![]()
最新記事公開時にプッシュ通知します
![]()
Unicode全文字入力アプリ・Unicode Padを作って10年。少年期に抱いた文字コード愛の正体【フォーカス】
2025年8月26日
![]()
Unicode Pad開発者
株式会社estie データマネジメント事業本部 スタッフエンジニア
Lin(山本 亮介)
2018年にSoundHound Inc.日本支社にてキャリアをスタート。日本語の車載音声アシスタントのバックエンド開発に従事。2023年4月、株式会社estieに入社。データパイプラインや共通データAPIの設計・実装などを担当し、現在はスタッフエンジニアを務める。個人では大学時代の2014年にAndroidアプリ「Unicode Pad」を個人開発し、リリース。通称のLinは、配偶者の名前が由来。ニックネームを設定したのは、「ヤマモト」も「リョウスケ」もそれぞれ社内に同音の社員が在籍しており、シンプルで「unique」な呼び名が欲しくなったから。
GitHub
執筆ブログ一覧
estie公式サイト
「Unicode Pad」というAndroidアプリがあります。その名の通り、Unicode(※1)に登録されている15万以上もの膨大な文字のすべてを、シンプルなUIで閲覧・入力することに特化したツールです。2014年にリリースされると「特殊文字を入力したい」とのニッチな目的を持つユーザーから多くの支持を集め、累計ダウンロード数は今日までに1000万件を超えています。
開発者は現在、不動産テック事業を手がけるestie社のデータ領域にて、スタッフエンジニアを務める「Lin」さんこと山本亮介さんです。現在もメンテナンスが続くUnicode Padですが、Linさんはなぜ10年以上も開発を続けているのか。
気になってその発信を調べてみると、「今までに最も真面目に読んだ本」は、小学生の頃に触れた『文字コード「超」研究』(深沢千尋著、ラトルズ)という書籍だったと、Linさんは2023年にX上でつづっています。さらに遡ると、高校時代にはある日唐突に「今朝はUnicodeの夢を見ていた」との変わったつぶやきもしており、少年時代から文字コードやUnicodeに心を奪われていたのがわかります。
きっとこうした熱い思いが、Unicode Padの誕生につながっているに違いない。そう考えてインタビューを申し込むと、Linさんは「このアプリが生まれたきっかけは『文字コード愛』とはあまり関係がないんですよね……」と意外な言葉で語り始めます。
一体どういうことなのか? LinさんにとってUnicode Padと文字コードは、どんな存在であり続けてきたのか。話を通して見えてきたのは、技術者としての人生を“無意識のうちに”貫き続けていた、ある根源的な「欲求」でした。
(※1)Unicode:世界中のあらゆる文字に、それぞれ固有の番号(コードポイント)を割り当てることで、どんな言語でも同じように扱えるようにした国際的な標準規格。
「顔文字芸」の熱狂は国境を越えて
――まずUnicode Padはどのような経緯で生まれたのでしょうか。やはり、長年にわたる「文字コード愛」が開発のきっかけだったのでしょうか?
Lin:実は、そことはあまり関係がないんですよね……。

Lin:このアプリが生まれた直接のきっかけは、大学時代の「顔文字遊び」です。
当時、友人たちとの間で「自分専用の顔文字を用意しSNS上でやりとりする」という妙なブームが巻き起こっていました。当初はスマートフォンの変換ツールにデフォルトで入っている顔文字で事足りていたのですが、他の人と被らないよう奇抜なものを追求していくと、だんだんネタが尽きていったんです。最終的には「もはや自分で新たな顔文字を開発するしかない」という流れになりました。
変換ソフトに収録されている、変わったデザインの顔文字を観察すると、( )の輪郭の中に、キリル文字をはじめタイ文字やカンナダ文字など、日本語の入力体系ではすぐに出せない文字がよく使われていますよね。
そうした文字のうち、変換ツールには収録されていないさらに特殊な文字を探し出したい。そこで、すべての文字を網羅的に閲覧でき、一つひとつを拡大して吟味できるツールがあれば、顔文字に使える部品の探求も捗るだろうと考えました。
ただ、そうした目的に特化したアプリはほとんど存在しなかったので、自分でつくるしかないと考え「Unicodeの全ての文字を閲覧できるツール」としてUnicode Padを開発しました。この通り、何か社会課題の解決だとか技術的な探求だとか文字コード愛だとかではなく、自分と友人が顔文字用の新たな文字を探すための、内輪向けのツールとしてつくり始めました。

――その仲間内用のツールが、結果的に1000万回以上もダウンロードされることになったのは、どのような経緯だったのでしょうか?
Lin:まず自分も周りもほとんどがAndroidユーザーだったので、配布するならば個別に何かファイルを送るよりもGoogle Playストア経由が手軽だと考え、操作説明もほぼないような状態で配信を開始しました。すると、次第に面白アプリを紹介する個人ブログなどでたびたびUnicode Padが取り上げられるようになりまして。口コミ的に広がり、友人以外のユーザーからのダウンロード数が少しずつ増えるようになったんですよね。
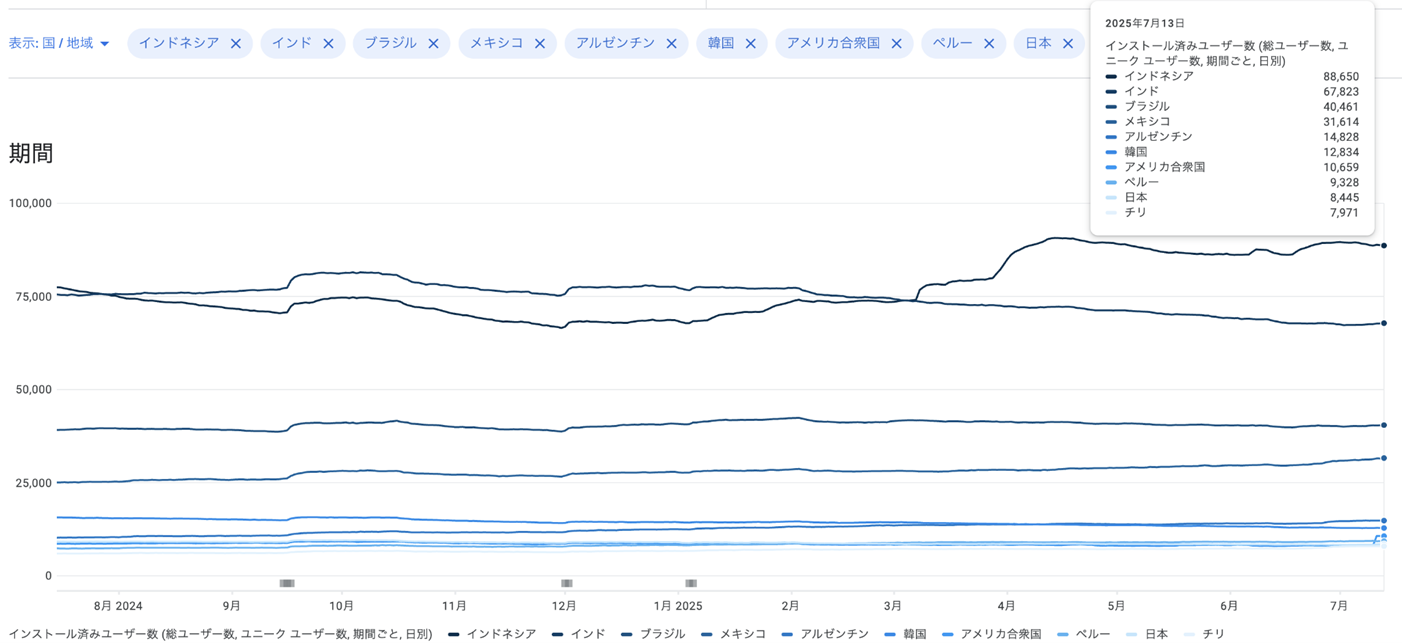
そして、2010年代の後半でしょうか。ある時期から海外、特に新興国からのアクセスが急激に増え始めました。統計を見ると南米やインドネシアが多く、一時期はブラジルがユーザー数のトップ。今はインドネシアのユーザーが最多ですね。実のところ、約1000万のダウンロードのうち大半はこうした海外ユーザーによるものです。
――海外のユーザーが、一体なぜ?
Lin:まず、こうした国々の間では2010年代半ばから後半にかけてスマートフォンが急激に普及しました。同時に、スマホ向けオンラインゲームも流行りだしたらしく、一部の人たちは「自分のプレイヤー名を、他の人が使わないような特殊文字で装飾して目立たせる」ということにハマっていったようなのです。
ところが、ポルトガル語や、ローマ字を基本とするインドネシア語などでは、日本語のように複雑な変換プロセスを必要としません。そのため、あくまで私の推測ですが、キーボードにない特殊な記号や文字を入力しようとしても、そもそも変換ツールに頼るという文化自体が薄いのかもしれません。そこで、どんな文字でもコピー&ペーストで入力できるUnicode Padが、こうした方々にとって便利なツールとして受け入れられているのではないでしょうか。

――そうした需要は、なんだかあの頃のLinさん達と似ているような……?。
Lin:はい。「目立つために、自分の言語のキーボードでは直接入力できない記号や文字を探す」という用途は、「オリジナルの顔文字をつくって目立ちたい」という動機と同じものですよね。
国や文化は違えど、やることは同じなんだな、と。まさかこんな形で使われるようになるとは、当初は想像もしませんでした。

――そんなUnicode Padの開発を10年以上も続けてきたモチベーションは、どこにあるのでしょうか。
Lin:やはり「世界中で使ってくれるユーザーがいる」というのは大きなモチベーションのひとつです。
また、「『面白さ』を補充する」目的で個人開発に取り組んできた側面もあります。
学生時代の学業や研究、そして就職後の仕事。こうした「本業」において何か行き詰ったり、「面白さ」を見失ったりしたときに、私は「趣味の開発に没頭することで知的な満足感を得る」ということをよくしてきました。これは、Unicode Padの開発に限らずですが。結果的に、このアプリの開発を続けてきた大きな要因のひとつです。
PCと図書館を往復し文字コードに魅せられる
――Unicode Pad開発のきっかけが「文字コード愛」でなかったとは。では、Linさんが子どものころに『文字コード「超」研究』を読み込んだと発信していたのは、何だったのでしょうか?
Lin:確かにUnicode Padの誕生とは直接的には無関係ですが、それはそれとして、文字コードやUnicodeはずっと好きですよ。
発端は、小学生の頃に遡ります。当時の私は図書館めぐりと電子工作が趣味でした。電子工作ではどちらかといえばハード面への関心が強かったのですが、次第にソフトウェアの世界にも興味が移っていきました。
この時期は「Windows XP」が普及しはじめたタイミングでもあり、Webサイトを見ていると文字化けや未知の文字に遭遇することが多発するようになっていました。
その原因について調べているうち「僕らが普段見る文字にはASCII(※2)とかShift_JIS(※3)だとか、いろいろな種類があるらしい」「そしてどうやらWindowsは、Unicodeなるものへの対応をどんどん強めているらしい」ということを知り、「そもそもコンピューターは、一体どうやって文字を扱っているんだろう?」と動作原理への興味が湧いてきたんです。
そんな時に、図書館で偶然見つけたのが『文字コード「超」研究』でした。それが、文字コードとUnicodeにハマったきっかけです。
(※2)ASCII:1960年代にアメリカで制定された、最も基本的な文字コードのひとつ。アルファベット、数字、記号など、英語圏で主に使われる128文字を7ビットのデータで表現する。多くの文字コードは、このASCIIを基礎として拡張される形で発展した。
(※3)Shift_JIS:Microsoftなどが策定した、日本語を表現するための文字コード体系。ASCIIをベースに、JIS漢字からひらがな、カタカナ、漢字などを追加している。かつてはWindowsの標準的な日本語コードとして広く普及し、多くのウェブサイトやアプリケーションで採用されていた。
――なぜ、文字コードの世界に惹かれたのですか?
