![]()
最新記事公開時にプッシュ通知します
![]()
マルチテナント環境におけるIstio/Datadogを活用したオブザーバビリティの実践 【CADC2024イベントレポート】
2025年1月20日


株式会社CAM サイトリライビリティエンジニア
岡 麦
2022年に新卒入社。サイバーエージェントの子会社・株式会社CAMのSREチームに所属し、おもに社内向けプラットフォームの運用や保守に携わる。
X:@mugiokax
近年、システムの安定稼働に貢献するオブザーバビリティという概念に関心が高まっている。
昨年10月29、30日にわたって開催された「CyberAgent Developer Conference 2024」では、同社のSREチームの岡麦氏が、社内開発者向けプラットフォームにおけるIstioとDatadogを活用した統合的なオブザーバビリティの手法について紹介した。
株式会社CAMは2000年の設立以降、エンタメ、ビジネス、ライフスタイルの分野を中心にメディア開発やコンテンツ制作などを手がけてきた。社内開発者向けプラットフォーム「Fensi Platform」上には20以上のサービスが稼働しており、データソースやコンピューティングリソースを共有するマルチテナントの方式を採用している。これによりシステム運用の簡素化やコスト削減を実現している。
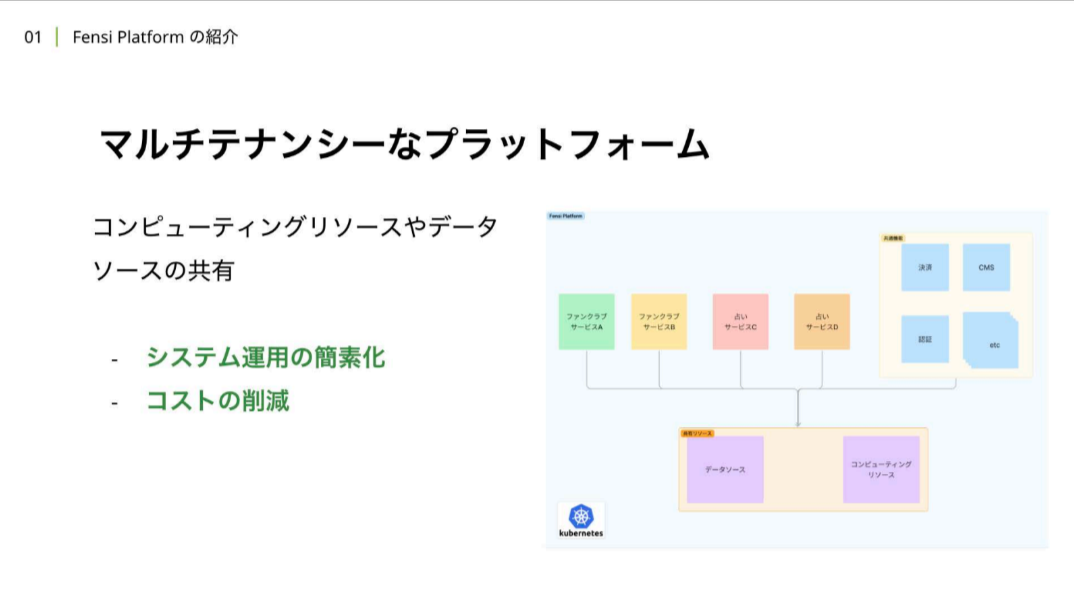
