![]()
最新記事公開時にプッシュ通知します
![]()
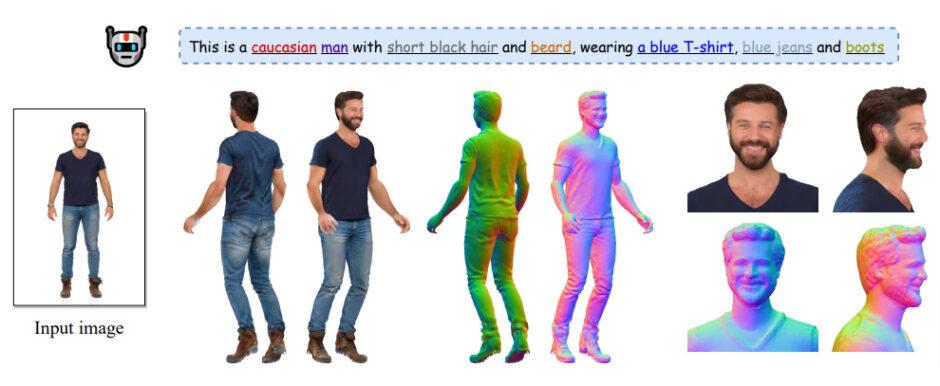
写真1枚から、動かせる着衣3D人体モデルを高精度に生成する技術「TeCH」 DreamBoothなどで「見えない裏側領域」をリアルに復元【研究紹介】
2023年8月21日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
中国の浙江大学やドイツのMax Planck Institute for Intelligent Systemsなどに所属する研究者らが発表した論文「TeCH: Text-guided Reconstruction of Lifelike Clothed Humans」は、全身が写る1枚の写真から高精度の3D着衣人体モデルを生成する手法を提案した研究報告である。背中や後頭部などの見えない領域も一貫したテクスチャとジオメトリを持つ、忠実度の高い仕上がりで生成する。
研究背景
高忠実度の3Dデジタル人間は、ゲーム、ソーシャルメディア、教育、eコマース、没入型テレプレゼンスなど、AR/VRのさまざまな応用にとって不可欠である。これを容易にするため、多くのアプローチが、写真1枚から3Dの着衣人型モデルを再構築することに焦点を当てている。しかし、一枚の画像からの高精細な再構築は、特に「見えない領域」である不可視領域(例:背面)の正確な再現という未解決の課題を抱えている。
不可視領域の予測は、これまでの方法で完全には成功しておらず、ぼやけたテクスチャとともに背面の表面を過度に滑らかに生成してしまうことが多かった。この結果、異なる角度から観察すると矛盾が生じることがあった。
研究内容
この問題に対処するため、新しい手法「TeCH」を提案する。これは、1枚の人物全身画像から詳細な全身ジオメトリと繊細なテクスチャを持つ高忠実度の3D着衣人体の再構築を可能にするという技術である。
具体的には、次の要素から構成される。まずTeCHの核心は、単一の入力画像から得られる意味情報を2つの部分に分割するプロセスである。
1つ目は、Transformerを用いたセグメンテーションモデル「SegFormer」や視覚言語VQAモデルである「BLIP」などで、画像に写る衣服のスタイル、髪型、顔の特徴などをテキストで解釈することである。
2つ目は、個人化されたText-to-Image拡散モデルである「DreamBooth」で細かい外見や特徴を表すための特殊なトークンによる記述不可能な外見情報を解釈することである。これら2つの情報源に基づき、スコア蒸留サンプリング(SDS)と元の観察に基づく再構築の損失を通じてジオメトリとテクスチャの最適化を行う。
次に、高解像度のジオメトリを手頃なコストで表現するために、低解像度3Dモデルから高解像度3Dモデルを合成する「DMTet」に基づくハイブリッド3D表現を提案する。この表現は、全体的な体形と近似する明示的な四面体グリッドと、ジオメトリとテクスチャの微細な詳細を捉えるための符号付距離関数(SDF:Signed Distance Function)とRGBフィールドを組み合わせている。
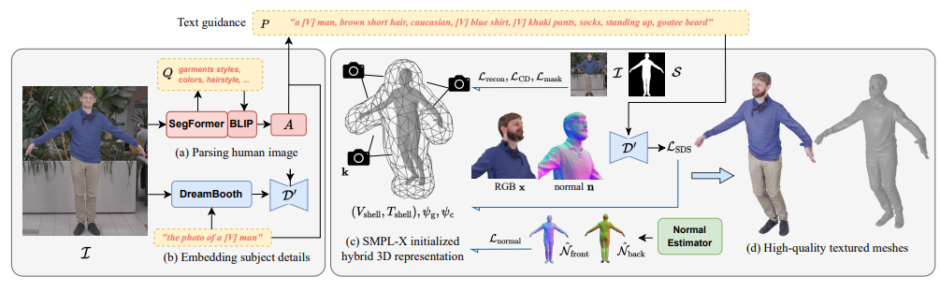
TeCHの性能評価のために、さまざまな実験が実施された。実験において、多様なポーズと服装をカバーする3D人体データセットを使用し、TeCHを用いて3D人体モデルの再構築を行い、最先端技術 (SOTA) と比較した。
実験結果
実験の結果、他の手法と比較して、TeCHは高精細な3D人体モデルのジオメトリをより正確に再構築できるとわかった。具体的には、以前の方法では不可視領域の予測が困難であったが、TeCHは一貫性とパターンを保持しながら高品質なテクスチャとジオメトリの生成に成功した。
定量的評価では、TeCHの幾何学的詳細の再構築における優位性を示した。また、インターネット上にある野生の画像で行われた定性的比較では、レンダリング品質におけるTeCHの優れた性能を更に確認した。

これらの実験結果から、不可視領域の予測の問題を解決し、より一貫したテクスチャと精細なジオメトリを提供する能力が示された。応用による活用として、新規ビューのレンダリング、キャラクターアニメーション、形状・テクスチャの編集など、多岐にわたるアプリケーションが考えられる。
この結果は、TeCHがゲーム、教育、eコマースなどの分野での幅広い応用を促進する可能性を秘めていることを示している。
Source and Image Credits: Huang, Yangyi, Hongwei Yi, Yuliang Xiu, Tingting Liao, Jiaxiang Tang, Deng Cai and Justus Thies. “TeCH: Text-guided Reconstruction of Lifelike Clothed Humans.” (2023).
関連記事

置いてあるモノを“器用”につかむバーチャルハンド 持つ前の予備動作に秘密あり【研究紹介】

キャラクターの新しい動きを永遠に生成できるモデル「GenMM」テンセント含む研究者らが開発【研究紹介】

Adobeなどの研究者らが開発 「動く落書き」を動画内に溶け込むように描ける編集技術「VideoDoodles」【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋

