![]()
最新記事公開時にプッシュ通知します
![]()
テキスト指示からリアルな立体物をつくる多視点拡散モデル「MVDream」 中国バイトダンスなどの研究者らが開発【研究紹介】
2023年9月5日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
中国のバイトダンスと米国カリフォルニア大学サンディエゴ校に所属する研究者らと米国カリフォルニア大学サンディエゴ校に所属する研究者らが発表した論文「MVDream: Multi-view Diffusion for 3D Generation」は、テキストプロンプトから高品質な3Dモデルを生成する多視点拡散モデルを提案した研究報告である。与えられたテキストから、物や風景の多角度の画像を高精度に生成することができる。

研究背景
3Dオブジェクトは、今やゲームや映画、VRなど、多くのメディアで欠かせない要素となっている。しかし、この3Dオブジェクトを作成する過程は専門家が多くの時間を費やすほど難しい。
従来、3Dオブジェクトは主に以下の3つの方法で生成される。(1)テンプレートを基にした方法。(2)3D生成モデル。(3)2Dデザインを3Dデザインに変換する方法。ただ、これらの方法はどれも限界がある。特に複雑で芸術的な3Dオブジェクトを自由に生成することは難しいのが現状だ。
最近では、2DのAIモデルを基にして3Dオブジェクトを生成する新手法も登場している。これは一定の成功を収めているが、完全な3Dの世界を理解していないため、出力される3Dオブジェクトにはしばしば不自然な要素が含まれることがある。ぼやけていたり、欠けていたり、奥行きの整合性が取れていなかったりする。
研究内容
この問題を解決するために提案されたのが多視点拡散モデル「MVDream」である。このモデルは、複数の視点から3Dオブジェクトを考慮することで、より自然で矛盾しない3Dデザインを作成する。具体的には、立体物の周りを歩きながらいろんな角度から見る人間と同じように、この手法もいろんな角度から立体物を見るカメラ位置を考慮する。そのため、多角的に物を見る人間の視点により近い、自然な3Dオブジェクトが手軽に生成できる。

学習は「Multi-view diffusion」(MVDiffusion)と「MVDreamBooth」の2つの主要なモジュールで構成されている。Multi-view diffusionは、2つの方法で学習する。一つは「2D attention」を使って、もう一つは新しい「3D multi-view attention」を使う。つまり、一つ目は平面的な画像に集中して学習し、二つ目は立体的で多角度からの画像に集中して学習する。これにより、多角度の画像をうまく学習することができる。
MVDreamBoothでは、多角度の画像のモデルをさらに良くするために、すでにMVDiffusionで学習したモデルを使い、追加でファインチューニングする。この時にも2D attentionを用いつつ、さらにPreserbation Lossというものを使って、大事な情報を失わないように調整する。これによりモデルの精度を高めることができる。
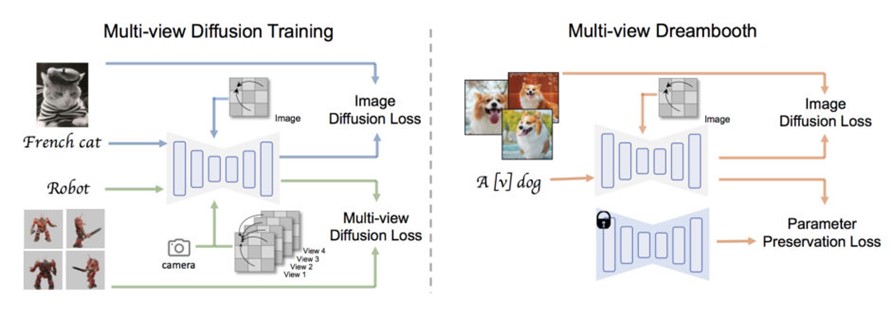
データセットは「Objaverse」の中からCLIPスコアでフィルタリングして、約35万個のオブジェクトに絞ったデータを学習用に使用する。選んだオブジェクトは中央に置かれ、カメラの距離や角度、照明などはランダムに設定される。一つのオブジェクトを32種類の角度(方向)から撮影(レンダリング)し、それを2回行う。このようにして訓練データを増やして学習を行った。

性能テストでは、現在公開されている2Dから3Dに変換する方法よりも、安定して高品質な結果が得られることが示された。しかし、このモデルは最大で256×256の解像度の画像しか生成できない制限と、出力結果がレンダリングされたデータセットに似ている傾向があることが示されており、今後の課題としている。
Source and Image Credits: Shi, Yichun, Peng Wang, Jianglong Ye, Mai Long, Kejie Li and X. Yang. “MVDream: Multi-view Diffusion for 3D Generation.” (2023).
関連記事

「顔を少し若返らせて動画配信」 人の若さ具合を自在に変えられる映像編集ツール、Disneyが開発【研究紹介】

キャラクターの新しい動きを永遠に生成できるモデル「GenMM」テンセント含む研究者らが開発【研究紹介】

手書きした絵コンテの人物画を3Dキャラクターに自動変換する「Sketch2Pose」 不自然なポーズも自動修正【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