マルチテナンシーなプラットフォーム上で複数のテナントが活動するため、Fensi PlatformはIstioを活用したサービスメッシュな構成を取っている。「サイドカー」と呼ばれるレイヤー上で、認証、通信の高度な制御、通信の可視化を効率的に実行している。さらに、Datadogを活用して、リソース使用率やリクエスト数などのメトリクスの保存、サービスメッシュ内のトレーシングスパンの取得・保存・分散トレーシングを行うなど、統合的なオブザーバビリティを実現している。本セッションでは、こうしたオブザーバビリティのうち、メトリクスとトレースに着目したIstio/Datadogの実践的な活用事例を解説した。
内部開発者向けプラットフォームが抱えていたノイジーネイバー問題
岡:本題の前に、まずはFensi Platformが 抱えていた課題について少しお話しします。 先ほども紹介したように、Fensi Platformでは1つのプラットフォーム上で複数のドメインの異なるサービスが同時に稼働しています。その際、個別のサービスで突発的なアクセスが発生して過負荷に陥ってしまった場合、プラットフォーム全体に影響が伝播し「ノイジーネイバー(うるさい隣人)問題」が起きてしまうケースがありました。
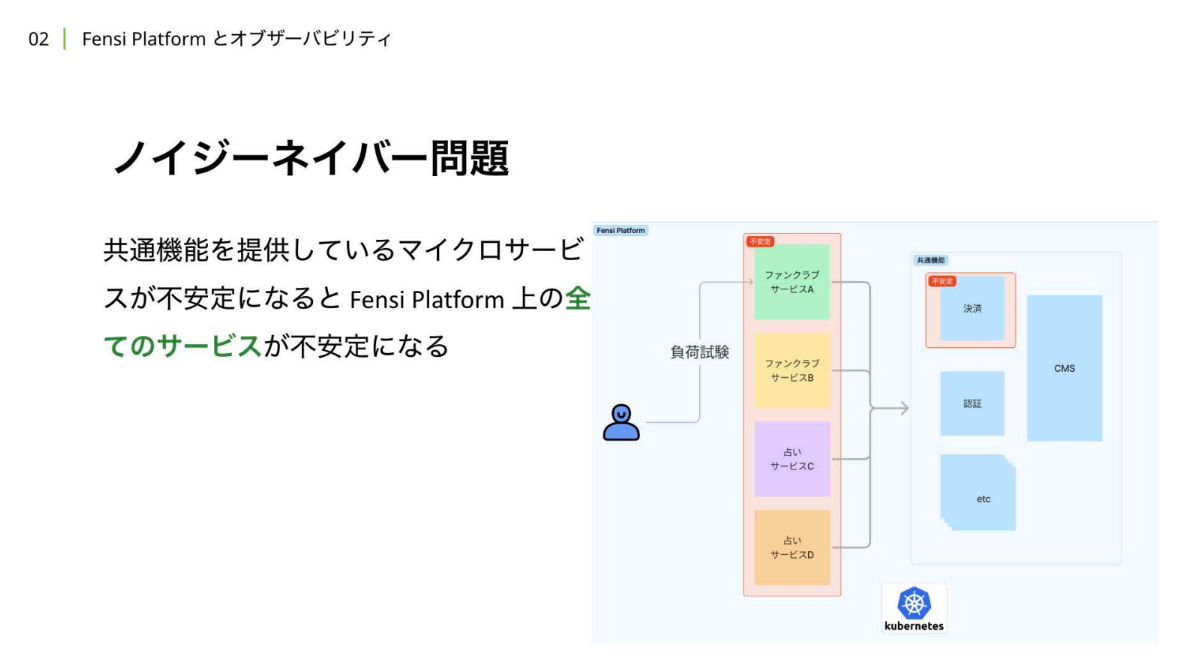
