![]()
最新記事公開時にプッシュ通知します
![]()
虫の細い触角も抜き取れる。画像内の物体を超高精度で背景と分離する技術「HQ-SAM」
2023年6月19日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
スイスのETH Zürichと香港科技大学に所属する研究者らが発表した論文「Segment Anything in High Quality」は、画像内の各物体を背景と分離して識別する高精度なセグメンテーション技術を提案した研究報告である。非常に正確な境界を持つ、より詳細な結果を生成する。

研究背景
画像や映像編集、ロボット知覚、AR/VRなど、幅広いシーン理解において、多様なオブジェクトの正確なセグメンテーションは基本である。数十億のマスクラベルでトレーニングされたSegment Anything Model (SAM) は、一般的な画像セグメンテーションのための基礎的なビジョンモデルとしてMetaから最近リリースされた。
SAMは、点、バウンディングボックス、粗いマスクからなるプロンプトを入力として、様々な場面で幅広いオブジェクト、パーツ、視覚構造をセグメンテーションすることが可能である。そのゼロショットセグメンテーション能力は、シンプルなプロンプトによって多くのアプリケーションに転用できるため、急速なパラダイムシフトをもたらした。
しかし、テニスラケットの網目や昆虫の触覚などの細い箇所は、誤って解釈してしまい、詳細なセグメーションはできない課題が残っている。細い箇所は識別されないか、もしくはその領域全体が解釈できず周辺を巻き込んで識別されるかになる。
研究内容
今回の研究では、SAMの強力なゼロショット能力と柔軟性を損なうことなく、上述した困難なケースでも高精度なセグメンテーションマスクを予測できる「HQ-SAM」を提案する。SAMの効率とゼロショット性能を維持するため、0.5%以下のパラメータを追加する最小限の適応を提案し、高品質なセグメンテーションに機能を拡張する。
SAMデコーダを直接微調整したり、新しいデコーダモジュールを導入したりすると、一般的なゼロショットセグメンテーションの性能が著しく低下してしまう。そこで研究者らは、ゼロショット性能を完全に維持するために、既存の学習済みSAM構造と緊密に統合し再利用するHQ-SAMアーキテクチャを提案する。
具体的には、学習可能な高品質出力トークン「HQ-Output Token」を設計し、SAMのマスクデコーダに注入する。元の出力トークンとは異なり、このHQ-Output Tokenとその関連MLP層は、高品質のセグメンテーションマスクを予測するように訓練される。また、HQ-Output TokenはSAMのマスクデコーダにのみ適用するのではなく、マスクの詳細を改善するために、初期および最終ViTの特徴量とも融合させる。
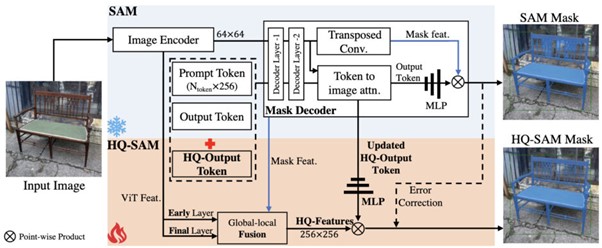
導入した学習可能なパラメータを訓練するために、研究チームは、非常に細かい画像マスクの注釈を含む新しいデータセット「HQSeg-44K」を作成した。HQSeg-44Kは、1,000以上の多様な意味クラスをカバーする高精度なマスク注釈を持つ6つの既存画像データセットを統合することで構築される。
小規模なデータセットと最小限の統合アーキテクチャのおかげで、HQ-SAMは8台のRTX 3090 GPUでわずか4時間で学習することができた。
実証
HQ-SAMの有効性を検証するために、定量的かつ定性的な実験分析を行った。9種類のセグメンテーションデータセット群(COCO、UVO、LVIS、HQ-YTVIS 、BIG 、COIFT 、HR-SODなど)に対してSAMとHQ-SAMの比較を行った。この厳密な評価により、提案するHQ-SAMはSAMと比較して、ゼロショット機能を維持したまま、より高品質なマスクを生成できることが実証された。

Source and Image Credits: Ke, Lei, et al. “Segment Anything in High Quality.” arXiv preprint arXiv:2306.01567 (2023).
関連記事

「他人の“顔”で動画配信」——リアルフェイスマスクを映像内の動く自分に滑らかに適合できる技術 ディズニーなどが開発【研究紹介】

機械学習により交通信号の明滅サイクルを最適化。交通渋滞ランキング3位から57位に改善した「アリババ都市」の取り組み

NewsPicks CTOとデータサイエンティストが語る「サービスの核にレコメンドエンジンを据える」決意と覚悟、リニューアルの全真相
人気記事

5億画素だがUSBポートなし。人間という「デバイス」に接続し、脳内イメージを画像化する技術

React状態管理ライブラリの選択指針:「ローカル/グローバル/サーバー」における使い分けの基準

【2/4(水)オンライン開催!】型定義&インタラクションテストでAIフロントエンド開発のガードレールを整備する


