![]()
最新記事公開時にプッシュ通知します
![]()
風景画から無限に3Dシーンを生成するAI シンガポールの研究者ら「SceneDreamer」開発【研究紹介】
2023年2月15日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
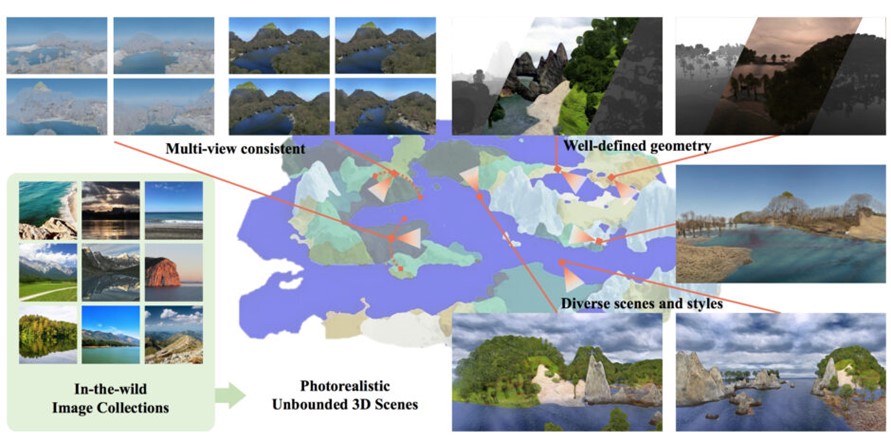
シンガポールの南洋理工大学に所属する研究者らが発表した論文「SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections」は、インターネットで公開されている風景の2D画像コレクションから無限の3Dシーンを生成する手法を提案した研究報告である。3Dの一貫性、明確な奥行き、自由なカメラ軌道を持ち、様々なスタイルの多様な風景を合成することができるという。
研究背景
3Dコンテンツ制作は、メタバースにおける3Dクリエイティブツールのニーズの高まりに対応するため、近年、大きな注目を集めている。3Dコンテンツ制作の核となるのは、2Dの観察結果から3D表現を復元することを目的とした手法である。3Dアセットを作成するためのコストと労力を考えると、その場にある2D画像から生成モデルを学習し、3Dコンテンツを自動で作成することが理想的な1つの形態だろう。
他方で、画像から3Dオブジェクトを生成する研究では、人物やモノなどの領域が決まっているオブジェクトであれば、対象の異なる視点からの複数枚の2D画像データから高品質に復元するモデルが登場している。しかし、任意に広い領域をカバーする鮮明な風景など、インターネットで無造作に公開されている2D画像から無限の3Dシーンを生成するモデルはまだ発展途上である。

研究内容
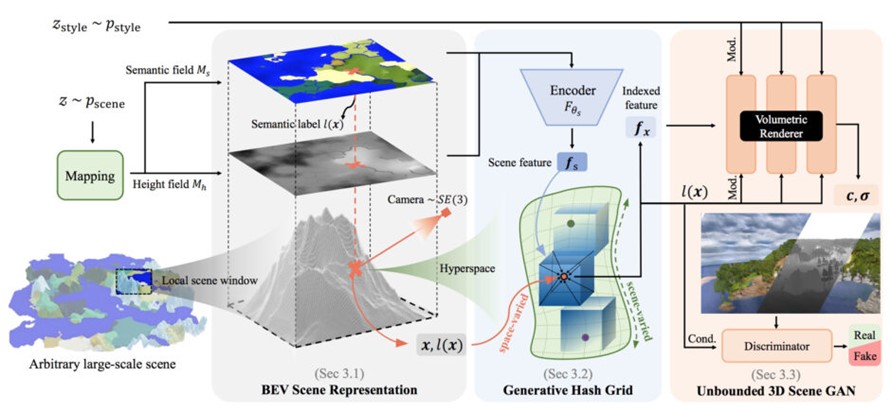
この研究では、3Dアノテーションを一切使用せず、カメラパラメータを持たない2D画像から無限の3Dシーンを生成することを学習するフレームワーク「SceneDreamer」を提案する。
目的は、実環境の2次元画像コレクションのみから、無境界3次元シーンのための生成モデルを学習することである。そのために「BEV Scene Representation」、「Generative Hash Grid」、「Unbounded 3D Scene GAN」という3つのモジュールからなるシステムを提案する。
BEV Scene Representation
まず「BEV Scene Representation」では、効率的な3次元点のサンプリングと学習を目的として、高さフィールドとセマンティックフィールドからなるBEV(鳥瞰図)シーン表現を導出する。高さフィールドは3Dシーンの表面の高さを表し、セマンティックフィールドはシーンの詳細な意味付けを示す。
Generative Hash Grid
次に「Generative Hash Grid」ではNeural hash gridという手法を用い、敵対的学習を容易にするために、シーン表現を潜在的空間に空間変動潜在特徴とシーン変動潜在特徴を用いてパラメータ化する。
Unbounded 3D Scene GAN
最後に「Unbounded 3D Scene GAN」では、スタイルベース生成器を用いて、3次元点の潜在的特徴をブレンドし、ボリュームレンダリングにより2次元画像を描画する。
一度学習が行われれば、無条件に多様な3Dシーンを生成することが可能である。また生成される景観の照明、天候、スタイルなどの変更もできる。
評価実験
評価実験のために、インターネット上に存在する1,135,662枚の自然画像から、「風景」をキーワードとする大規模なデータセットを作成した。暗すぎる画像、一般的でない比率の画像、グレースケールの画像などは除去している。
実験では、様々な最先端の3D生成モデル(GANcraft、EG3D、InfiniteNature-Zero)に対して定量的・定性的なテストを行なった。その結果、どのモデルよりもSceneDreamerの方が、3D形状の正しさとビューの一貫性を維持する能力を示し、精度の高さを示した。

Source and Image Credits: Chen, Zhaoxi, Guangcong Wang and Ziwei Liu. “SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections.” (2023).
関連記事

カメラ1台で多人数の全身の動きを3Dモデルで復元する技術 背景の3Dシーンも一緒に再現【研究紹介】

スマホを90度に曲げ、奥行きをリアルに感じながら立体物を編集できる3Dモデリングツール「AngleCAD」【研究紹介】

【動く城のフィオ】物理現実を「捨てた」僕がメタバースで東京をつくった理由 バーチャルで送る「セレクテッドな人生」とは
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