岡:実際に負荷実験を実行した際にも、図のように、ファンクラブサービスにのみ負荷をかけていても、その後ろにある決済サーバーが不安定になった結果、負荷をかけていないサーバー、サービスも不安定になってしまうという問題が起きていました。
SREが目指したのは、Fensi Platform上で稼働している全サービスが安定してユーザーに価値を届けられる状態をつくること。そこで我々は、通信のより詳細な可視化を実現することで、たとえ障害が発生したとしても、高速で復旧できる体制をつくり、さらに、適切なキャパシティプランニングができるようにすることで、そもそも不安定になる事象を避けられるようにしています。
Fensi Platformに必要なオブザーバビリティの2要素
岡:上記の課題を踏まえて、Fensi Platformに求めるオブザーバビリティの2つの要素を紹介します。
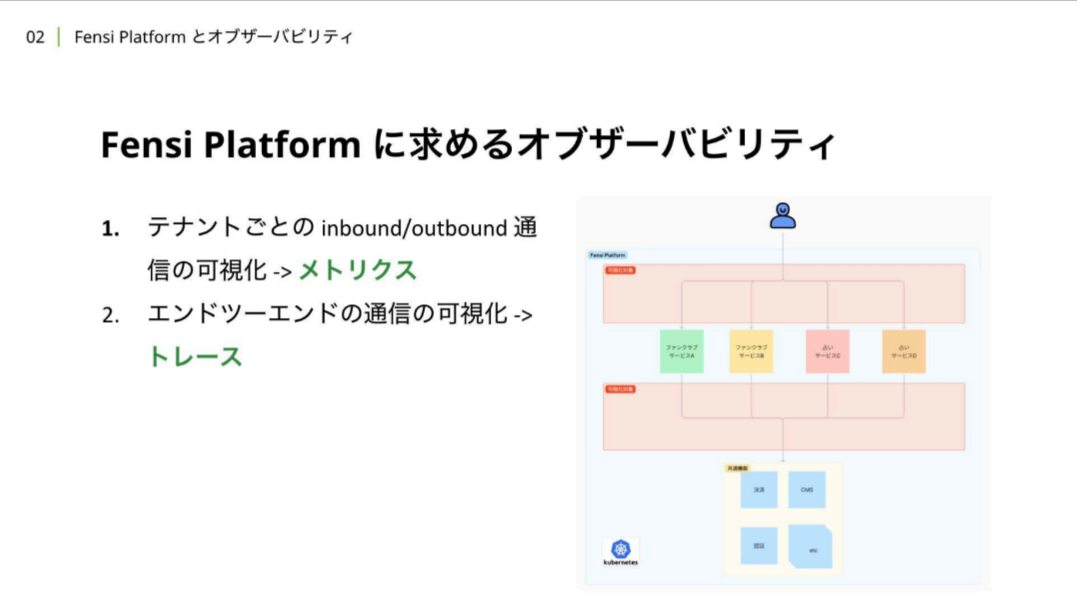
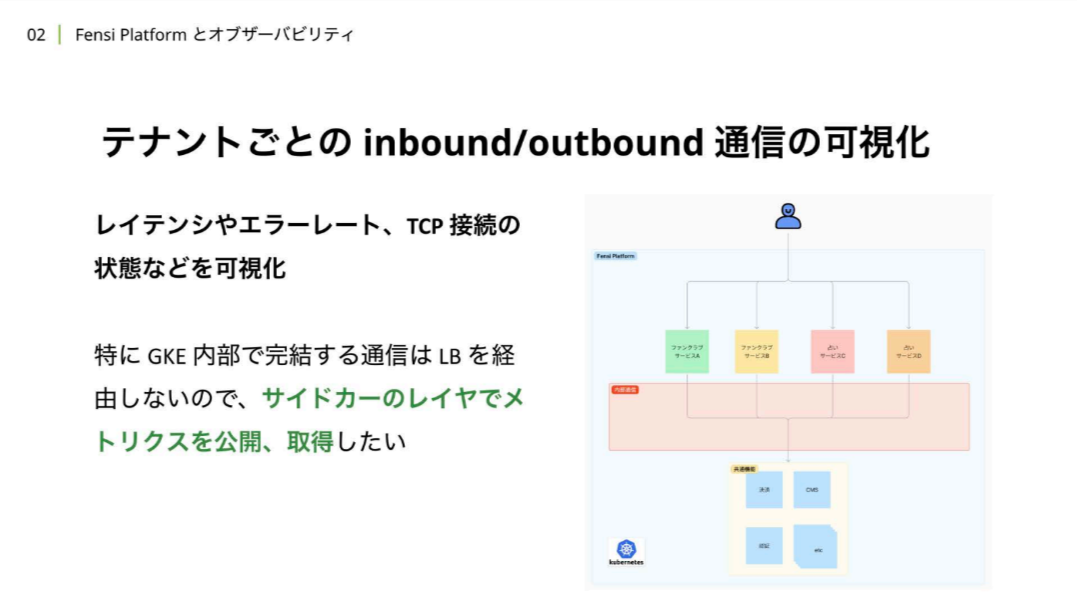
岡:まず一つ目は、テナントごとのinbound/outbound通信の可視化です。これはIstioが公開しているメトリクスを活用して実現しています。
inbound/outbound通信の可視化とは、レイテンシやエラーレート、 TCP接続の状態などを可視化しています。また、弊社ではGKE(Google Kubernetes Engine)を利用しています。GKE内部で完結する通信はロードバランサーを経由しないため、先ほど紹介したサイドカーのレイヤーでメトリクスを公開取得しています。
