![]()
![]()
文章からアバターの動きを生成するAI「MotionDiffuse」 シンガポールと中国の研究者らが開発【研究紹介】
2022年9月21日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
シンガポールのNanyang Technological Universityと中国のSenseTimeの研究チームが開発した「MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model」は、入力したテキスト(自然言語)に応じてアバターの動きを生成する学習ベースのシステムだ。より忠実な動きが出力されるだけでなく、パーツごとの操作と長時間のシーケンス生成を可能にする。
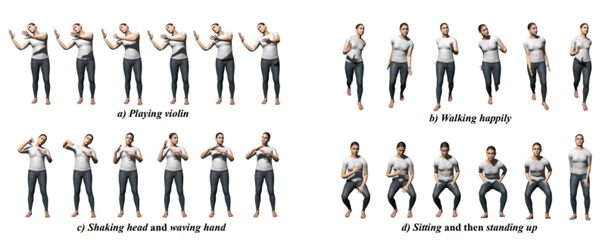
研究背景
ヒューマンモーションモデリングは、バーチャルキャラクターのアニメーションに不可欠な要素であり、映画製作、ゲーム開発、バーチャルYouTuberのアニメーションなど、多くのアプリケーションで重要なトピックとなっている。
人間の動きを模倣するためには、バーチャルキャラクターが自然に動き回り、環境との相互作用に反応し、洗練された感情を表現する必要がある。しかし、生き生きとした本物の体の動きをつくり出すには、高価なモーションキャプチャーシステムなどの高度な機器と専門家が必要となる。素人でも操作できるようにするためには、簡単に制御できるモーションシーケンスを生成できる汎用的なヒューマンモーション生成モデルの構築が不可欠である。
研究過程
本研究では、中でも使いやすいテキスト駆動のモーション生成に焦点を当てる。これまでにも類似研究は報告されているが、短いテキスト入力に限られて複雑なモーション記述に対応できなかったり、単一のテキストプロンプトしか受け付けないため1つの動作しか生成できず、ユーザーの創造性を制限していたりで課題も多かった。
これらの課題に対して今回は、高忠実度で制御可能なテキスト駆動型モーション生成のための拡散モデルベースのフレームワーク「MotionDiffuse」を提案する。
提案するフレームワークは、近年のテキスト条件付き画像生成の進展に触発され、Denoising Diffusion Probabilistic Models(DDPM)を取り入れている。固定サイズしか生成できない古典的なDDPMとは異なり、本手法はCross-Modality Linear Transformerを提案して任意の長さのモーション合成を実現する。
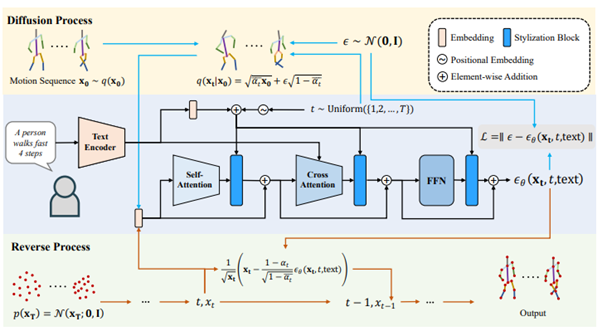
テキスト駆動型モーション生成の直接的な応用にとどまらず、もう一歩踏み込んで、ノイズ除去時のモーション表現を条件とした手法の探索を行う。具体的には、「身体部位を考慮したテキスト制御」と「時間変化制御」の2つを検討する。
前者は体の部位ごとに異なるテキスト条件を割り当てることで、各部位を正確に制御し、より複雑な動作シーケンスを生成する。後者は、シーケンス全体をいくつかの区間に分割し、それぞれの区間に独立したテキスト条件を割り当てる。そのため、複数の動作を組み込んだ任意の長さの動作シーケンスを合成できる。この2種類の条件により、MotionDiffuseの機能は大幅に拡張される。
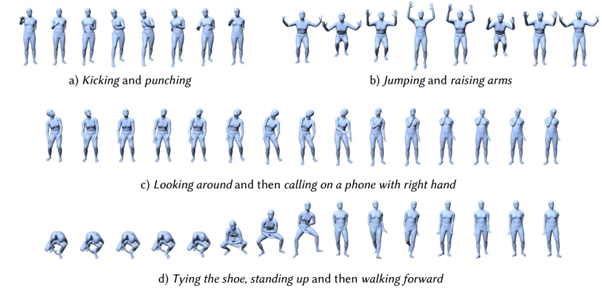
研究結果
一般的なベンチマークを用いた広範な定性的実験と、包括的なモーション生成に関する定量的評価の両方を実施した。その結果、まずHumanML3DとKIT-MLにおいて、テキスト駆動型モーション生成の大幅な改善を実証した。次に、MotionDiffuseの優位性を示すために、アクション条件付きモーション生成タスクに直接適用し、HumanAct12データセットとUESTCデータセットにおいて、全ての既存モデルを上回る性能を発揮した。
さらに身体部位レベルの操作と長いモーション生成を可能にする制御モデルを条件付けることで、MotionDiffuseの更なる可能性を示した。
Source and Image Credits: Zhang, Mingyuan, et al. “MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model.” arXiv preprint arXiv:2208.15001 (2022).
関連記事

「コード」から「漫画」を自動作成するツール「CodeToon」。カナダの研究者らが開発【研究紹介】

1枚の写真から作成する動くメガピクセル頭部アバター。ロシアチームが開発【研究紹介】

3Dモデルの質感を好きな画風に変えられるスタイル変換モデル NVIDIAなどが開発【研究紹介】
人気記事

完全ペアプロは「やりすぎ」だった。失敗を経て辿り着いた、ペアプロ×開発組織の最適解【Tebiki渋谷】

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

より価値の高いソフトウェアを開発するために。C++エキスパート・高橋晶が薦める、C++の技術書5選


