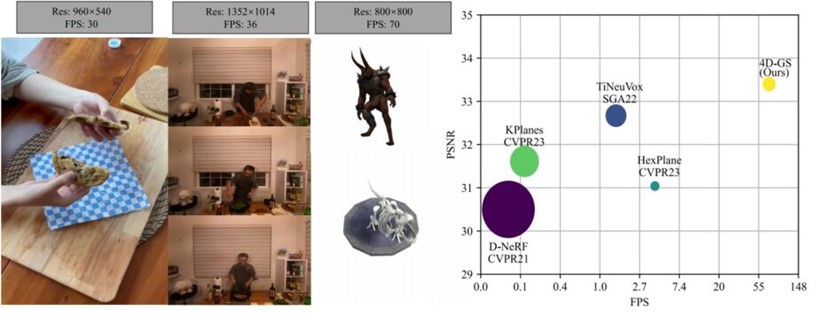
研究背景
「Novel view synthesis」(NVS)とは、既存の画像や動画から新しい視点や角度の画像や動画を生成する技術を指す。特定のシーンや物体の一部の画像を基に、異なる視点からの新しい画像を作成する。NVSの利用により、実際に撮影されていない視点の映像や画像も生成できる。
NVSの代表的な方法として「NeRF」(Neural Radiance Field)がある。これはボリュームレンダリングを活用し、提供された複数の2D画像から3D空間情報を学習し、新しい視点の画像を生成する。しかし、オリジナルのNeRFは学習や画像生成に多くの時間とコストがかかる。一部のNeRFの改良版は学習時間を大幅に削減しているが、画像生成にはまだ遅延がある。
最新の技術として「3D Gaussian Splatting」(3D-GS)が登場している。これは複数の写真から3Dシーンを作成する手法で、3Dオブジェクトやシーンを「3D Gaussian」という点の集合体として表現する。各3D Gaussianは透明度、色、位置などの属性を持ち、これを2D画像上に投影する。
3D-GSを使った最近のモデルでいうと、画像1枚から迅速に3Dモデルを作成する「DreamGaussian」という技術も発表された。これは、1枚のキャラクター画像から、そのキャラクターの3Dモデルを約2分でテクスチャまで含めて生成できる。
このように、3D-GSはNeRFに比べて、処理負荷が低く、高速なレンダリングを実現しながらも高品質な3Dオブジェクトを生成する。しかし、3D-GSは静的なシーンに特化しているので、動的なシーンへの適用は非常に困難である。3D-GSを動的なシーンに利用する際の主な課題として、時間の経過に伴うデータの増加と、それに伴うメモリやストレージの使用量の増加が挙げられる。
利用する際の主な課題として、時間の経過に伴うデータの増加と、それに伴うメモリやストレージの使用量の増加が挙げられる。
研究内容
この課題に対して、この研究では、少ないデータで動的な3Dシーンを効果的にレンダリングする3D-GSを基にしたモデル「4D Gaussian Splatting」(4D-GS)を提案する。この技術を利用すれば、動的な3Dキャラクターやシーン全体をリアルタイムで鮮明に表示することができる。
提案する手法では、3D Gaussianの動きや形を捉える「変形フィールド」という技術を採用している。この中には、HexPlaneという層が組み込まれており、隣接するポイントを接続することで、正確な位置や形の変化を再現する。
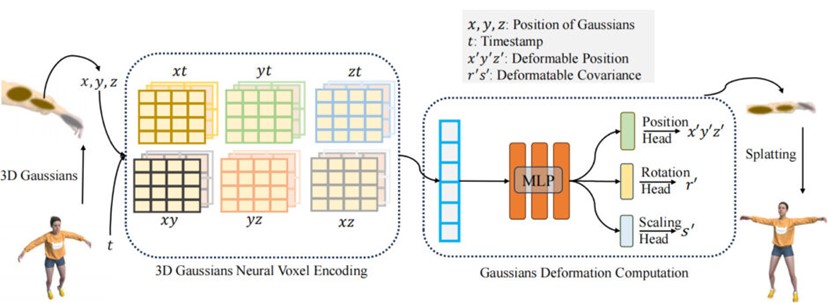
具体的には、初めに多数の3D Gaussianを収集する。これらの3D Gaussianから、各点の中心位置とその時点での時間情報を抽出する。この情報を基に、特定の層で点の属性や特徴を分析する。その後、MLP(多層パーセプトロン)を用いて、これらの特徴を解析し、タイムスタンプに基づいて各点の新しい位置や形を推定する。そして、推定した3D Gaussianを使用して、高品質の3D画像を生成する。
4D-GSは、合成データセットにおいて800×800の解像度で最大70 FPS、実データセットで1352×1014の解像度で36 FPSの成果を上げている。70 FPSでの高解像度の動的シーンレンダリングが可能であることから、リアルタイムでのレンダリングを実現している。そして、既存の先進的な方法に対して、同等またはより優れた性能を保持している。


Source and Image Credits: Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, Xinggang Wang. 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
関連記事

「3D化した顔を巧妙に仮装」 呪文で3Dシーンをスタイル変換するモデル「NeRF-Art」【研究紹介】

3Dシーンの「要らない物」だけを消せる技術「3Dインペインティング」 カナダの研究者などが開発【研究紹介】

テキスト指示からリアルな立体物をつくる多視点拡散モデル「MVDream」 中国バイトダンスなどの研究者らが開発【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