Lin:大前提として、文字の「符号化」というテーマが好きなんだと思います。
まず「自然言語の『文字』という大規模なものをどうやってシンプルに分類・符号化するか」という挑戦そのものに心を奪われました。各言語において「そもそも『1文字』とは何か?」という定義付けから始まり、どの文字に、どんなルールで固有の番号を振っていくか。そのプロセス自体に、純粋な面白さを感じます。
そしてそのプロセスにおいて、当時の人たちが何を考え抜いたか、その痕跡を辿ったり推測したりすることにも惹かれました。
もちろん、もとは各言語や環境で独自にコード体系が作られた結果、互換性に欠けてしまい「文字化け」のような不便が多発したわけで、そうした試みは後から見ると成功ばかりではありません。むしろ、結果的には「失敗」といえるような判断も多いのですが、そうした事例について知るのも好きです。
こうして文字コードがバラバラに生まれたことによるカオスを解決しようとしたのが、Unicodeだったわけですが、あの書籍には「ライバル関係にある企業や団体が団結して世界で統一された規格を作った」というようなことが書いてあり、子ども心に胸を躍らせた記憶があります。
――文字コードの歴史が抱え込む混沌を解決しようとしたのが、Unicodeだったのですね。
Lin:だから好きなんでしょうね。中でも、その「マージ」の過程について思いを巡らすのが好きです。例えばShift_JISで使われているような日本の文字をUnicodeにマージする際など、「この文字とこの文字は由来が同じだから、同じものとして扱おう。こっちは違うから、分けよう」という具合に、先人たちの試行錯誤の跡が見える。
Unicodeが特にすごいと思うのは、複雑化や肥大化の一途を辿っていくなかで、破壊的変更はほとんどないという点です。一度割り当てたコードポイントは、基本的に不変。新しい文字や機能、例えば絵文字を追加する際も、既存の実装を壊さないよう「結合文字」(※4)などをうまく応用して拡張している。
もちろん、その過程でハングルの仕様変更(※5)のような例外も出てきたり、「それはどうなの?」と首を傾げたくなる複雑な仕様が生まれたりもしたわけですが、やはりそういう面を学ぶのも面白いですね。
(※4)結合文字:それ自体は幅を持たず、直前の文字に結合して発音や意味を変化させたり、新たなひとつの文字を合成したりするための特殊な文字。例えば、ラテン文字の「A」に結合文字であるリング記号「̊」を組み合わせると「Å」になる。日本語の濁点「゛」や半濁点「゜」もこの一種。近年の絵文字では、肌の色を変えたり、複数の人物を組み合わせたりする際にもこの仕組みが応用されている。
(※5)ハングルの大移動:Unicode 2.0で、それまで定義されていた現代ハングルの文字ブロックが別の位置へ移動・再定義されたできごと。
――Unicodeが抱える、そうした一筋縄ではいかない「歴史の産物」において、特にLinさんにとって興味深い、あるいは印象的と感じるものがあれば、教えてください。
