![]()
![]()
情報の海をハックするカギは「捨てる」こと。LayerX松村氏に学ぶ、価値ある情報を取りこぼさないコツ
2023年12月20日


株式会社LayerX 機械学習・データ部 機械学習グループ マネージャー
松村 優也
1993年生まれ。2018年3月、京都大学大学院情報学研究科 社会情報学専攻修士課程修了。在学中の起業経験を経て、新卒でウォンテッドリー株式会社に入社、推薦システムチームの立ち上げに関わる。2021年にはWantedly VisitのPdM、開発組織のEMを兼任。2022年9月に株式会社LayerXに機械学習エンジニアとして入社。2023年には機械学習チームのリーダー、現職に就任。
技術や業界など仕事についての情報収集の基盤として多くのエンジニアを支えていたTwitter(現X)が、以前とは異なる姿となってゆく今、必要な情報を過不足なく収集しインプットする方法に悩みを持つ人も少なくありません。
「アフターTwitter時代の情報収集」と題したこの連載では、業界をリードする方々に、Twitterの変化によって普段の情報収集の方法がどう変わったか、欲しい情報を効率よく集めるために何をしているのかを取材します。
第2回は、LayerX社で機械学習チームのマネージャーを務めながら、副業でWantedly社の推薦システムにおける技術顧問としても活躍している松村優也さん。2022年5月には、オライリー社より「推薦システム実践入門 ―仕事で使える導入ガイド」を共著で上梓し、LayerX入社後にはOCRやLLMにも活躍の幅を広げています。
新しい技術が目まぐるしく現れる機械学習領域で、情報の海に溺れず、本当に価値のある情報を得るために、松村さんは何をしているのか? お話を聞きました。
※旧Twitterについては、以下「X」と表記します。
- Xの仕様変更と「AI」のバズワード化で、有益な情報が流れてきづらくなった
- 朝食とともに大量の情報を仕分け、通勤中やランチ休憩でじっくり読む
- 「この情報は不要だ」と感じたら、どんなに集中して読んでいても即やめる
- 結局一番大切なのは「無理せず、継続すること」
Xの仕様変更と「AI」のバズワード化で、有益な情報が流れてきづらくなった
——Xの買収騒動を経て、情報収集の方法に変化はありましたか?
松村:情報収集の方法自体は大きく変わってはいませんが、Xで得られる情報の質のブレが大きくなっていると感じています。以前からXを情報収集の主軸としているのですが、「おすすめ」タブに流れてくる情報のうち、自分にとって有益なものの割合が減ったように感じます。
買収騒動を受け、今までつぶやきを追いかけていた一部ユーザーがXから離れてしまった上に、2023年2月あたりから「AI」「LLM」がバズワード化したことで、それに関連する情報を投稿するインフルエンサーが増えました。さらに、Xの仕様変更で、外部リンク付き投稿のインプレッションが下げられるようになったんです。
その結果、すでに影響力を持っている方や、発信がうまいインフルエンサーの発信は「おすすめ」タブで頻繁に見かけるものの、「フォロワーは多くないが良質な情報を発信している人」の発信が自分の元に届きにくくなった印象があります。
——Xの代わりを探したりもしているんでしょうか?
松村:「いつかXが情報収集のツールとして使い物にならなくなるかも」という危機感はあるので、代替手段は常に探しています。ただ今のところ、Xほど最新情報をタイムリーに得られるサービスはまだ見つかっていません。変わらず利用はしていますが、情報の質の見極めをより注意深く行うようになりました。
朝食とともに大量の情報を仕分け、通勤中やランチ休憩でじっくり読む
——最新情報は、どんな分野の情報を追いかけていますか?
松村:目の前の仕事に直結するような技術領域や、自社と近しい事業領域の企業の動向などの最新情報は意識的にインプットするようにしています。
私はLayerXで機械学習チームのマネージャーを担当しているので、基本的に機械学習関連の情報なら、論文から活用事例まで積極的にインプットしています。最近では、文書からの情報抽出や読解などを行うDocument AIと呼ばれる領域に特に注目しています。それとLLM関連の情報にも関心が高いです。
これらの技術はトレンドになっていることもあり、とにかく変化が速い。私は最新技術を使いこなせる状態で居続けたいので、新しい技術が出るたびに、その技術が生まれた背景や技術構成を都度勉強するようにしています。