岡:「何でテナントごとに可視化する必要があるのか」と疑問に思った方もいるかと思います。さきほど紹介したノイジーネイバー問題を避けるために、通信を制御する「レートリミット」を設定しているユースケースが存在しています。こういったユースケースに対してレートリミットの閾値を適切に設定するために、 テナントごとの通信量を可視化することが求められています。
テナントごとのinbound/outbound通信の可視化と平行して取り組んでいるのは「エンドツーエンドの通信の可視化」です。
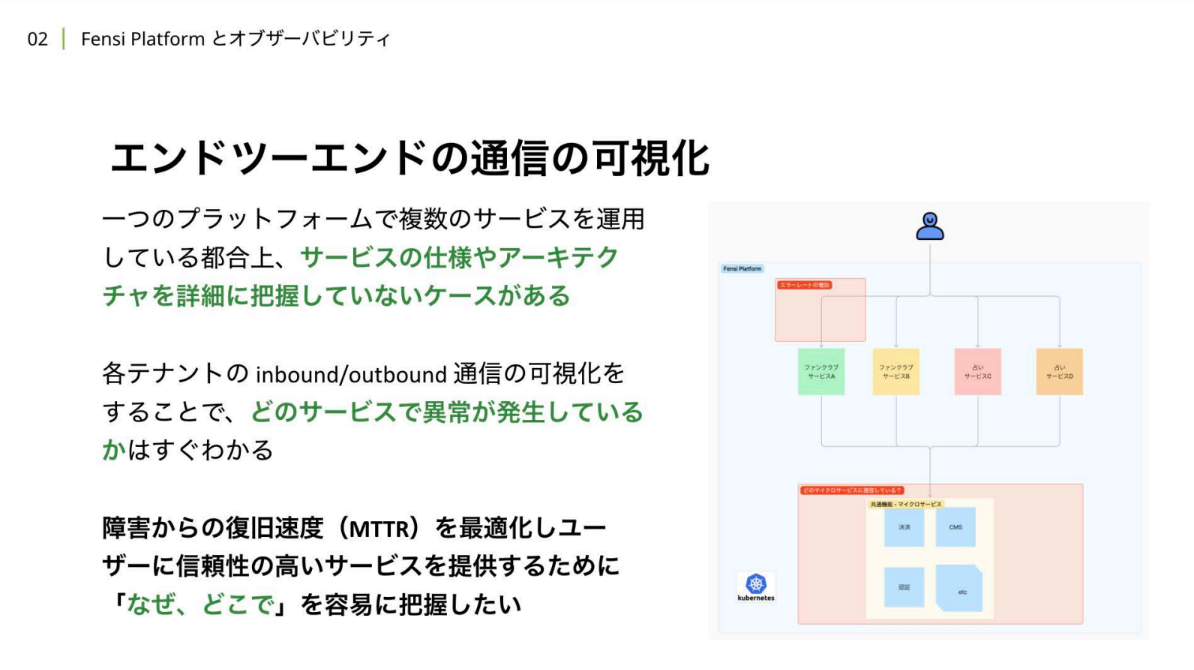
岡:1つのプラットフォーム上で複数のサービスが同時に稼働している都合上、サービスの仕様やアーキテクチャを詳細に把握していないこともあります。エンドツーエンドの通信の可視化により、共通機能まで含めてどこで何が起きているのかを容易に把握し、障害からの復旧速度(MTTR)を最適化することが求められています。
Istio/Datadogの実践的な活用
岡:ここからは、大きく4つの項目に分けてFensi Platform上のオブザバービリティに、Istio/Datadogをどのように活かしているのかお話ししていきます。
