![]()
最新記事公開時にプッシュ通知します
![]()
SNSを通じた「ギブ&テイク型情報収集術」と、後悔しない技術選定を叶える方法【DBエンジニア|こば】
2024年5月8日


データベースエンジニア/DBソムリエ
こば -Koba as a DB engineer-(@tzkb/小林隆浩)
基盤担当のエンジニアとして様々なプロジェクトで経験を積み、中でもデータベースに関する設計、運用、トラブルシューティング等を専門とする。得意とするDBMSはOracle DatabaseおよびPostgreSQL。オライリー社刊行・書籍「詳説 データベース」監訳者。itmediaにてクラウドネイティブなDBやNewSQLに関する連載を持つ。
技術や業界など仕事についての情報収集の基盤として多くのエンジニアを支えていたTwitter(現X)が、以前とは異なる姿となってゆく今、必要な情報を過不足なく収集しインプットする方法に悩みを持つ人も少なくありません。
「アフターTwitter時代の情報収集」と題したこの連載では、業界をリードする方々に、Twitterの変化によって普段の情報収集の方法がどう変わったか、欲しい情報を効率よく集めるために何をしているのかを取材します。
第5回は、データベースエンジニア・こばさんこと小林隆浩(@tzkb)さん。書籍「詳説データベース」の監修と翻訳を担当しており、データベース関連の国内外のカンファレンスでの登壇やitmediaでの記事連載など幅広く活躍しています。
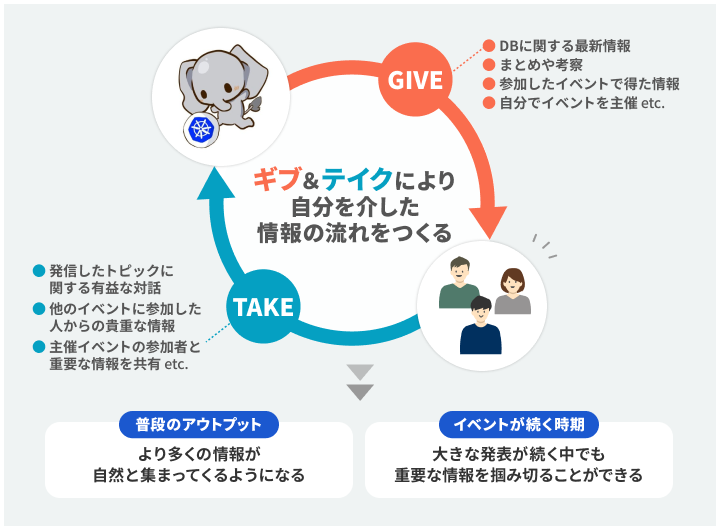
こばさんは「自分だけで必要な情報を集め切ることは不可能。だからギブアンドテイクで、“自分に情報が集まってくる流れ”をつくっている」と語ります。情報が集まってくるとは、どういうことなのでしょうか?データベース技術選定を担うエキスパートとしての審美眼の鍛え方とともに、詳しく聞きました。
- Xは「オープンなブックマーク」自然と情報が集まってくるようになる
- 情報の「ギブアンドテイク」で、イベントラッシュでも重要情報を漏れなくチェック
- 最適な技術を選ぶには「今と未来」を正しく捉えること
- アウトプットは「よりよいインプット」のためにある
Xは「オープンなブックマーク」自然と情報が集まってくるようになる
――Twitterの騒動で、情報収集の方法に変化はありましたか?
こば:情報収集の方法には特に変化はないですね。以前からずっとTwitter(現X)を活用しています。ただ、2023年7月以降から徐々に、Twitter上で情報発信をしていた個人やコミュニティの一部が、Twitterを離れていってしまいました。離れた人を追いかけようと、私もBlueskyのアカウントを取得したものの、あまりチェックできていません。複数のSNSを使い分けるのは個人的に得意ではないようです。
――最新情報は、どんな分野の情報を、どうやって追いかけていますか?
こば:RDB(リレーショナルデータベース)や分散データベースなどDB関連の技術については、最新情報を逐一追いかけています。
海外のクラウドベンダーやデータベースベンダーのX公式アカウントによるポストや、それを紹介するエンジニアのポスト、それらのベンダーで勤務しているエンジニアのポストなどを主にチェックしています。ポストで引用されている公式発表や、公式の技術blogなどを読み、今使っている技術や類似サービスと比較しながら「このサービスが解決したい課題は何なのか」「今回のアップデートのどこに新規性があるのか」「どんなユースケースで使うべきか」などと深堀りしていきます。
インプットした情報やその過程で考えたことは、思考の整理と備忘のために一旦Xに吐き出すようにしています。過去に見た情報が必要になったときには、自分のpostを遡ればいろいろヒントが見つかります。Xでのポストをブックマークのように使っていますね。