Lin:いろいろありますが、一例を挙げるとするなら、まずは「UTF-16(※6)の複雑さ」ですね。
Unicodeが生まれた当初、関係者の間には「世界中の文字は、符号を割り当てる領域(符号空間)が6万5,536字(16ビット)あれば十分に収まるだろう」という見込みがあったようです。それで、単純な固定長の文字コードによって明快に全ての文字を登録しようとしたのですが、後から「世界に存在する文字の数は想像以上に多く、16ビットでは全く足りない」と判明した。この最初の見込み違いのせいで、UTF-16符号化においては「サロゲートペア」(※7)という複雑な仕組みで不足する文字分の符号空間を補い表現することになりました。
そしてこの仕様は広く普及してしまい、現在もWindowsの内部でUTF-16が用いられているように、根強く残っています。結果、「1文字が1つの固定長ではない」という状況に至り、「文字数を数える」という単純な処理ですら容易ではない。高校時代にC++でCGIなんかを開発していた時も、私はこの仕様にずいぶん苦しめられました。
次に「中華フォント現象」「中華フォント問題」などと呼ばれる、漢字統合をめぐる問題も印象的です。例えば日本語の「遍」という字と、中国語の簡体字の「遍」、香港・台湾で使われる繁体字の「遍」は、それぞれ微妙に字形が異なります。しかしUnicodeでは、これらが「同じ由来を持つ文字」として、同じコードポイント(符号位置)にて統合されてしまった。効率化のためとはいえ、見た目の違いを無視したのです。

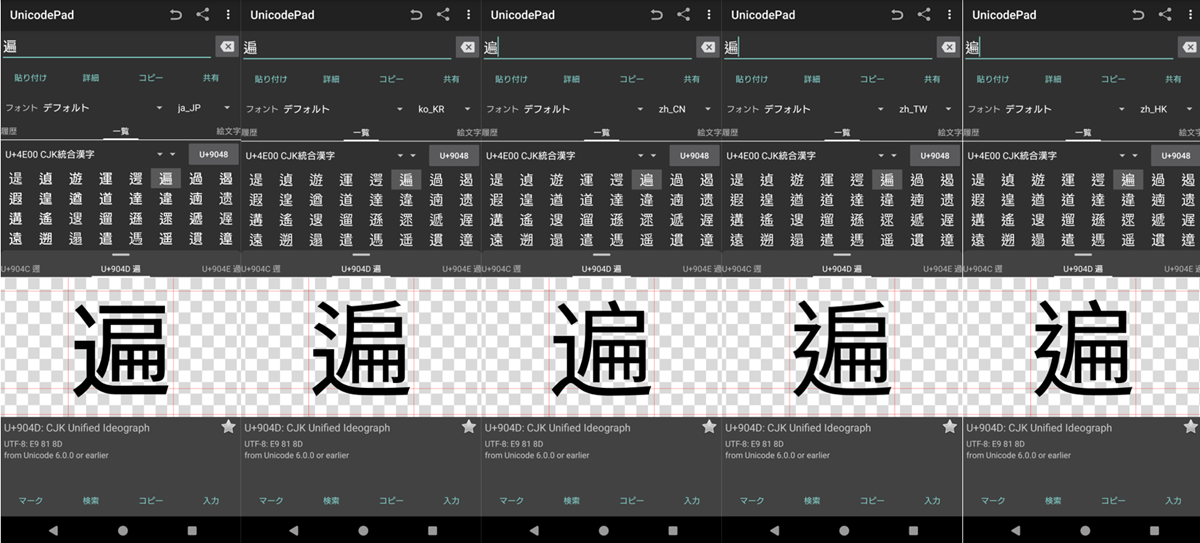
Lin:その結果何が起きたかというと、文字の形を決める役割が、下流のフォント側に丸投げされることになったわけですね。フォントは、ユーザーのPCやスマホのロケール(地域設定)を読み取り「日本で表示するならこの形」「中国大陸ならこの形」と、ひとつのコードポイントに対して複数の字形を描き分ける必要がある。
それにより、多言語対応アプリの開発者からすると、日本語を表示したいシチュエーションでも意図せず漢字が中国語の字形になってしまう、という問題が頻発しています。しかも、非漢字文化圏の人が開発する場合、先ほどの「遍」のような微妙な形の違いを見分けるのは困難ですしね。
こうした仕様の妙による「沼」のような部分を知るのも個人的に興味深いと感じますが、実際に多言語対応を迫られる開発者や、意図しない表示に困惑するユーザーからすると悩みの種だとは思います。
(※6)UTF-16:Unicodeの符号化方式のひとつ。16ビット(2バイト)を基本単位とし、Windowsの内部処理で古くから利用されてきた。なお現在Webで主流の方式は「UTF-8」。こちらは文字の種類に応じて1〜4バイトの可変長でデータを表現し、特にアルファベットを効率的に扱えるため、多くのシステムで標準となっている。