Istioメトリクスの可視化のためのセットアップ
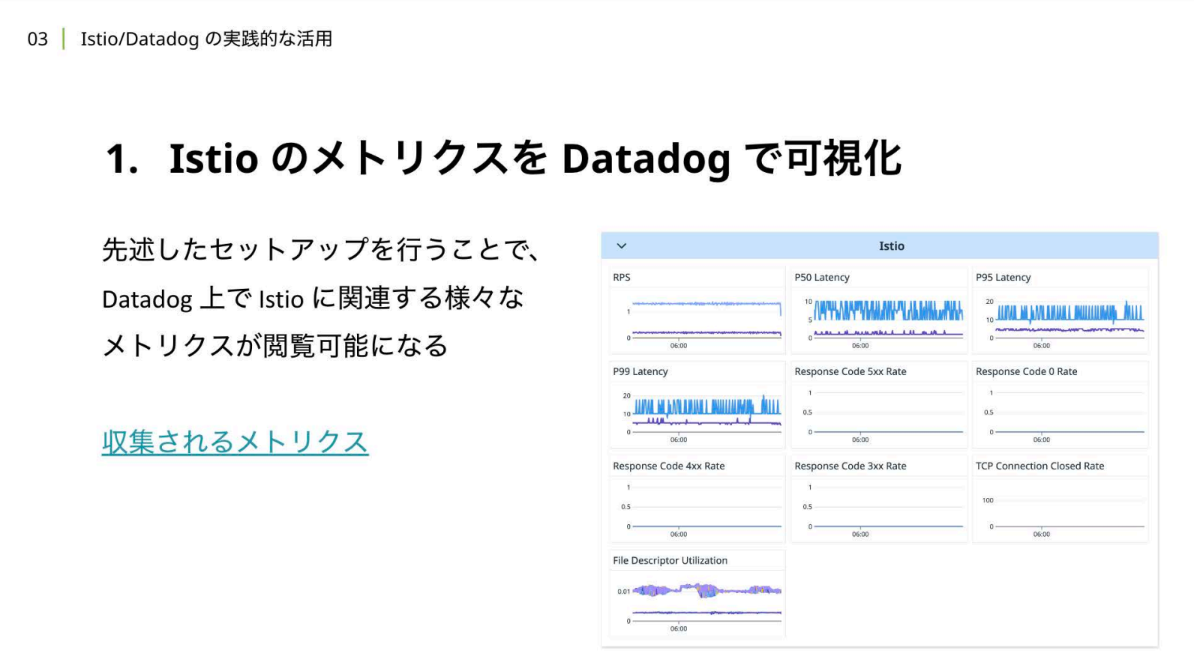
岡:まずは、IstioメトリクスをDatadogで可視化するために、一部カスタムしてセットアップしていることを紹介します。Fensi Platformでは、DatadogをHelmチャートを使ってインストールしています。レイテンシをパーセンタイル形式やヒストグラム形式で取得するために、Datadog AgentをカスタマイズしてKubernetesにインストールしています。 これにより、下図右のように、Datadog上でIstioに関連する様々なメトリクスを閲覧可能になります。

Envoy Proxyのメトリクスの可視化
岡:IstioのデータプレーンはEnvoy Proxyで構成されているため、Envoy Proxyのメトリクスの可視化は、通信状況の把握に非常に役立つし、トラブルシューティングの指標が得られます。
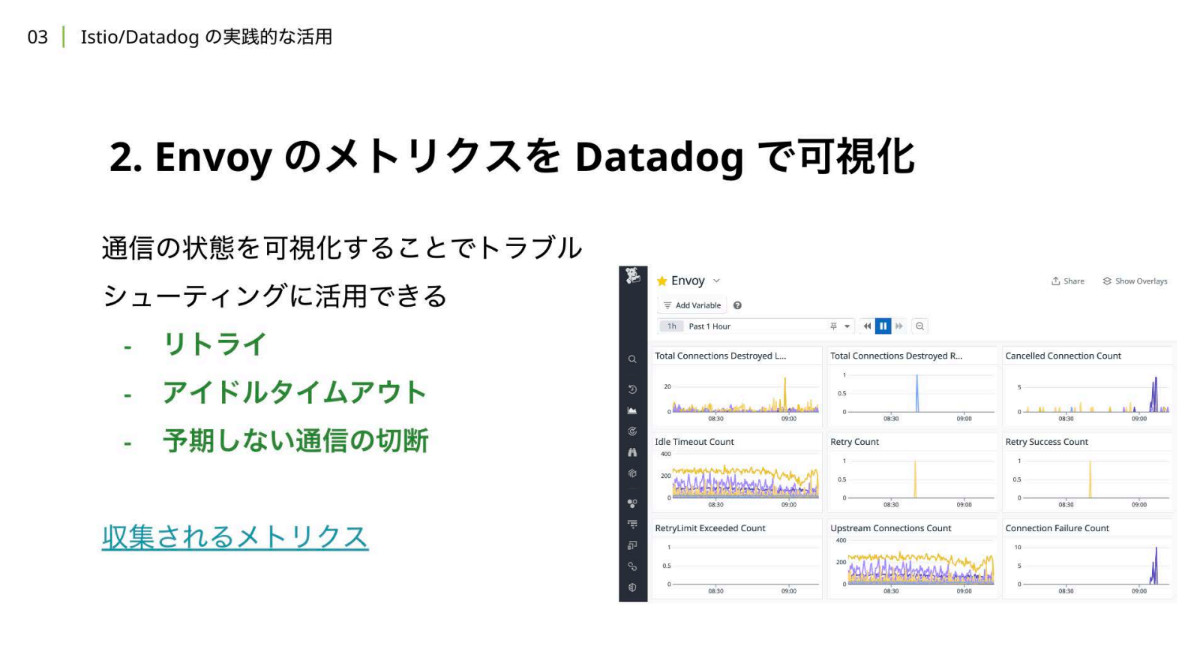
岡:例えば、Envoy Proxyには502エラーが返ってきたら自動的にリトライする機能があり、そのリトライが発生したらあるメトリクスが増加するように設定したり、予期しない通信の切断が発生した時にメトリクスを表示させたりして、Envoy Proxyのメトリックスを取得することでDatadog上で可視化できます。