――オープンなアカウントをブックマークとして使うのは憚られるような気もしますが、どんなメリットがあるのでしょうか。
こば:オープンなXアカウントでpostすることで、「私はデータベース関連の情報に興味があります」と発信することができます。すると、私の発信を見た人から、私が発信していない情報があれば「これはどうですか」と、私の理解が誤っているときには「それはこうなのではないか」と教えてもらえます。その際、もらった情報への私なりの解釈を伝えて対話し、理解を深めていきます。こうしたやりとりを見たさらに別の人にも「こばはデータベースに興味があるんだ」と伝わっていき、もっと多くの情報が自然と集まってくるようになります。いつのまにか関心がある分野の技術情報が、自分を通して流れていく状況が生まれるのです。
発信を始めてから「良い流れができている」と感じるまでは、およそ1年くらいでしょうか。初めてそう感じたのは、カンファレンスやコミュニティの参加者の中に、元々知っている人が増えてきたり、Xでの発信をきっかけに執筆や登壇の依頼を受けるようになってきた頃でしたね。
情報の「ギブアンドテイク」で、イベントラッシュでも重要情報を漏れなくチェック
――常にアウトプットし続けることが、しんどく感じてしまうときはないのでしょうか。
こば:日々のアウトプットといえば、私が業務上役立つと思った情報のブックマークをXでただ公開しているだけなので、そもそも「アウトプットしなくちゃ」と気を張ることがあまりないですね。
イベント登壇が決まれば、その準備は当然大変ではあります。とはいえ、登壇時に話す内容を組み立てることで現時点での理解を整理できますし、実際に登壇して話すことで、それに対する反応としてまた新たな情報が得られるチャンスでもあります。準備するしんどさよりもっと大きなものを得られるとわかっているので、モチベーションに困ることはあまりありません。
――日々のアウトプットで確立した「情報が自分を通って流れていく仕組み」に助けられるのは、どんなときですか。
こば:データベース関連技術の大きな発表が続く中でも重要な情報を掴み切りたいときに、特に助かっています。
この業界では1年の中で、様々な技術についての大きな発表が連続し、膨大な情報を短期間でインプットしなければならない時期があります。例えばベンダーの年次イベントがあるときや、毎年ある定番DBMSのバージョンアップ時期などには、blogやXなどで情報が活発に流れるようになります。重要な情報を掴み切るために、自分が行けなかったイベントのハッシュタグを追いかけたり、参加したエンジニアとコミュニケーションしたりはしていますが、多数開催されるイベント全てにそうした動きをとりきるのは大変です。
そんなときには「情報が自分を通っていく流れ」をつくるために、自分が参加したイベントで得た情報をXやblogに投稿しています。イベントに行った自分が持っている「行かないとわからなかった情報」を提供するのです。こうしておくと、他のイベントに参加していた人に「そちらではどうでしたか」と聞きやすくなるし、「こちらはこうでした」と貴重な情報を教えてもらえるようになります。
また、自分でイベントを主催することで、重要な情報を一気に集めることもできます。たとえば「2023年のクラウドベンダーの注目発表(DB編)」などその年の重要情報を包括できるようなテーマでイベントを主催し、多くの人が一気に情報を共有できる機会をつくります。参加者と発表し合えば、自分も参加者も一緒に、重要な情報を抑えることができます。
こうした情報のギブアンドテイクによって、自分を介した情報の流れをつくることで、本当に重要なポイントを取り逃さないで済んでいます。
最適な技術を選ぶには「今と未来」を正しく捉えること
――こばさんが専門としている、エンタープライズ領域のデータベース関連の情報を集めるにあたって、大切なことは何でしょうか。
こば:サービスにおいて、現在の時点でできることと、これからできるようになることを把握しておくことです。
データベースエンジニア、特に私のように技術選定を担う立場は、自分が関わるプロジェクトにとって「今すぐ便利に使えて、将来もっと便利になるサービス」を適切な時期に組み込まなくてはなりません。そのためには目当てのサービスの現状と将来像を確度高く捉えておくことが非常に重要です。
――サービスの現状と将来像は、どうやって掴んでいますか?
こば:現状のサービスの特徴を的確に掴むには、自分の手で動かしてみるのがやはり有効です。Get Startedのドキュメントを読みながらサービスを実際に動かし、気になった機能を検証して、不明点があればベンダーに質問したり、ソースコードが公開されていればそれを読んだりしています。クラウドベンダーが提供しているサービスで、ソースコードが公開されていない場合は、そのサービスに使われている技術についての論文を読むこともあります。
もちろん、気になっている全てのサービスにこのようなプロセスを全てやりきるには、時間が足りません。そのため、私と同じような課題感を持つエンジニアをX上でフォローして、彼らの検証結果やサービスを利用した際の感想などを読むことで、上記の一部をスキップすることもあります。ただ「誰かから聞いた話」ではどうしても、自分の手で試すより情報の密度は薄まるので、サービス導入を決める前には必ず自分で試しています。
一方、将来像を捉えるときは「現時点の機能は今後も継続的に使えるかどうか」「サービスの未来像は、自分が関わるプロジェクトの未来像と合いそうか」という2点に着目しています。
今ある機能が今後も使えるのかどうかについては、あるサービスが新しい機能を発表した際に、それがGeneral Availabilityで一旦Fixしたものなのか、それとも正式リリースまでに大きく変わるものなのかを、公式ドキュメントを読み込んだり、ベンダーに直接質問したりして確認しています。
サービスの未来像を捉えるためには、自分が関わるプロジェクトの未来像を頭に入れておいたうえで、サービスのロードマップを読み込んでいます。ロードマップから「このサービスはどんな課題をどう解決することを目指しているのか」「これからどうなっていくのか」を読み取ったうえで、そのロードマップの実現可能性はどの程度なのかを予想しています。ロードマップは各サービスのWebサイトに掲載されているので、すぐチェックできます。実現可能性についても「この機能は今は東京リージョンでは使えないけど、米国では使える。東京でもすぐに使えるようになるだろう」といったように、各リージョンのサービス内容を比較することで推測できます。
こうしてサービスの現在と未来を正確に捉えておけば、自分が関わるプロジェクトの未来像とも照らしあわせて、短期的にも中長期的にも最適な技術選定ができるようになると考えています。

