![]()
最新記事公開時にプッシュ通知します
![]()
顔のみをアニメ風にして動画配信。動く人の顔を高品質に漫画化するスタイル転送技術「VToonify」【研究紹介】
2022年10月12日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
シンガポールのNanyang Technological Universityの研究チームが発表した論文「VToonify: Controllable High-Resolution Portrait Video Style Transfer」は、ポートレートビデオ内の人物の顔を高解像度にToon化(Cartoonの簡略化表記で漫画やアニメを指す)する学習ベースのスタイル転送フレームワークを提案した研究報告だ。人物のアイディンティーを保持しながら顔のみをアニメ風に変換し、頭部の動きによる乱れも少なく高解像度での出力を可能にする。

研究背景
静止画像ベースのスタイル転送のために設計されたアプローチは数多くあり、その多くはモバイルアプリケーションという形で誰でも簡単にアクセスできるようになった。また深層学習技術の出現により、ポートレートスタイルの自動転送を通じて、実顔画像から高品質のポートレートをレンダリングできるようになった。
この潮流は動画にも派生し、動画内の動くポートレートにもスタイル転送できるようになった。ここ数年、動画コンテンツは急速にソーシャルメディアの主役となり、ポートレートビデオのスタイル転送のようなビデオ編集に対する需要も増加した。
研究内容
既存のビデオベースのスタイル転送技術の多くは、静止画像ベースのスタイル転送技術(StyleGANなど)を動画に適応したアプローチを採用しているため、固定のフレームサイズ、顔の位置合わせ、顔以外の詳細の欠落、時間的不整合など、出力結果の品質に制限があり、課題として残っている。
本研究では、これらの課題に挑戦するために、「VToonify」と呼ぶ新しいフレームワークを導入して制御可能な高解像度ポートレートビデオのスタイル変換を検証する。今回の手法は、画像変換フレームワークとStyleGANを用いたフレームワークの2種類を活用したハイブリッドフレームワークを採用する。

画像変換フレームワークは可変入力サイズに対応しているが、ゼロから学習させるため、高解像度かつ制御可能なスタイル転送が困難である。一方でStyleGANベースのフレームワークは、事前に学習されたStyleGANモデルを活用し、高解像度で制御可能なスタイル変換を実現するが、固定画像サイズとちらつきなどのアーティファクトが目立ってしまう。
これらの2つの短所を補い、両者の長所を活かしたハイブリッドフレームワークに仕上げたのが今回となる。
高品質なポートレートをレンダリングするために、これまでと異なりStyleGANの低解像度層を取り除いた最上位11層(中・高解像度レイヤー)のみを使用する。条件としてスタイルコードに加えて、エンコーダーからのマルチスケールコンテンツの特徴も条件とする。学習段階では256×256の画像を入力として使用し、テスト段階ではFCN(Fully Convolutional Network)が様々なサイズのフレームを受け入れる。
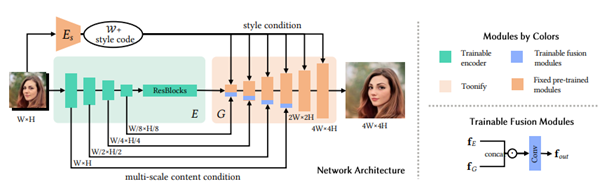
これによって低解像度の入力から高解像度のスタイル付き動画を合成することができるようになる。出力した顔画像は、動きに伴って発生する歪みやちらつきを抑えた高品質な画像が生成され、入力フレームのアイデンティティーを保持したフレームで高解像度にレンダリングされる。特に髪の毛などの顔以外のオブジェクトに対して画像の詳細をよりよく再構成でき、またStyleGAN固有の制限である固定解像度と整列した顔を克服する。
さらに、スタイルの適応レベルをどれくらいにするかのパラメーターをユーザーが自在に調整することもできる。
このフレームワークのアイデアは、顔のスタイル変換に限らず、画像の超解像や顔の属性編集など、他の画像や映像の編集作業にも応用できる可能性もあるという。
Source and Image Credits: Yang, Shuai, et al. “VToonify: Controllable High-Resolution Portrait Video Style Transfer.” arXiv preprint arXiv:2209.11224 (2022).
関連記事

「合成脳」10万枚を公開 画像生成AIで脳のMRI画像を医療用に大量生成 欧米の研究者らで実施【研究紹介】

3Dモデルの質感を好きな画風に変えられるスタイル変換モデル NVIDIAなどが開発【研究紹介】

1枚の写真から作成する動くメガピクセル頭部アバター。ロシアチームが開発【研究紹介】
人気記事

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理

国産組込みOS「ITRON」が40年生き残ってきた理由を、生みの親と振り返る【TRON】

インデックスを張るだけでは足りない。数億件の名刺データを扱うSansanのSQLパフォーマンス改善