——新しい技術が出るたびに背景から学び直すのは、大変ではありませんか?
松村:常にアンテナを張って追い続けるのは大変なときもあります。ただ、一度追いかけるのをやめてしまうと、その間の変化を後から遡るのはもっと大変です。
追いかけきれずに浅い理解にとどまってしまっては、事業や社会にインパクトを起こせるような活用方法を見つけるのも難しくなるでしょう。そのため、継続的に深くインプットすることを何より大切にしています。
——現在の情報収集のルーティンを教えてください。
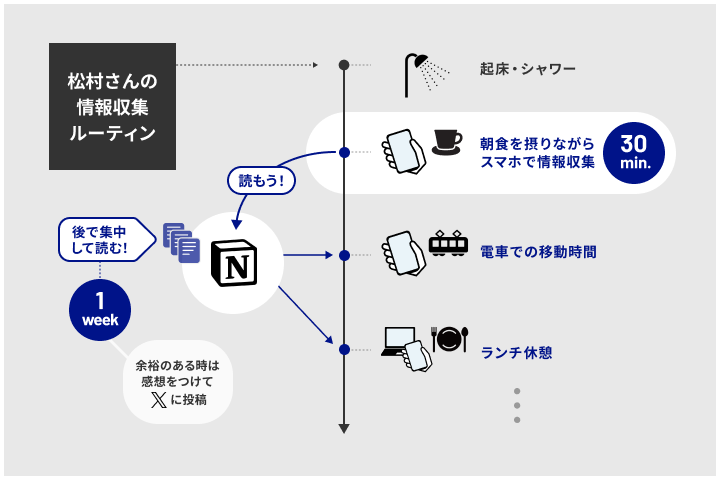
松村:毎朝30分くらい、情報を広く浅く集める時間をとっています。
朝起きてシャワーを浴びてから、朝食を摂りながらスマホを眺めるのが日課です。この時間では深くインプットすることはせず、1コンテンツ1分くらいでなんとなく眺め、それ以上読むかどうかを判断します。読もうと思ったものはNotionのデータベースにどんどん突っ込んでいきます。
その後、電車での移動時間やランチ休憩時、休日などのまとまった時間にデータベースのリストを消化していきます。「絶対に深く集中して読むべき」と判断したものにはタグをつけていて、約1週間以内を目安に読む時間をとります。それ以外は「読めたら読む」くらいで気軽にインプットしています。
また、得た情報を言語化して自分のものにするために、余裕のある時は感想をつけてXに投稿しています。
——毎朝広く浅く情報を集めるときは、どんなチャネルに、どんな目的で目を通しているんですか?
松村:技術や事業に関する情報を集めるときは、Xの自作リストや、はてなブックマークの「テクノロジー」タブ、他社のテックブログが一覧で見れるサイト「企業技術ブログ」、それと社内Slackの勉強チャンネルに目を通しています。GitHubでフォローしている人がスターをつけたリポジトリを見たりもしています。
Xでは、最新情報をタイムリーに得られるよう、領域ごとに参考になると感じた方をリストに追加して追いかけています。特定の領域においてたくさん論文を出していたり、よく登壇したりブログを執筆していたり、OSSを開発したりと精力的に活動している方を追加することが多いです。
社内Slackの勉強チャンネルは、情報の偏りを防ぐ目的でチェックしています。自分が積極的に情報を集めていなかったり、さほど詳しくなかったりする領域について詳しい人がシェアしたものに触れられるので、質の高い情報が得られます。その領域に詳しい社員のコメントも学びにつながっています。
GitHubで新しくできた面白いリポジトリなどは、Xやはてブから流れてきにくいため、趣味として目を通しています。
あとは、技術以外の情報、例えば毎日のニュースや経済情報などを集めるために、NewsPicksもよく利用しています。エンジニアは高い専門性を維持するための情報収集で手一杯になりがちで、そのほかの情報に疎い傾向があると思います。だからこそ、技術以外の領域の情報もキャッチアップしておくことで、自分と近いキャリアパスを歩んでいるエンジニアとも相対的に差がつくのではないかと考えています。
——松村さんは、レコメンド、画像認識、LLMなど、機械学習の中でも幅広い分野に関心があるようです。知見の薄い分野に初めて触れるときは、どうやってキャッチアップしていますか?
松村:その分野の全体像を把握するために、数冊の書籍をざっと読むようにしています。最初に読んだ時点で完全に理解しようとはせず、「全体像を把握する」という目的に対して詳細すぎる部分は読み飛ばしています。
学び始めの段階で書籍を読んで脳内インデックスをつくれると、その後のキャッチアップもはかどります。学生時代に情報検索・情報推薦の研究を始めようとしたきに、わからないことがありながらも、その領域を代表する『Introduction to Information Retrieval』という書籍をなんとか読み通したことが、後の研究に大変役立ちました。この成功体験から、今も、気になる分野の書籍はとりあえず購入して目次+αだけでも眺めるようにしていますね。最近の例ですと、画像認識について勉強したときに読んだ『画像認識』、Vision&Languageを学ぶために読んだ『Vision Transformer入門』などにはかなり助けられました。