(※7)サロゲートペア:Unicodeの符号化方式のひとつであるUTF-16において、当初の16ビット(65,536文字)の範囲に収まりきらない文字を表現するために導入された仕組み。予約された特殊な2つの16ビットコードを「ペア」で用いることで、1つの文字を表現する。これにより表現できる文字数が大幅に拡張され、現在では多くの絵文字や、JIS第3・第4水準の漢字などがこの仕組みによって表現されている。
――そうした、今起きている問題と、歴史の関係を追ったり、推測したりするのがお好きなのですね。
Lin:はい。そもそもUnicode Padのメンテナンスを続けている理由の中には「Unicodeの新たな変化を追うのが面白いから」というのもあるんですよ。
Unicodeのバージョンが更新されるたび、私はすぐに新しい文字を眺めたり入力したりして、その歴史にどんなものがどう加わったのか確かめたくなります。
でも、世の中の入力ツールや変換ソフトがその更新に対応するには一定の時間がかかるため、ただ待つよりも自分でUnicode Padに実装してしまった方が速かったりもするんですよね。
なのでUnicode Padの誕生と文字コード愛自体はあまり関係がなかったのですが、Unicode Padのメンテナンスを続ける上での「面白さ」の多くは、結果的には、Unicodeへの興味からきています。
いつの間にか“それ”は本業になっていた
――それでは、Unicode Padにおける今後の目標について教えてください。
Lin:世界中に使ってくださる方々がいますし、自分自身もヘビーユーザーなので、Unicodeのアップデートに追随し続けるため、できるだけ今後もメンテナンスを続けるつもりです。
ただ最近、ちょっと困ったこともありまして。
――困ったこと、ですか?
Lin:本業が、楽しすぎることです。
先ほどの通り、私が個人開発を続けてきたのは、本業で「面白さ」を見失ったときに、代わりに知的好奇心を満たすため、というのが大きなモチベーションでした。
でもここ数年は本業が楽しすぎて、関係が逆転しつつある。そのせいで、アプリの方がなおざりになりつつある、という面があるのです。とても幸運なことではあるのでしょうけれど。
――それほど面白いと感じているとは。今さらですが、現在の仕事内容について改めて教えていただけますか?
Lin:主には、データパイプラインの開発・整備ですね。特に、estieが扱う「商業用不動産」という巨大で複雑なデータを、どうモデル化するかに夢中になっています。
例えば、estieではオフィスビルから物流施設まで、多様な不動産情報を扱っています。これらは物理的な特徴も、ビジネス上の意味合いも全く異なります。このバラバラな情報を、どうすればひとつのデータモデルで綺麗に表現できるか。その構造を考え、実装するのが、今はとにかく面白いんです。
――それほどまでに、現在の仕事はLinさんを惹きつけているのですね。それは、文字コードや個人開発の面白さとは、全く別の種類のものなのでしょうか?