――より確度の高い情報を集めるために、どんな工夫をしていますか。
こば:知らないことが少ないほど、情報の確度は高まります。私は、知らないことを減らすために「ベンダーがわざわざ公表していない、今のサービスが選ばれるのに不利になるような情報」を見逃さないように工夫しています。
1つは、似た機能を持つ複数のサービスを比較して、公式がオープンにしていない情報があるかどうかを探っています。まず、各サービスの公式ドキュメントをチェックし、同じ機能についての記載を見比べます。すると多くの場合に「サービスAとBは同じXという機能があるが、AにはXの補助機能にあたるYについての記述があるのに、Bにはない」といった違いが出てくる。この場合、BにはYを実装できない事情、つまりオープンにしていない情報があるのかもしれない、と類推できます。
もう1つは、公式ドキュメントに書いていない情報を知るために、日頃からサービスのベンダーとのコミュニケーションをとるようにしています。私はよくベンダーとの打ち合わせに同席して、ベンダー側のエンジニアと話しています。疑問に思っていたことを聞くこともできますし、サービスの課題や望む機能などを伝えたりしておくと、伝えた課題の改善が新たなリリースに含まれているかなど、こちらが調べて辿り着くしかないような情報も教えてもらえます。日頃から双方向のコミュニケーションをとって関係性をつくっておくことで、質の高い情報を得る準備ができるのです。
アウトプットは「よりよいインプット」のためにある
――情報収集において大切にしているモットーやこだわりを教えてください。
こば:「インプットのためにアウトプットすること」です。
情報は、アウトプットする人のところに集まってくると考えています。エンジニアにとってアウトプットは、技術情報を誰かに伝えることが目的であると思われがちです。でもそれだけでなく、後々のインプットの布石として「あなたは何者で、何に関心があるのか」を伝えるチャンスだとも思っています。
アウトプットする情報の正確性にこだわり続けることで、集まってくる情報に対する審美眼も磨かれます。質の高いアウトプットはメディアでの執筆や講演依頼などに繋がり、露出が増えることでさらに多くの情報が集まってきます。私自身も道半ばですが、自分のもとに集まってくる情報をどんどんシェアすることで、データベース関連技術情報における「知の高速道路」を整備できるように努力したいと思っています。
取材・構成:光松瞳
編集:王雨舟
関連記事
「Real World HTTP」著者・渋川よしき氏が「最新情報は追わない」と断言する理由

情報の海をハックするカギは「捨てる」こと。LayerX松村氏に学ぶ、価値ある情報を取りこぼさないコツ

継続のコツは「わざわざ見に行く」をなくすこと。はてなフロントエンドエキスパートmizdraの情報収集術
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