松村:ちなみに、技術系は電子書籍でなく、物理的な書籍を購入することが多いです。物理で机の上に積まれているほうが「逃げられない感」が出るのと、読み終わった際に達成感を得やすいんですよね。
「この情報は不要だ」と感じたら、どんなに集中して読んでいても即やめる
——機械学習の領域は、今最もホットだからこそ、様々な質の情報があふれかえっているように思います。そんな中、今の自分に必要な情報を選び取るために、どんな工夫をしていますか?
松村:膨大な情報の中から効率よく必要な情報を得るために、不要なコストを払わないよう常に意識しています。
最初に情報に触れるタイミングでは、Xのリストとミュートを駆使し、入ってくる情報を制限することで、「読まない」と判断する意思決定のコストや時間的なコストをカットしています。
また、読んでいる途中でも「この情報は不要だ」と思ったら、即刻読むのをやめています。「ここまで読んだのに」というサンクコストを惜しんで時間を無駄にするくらいなら、真に必要で役に立つ情報を得るために時間を使うべきだと考えています。
——インプットの効率向上のために、工夫していることを教えてください。
松村:論文や英語の記事を読む際にはClaude 2をよく使っています。要約生成やポイント抽出の機能に加え、読みながら疑問に思った部分があれば対話的に解決することもできます。とはいえ、その答えもあくまでLLMの出力なので、鵜呑みにはせず、最終的には自分で裏を取るようにしています。
また、当社CTOの松本もよく話している「登壇駆動学習」は、効率よく深い理解につなげられますね。インプットしたい領域についてとりあえず登壇してみる、ブログを書くと決めてしまえば、短期間で必要な情報をきちんとインプットし、言語化して自分のものにするよう強いられますから。
——情報過多から身を守りつつ効率よくインプットすることも重要な一方で、学ぶ内容が偏ってしまうこともあると思います。そうした状態を防ぐために、どんなことをしていますか?
松村:自分だけで調べ切ろうとせず、第三者に聞いてみると、自分が考え切れていなかったり知らなかったりした貴重な情報を得られると思います。
情報を過不足なく集める上で最も難しいのは、自分が何を知らないのか、何を見落としているのかを知ることだと思っています。そうした知識の穴を自分ひとりで自覚しようとしても無理があるでしょう。第三者とコミュニケーションをとりながら情報をインプットすると、知らなかったこと、見落としていたことに気づきやすくなります。
そうした機会を得るために、社内勉強会や専門分野の論文読会に積極的に参加するようにしています。とくに関心が強い領域なら自ら勉強会を主催することもあります。直近はRecSysというレコメンドシステム領域のトップカンファレンスの論文読会を主催しました。
また、コミュニティ活動などで知り合った、その領域に詳しい方に直接聞いてしまうこともありますね。検索してもわからないことは、社内やXでストレートに聞いてみると、意外と答えてくれる人がいて助かっています。
Claude 2やChatGPTなどに「他に考えられる観点はありませんか?」などと聞いてみることも多いです。すぐに聞けるし、しつこく何度も聞き直しても嫌がりませんから。
——機械学習領域、AI領域は、研究もサービス開発も盛り上がっているからこそ、論文すら信頼できるソースと言えない場合もあるのではないかと思います。そんな中で、情報の信頼性はどのように担保していますか?
松村:たしかに、arXivにある論文はまさに玉石混合ですね。基本的なことですが、精読する前に著者の過去の実績や所属を確認するのはもちろん、信用している人がXでどう言及しているかも目を通してもいます。
それに、論文の情報が正しかったとしても、自身の環境・データでは同じようにいかないこともざらにあります。すべて真に受けず、抽象化したアイデアとして一歩引いて読むようにしています。そのため、ざっとインプットする際には、ある意味話半分くらいで読んでおき、のちに精読が必要になったときは、一次情報を参照しながら、実際に動かして検証しています。
直近で検証までした事例は、当社が扱う課題領域の機械学習モデル「LayoutLMv3」について。論文を精読した上で、実際に実装し、社内のデータを用いて学習をした上での検証を行いました。
結局一番大切なのは「無理せず、継続すること」
——情報収集において大切にしているモットーやこだわりを教えてください。
松村:
・短時間で必要な情報を得られるよう、不要なコストは徹底的にカットする
・普段の軽いインプットはルーティン化し、技術の進歩に対して穴を開けないようにする
・「知らないことを知る」ために、第三者とコミュニケーションをとる
・深くインプットする際は一次情報となる論文を精読し、できれば検証までやる
…と色々挙げられますが、やはり一番大切にしているのは「無理をしないで継続する」ことですね。
社会人1年目の時は「少しでも早く、あらゆる知識を身につけたい」と、毎日のインプットとXでのアウトプットを義務として自分に課していました。その結果、業務やプライベートが忙しくてできなかったときに自己嫌悪に陥ったり、興味を持てるものがなくても無理やりインプットとアウトプットをしたり…。技術研鑽は本来楽しいことのはずなのに、 気づけば重荷になってしまっていました。
その経験から、インプットを楽しみながら継続するためには、自分を縛るような無理をしないことが大切だと身をもって学びました。機械学習領域は特に変化のスピードが目まぐるしく、日々のインプットも楽ではありません。だからこそ、「知らなかったことを知るのが楽しい」という根源的な喜びとともに、この情報の波を乗りこなしていこうと思っています。
取材・構成:光松瞳
編集:王雨舟
関連記事
「Real World HTTP」著者・渋川よしき氏が「最新情報は追わない」と断言する理由

エンジニア不足は「業界全体」の問題。LayerX松本CTOに聞く「自走できるエンジニア不足」から脱する方法

【「スゴ本」中の人が薦める】失敗を予習するために読む4冊
人気記事

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?

Rubyへの型導入、実際にどんな利点がある? 壊さず進める大規模コード改善の実践知