Lin:いや……。その、お話しているうちに思ったのですが、根っこにあるものは、同じなのかもしれません。

――詳しく教えてください。
Lin:例えば、estieが扱う商業用不動産の領域は、当初のオフィスビル探しから物流施設、住宅などへと拡大してきました。その過程で、データパイプラインの改修などをしていると、初期のデータモデルでは表現しきれないケースに直面することがあります。
その不完全に見えるデータモデルにおいて、私は「なぜこんな型になったのだろう?」と経緯をたびたび調べています。すると「当時はオフィスビルが主な対象だったから、この設計で十分だったんだ」「当時の技術的制約と実用性を天秤にかけた結果、これが最善だったんだろうな」と過去の奮闘の跡が見えてきて興味深くあり学びにもなる。
これって、よく考えると文字コードやUnicodeの歴史に「なんでこうなったんだろう?」と思いを馳せたり調べたりする時と全く同じ楽しさなんですよね。思えば、純粋な好奇心だけでなく「いちプログラマとしても開発の参考になるな」と思いながら、文字コードの失敗の経緯について調べてきた側面もあったのです。
また実装作業においては、多様な不動産情報を、どうすればシンプルで矛盾なく表現できるか試行錯誤します。例えば、建物ひとつとっても、その単位は様々です。登記上は複数の建物でも実際には一体で使われていたり、複数の棟に見えても基部では連結していたり、用途やフロアごとに異なる名前がついていたり。こうした複雑な情報を整理していくプロセスも、自分は大好きです。
しかしこれもOSやフォントの制約のなかで、膨大な文字をUnicode Padという単一のアプリでシンプルに、かつ検索しやすく表現しようとしてきたことと、同じ種類の面白さなんじゃないか? と、お話をしていて気がつきました。
――確かに、お話を聞いていると、Linさんを突き動かす根源的な動機は、どこか共通しているものがあるようにも感じます。文字コードやUnicode Pad、お仕事もそうですが、例えば、社内で苗字にも下の名前にも同音の方がいるからと、完全な「ユニーク」になるよう「Lin」という通称を使われたり。かつて東京メトロのデータに趣味で触れているときに『1本の列車が2つに表現されている』不整合性を指摘されたり。
Lin:今まであまり言語化したことはなかったのですが、それはやっぱり「現実世界にある複雑な物事を、シンプルに『符号化』したい」というひとつの欲求なんだと思います。
現実世界の複雑なものを、矛盾なく、一意の識別子や構造で表現したい。そんな感覚が、ずっと根底にあるんでしょうね。複数のものが同じ名前で呼ばれる「衝突」や、ひとつのものが複数として扱われる「不整合」をみると、解消したくなる。
思い返すと、estieに入社した時にはマイパーパス(自分が働く目的や存在意義)というのを書いたのですが、その時の内容も「システムをシンプルに理解したいな」「例外だらけの地物データや、複雑な交通システムも、背景を辿るとシンプルに理解・記述できるかも」というものでした。
――まず「複雑なものをシンプルにしたい」という欲求が根源にあり、その上で「先人たちの試行錯誤の跡から、『符号化』の過程について、成功も失敗も含めて学ぶのが好き」と。現在はこれらの作業そのものが仕事内容になったため、本業が楽しい、ということなのでしょうか。
Lin:そうなのかもしれません。
ただ、本業に注力するあまり、Unicode Padが放置気味になっているというのには後ろ髪を引かれる思いです。ソースコードはGitHub上にも公開しているのですが、近ごろはIssueも溜まっていく一方で、申し訳ない気持ちもあります。私がUnicodeのいちファンであることは変わらないので、どうにかこれからも、Unicodeのバージョンが更新されるタイミングなどで、機を見てアプリのメンテナンスを続けていけたらと思っています。
そしてこのアプリが、私のように、巨大な文字コードの世界に惹かれた人たちの知的好奇心や、ちょっとした遊び心を刺激することができたら、とてもうれしく思います。

取材・執筆・編集:田村 今人
撮影:赤松 洋太
関連記事
勢いでつくったSQLツールと歩んだ28年。フリーソフト「A5:SQL Mk-2」開発秘話【フォーカス】

CSS嫌いがあえてフレームワークまでつくった理由。 NES.css開発者流、「嫌い」を「好き」に変える勉強術【フォーカス】

量産型UIから脱却したくて。個人開発の賃貸検索「Comfy」が提言する“探しやすさ”の形【フォーカス】
人気記事

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋

人間のコードレビュー力を鍛えるために。AIコーディング時代の「ペアプロ・モブプロの心得」