アイドルタイムアウト値のずれを検知
岡:先ほど紹介したように、アプリケーションのoutbound/inbound通信はistio-proxyを経由します。ところがクライアントとサーバー間のアイドルタイムアウト値の不一致により、ときには予期せぬ通信切断が引き起こされるケースが存在します。
Node.jsサーバーの例を見ると、デフォルト設定のアイドルタイムアウトが、istio-proxyの HTTP通信におけるTCP connectionのアイドルタイムアウトが1時間であるのに対してNode.js サーバーでは 5秒と、 istio-proxyの方が大きいアイドルタイムアウト値を取っています。すると、両者の間を通信で接続しようとした時に、Node.jsサーバーからは接続を切断してしまうケースが出てきてしまいます。
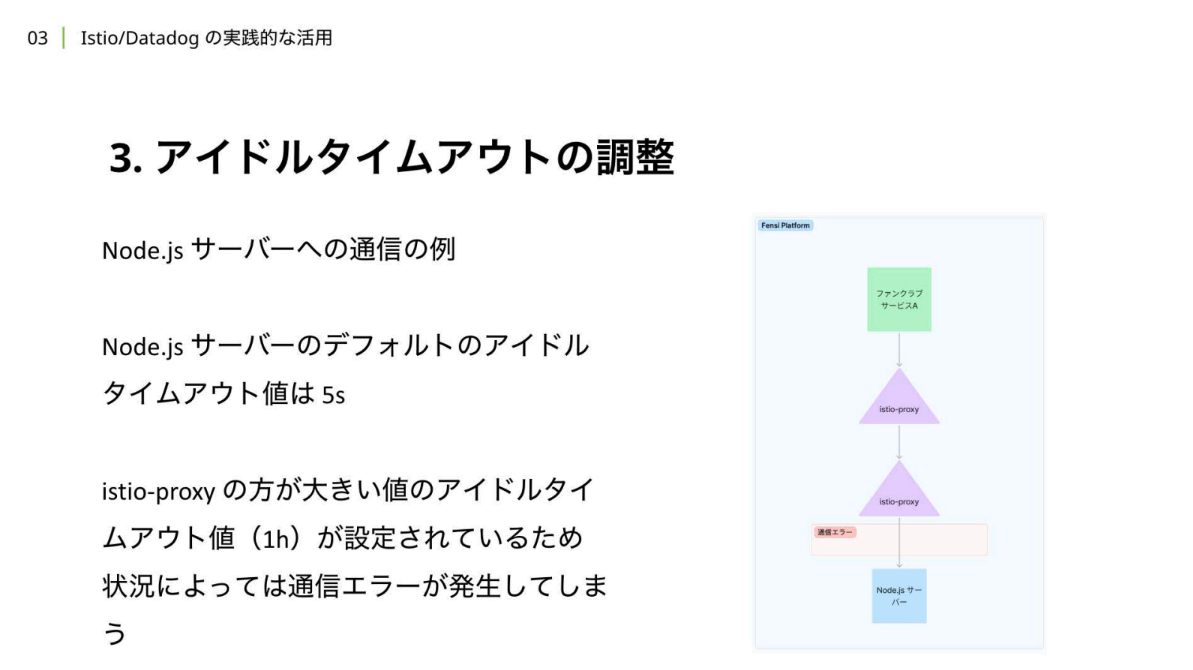
岡:このアイドルタイムアウトの値のずれを検知するのに、Envoyのメトリクスの可視化が役立ちます。 クライアントから見た時に、リモートとなるサーバーに接続できなかった、通信が切断されたということをメトリクスを可視化することで検知し、トラブルシューティングが可能になります。
岡:我々が実際に実践しているアイドルタイムアウトの調整方法としては、アプリケーション側の設定を書き換えるパターンと、istio-proxyの設定を書き換えるパターンの大きく分けて2つの方法があります。
Fensi Platformでは同一プラットフォーム上で複数のサーバーが稼働しており、アプリケーション側の設定を書き換えるコストが高くなるため、istio-proxyの設定を書き換える例を紹介します。

岡:Fensi Platformでは、Destination Custom ResourceでHTTP通信のアイドルタイムアウトの調整をしています。今回の例では、Node.jsサーバーをDestinationとして設定し、Node.jsサーバーのデフォルトのアイドルタイムアウト値である5秒より短い3秒をistio-proxyのアイドルタイムアウト値として設定しています。
この設定により、予期しない通信の切断が発生しなくなります。

岡:HTTP通信のアイドルタイムアウト調整も、EnvoyFilterカスタムリソースなどのIstioのリソースを利用することで可能になります。今回は、接続先に対してAWS ALBをLBとして使用しているため、ALBのアイドルタイムアウト値(60秒)より短いタイムアウト値をistio-proxyに設定しています。
EnvoyFilterはAlpha状態なので使用には注意が必要ですが、EnvoyFilterを活用することでACTP通信のアイドルタイムアウトも調整することができます。
istio-proxyの トレーシングスパンの取得
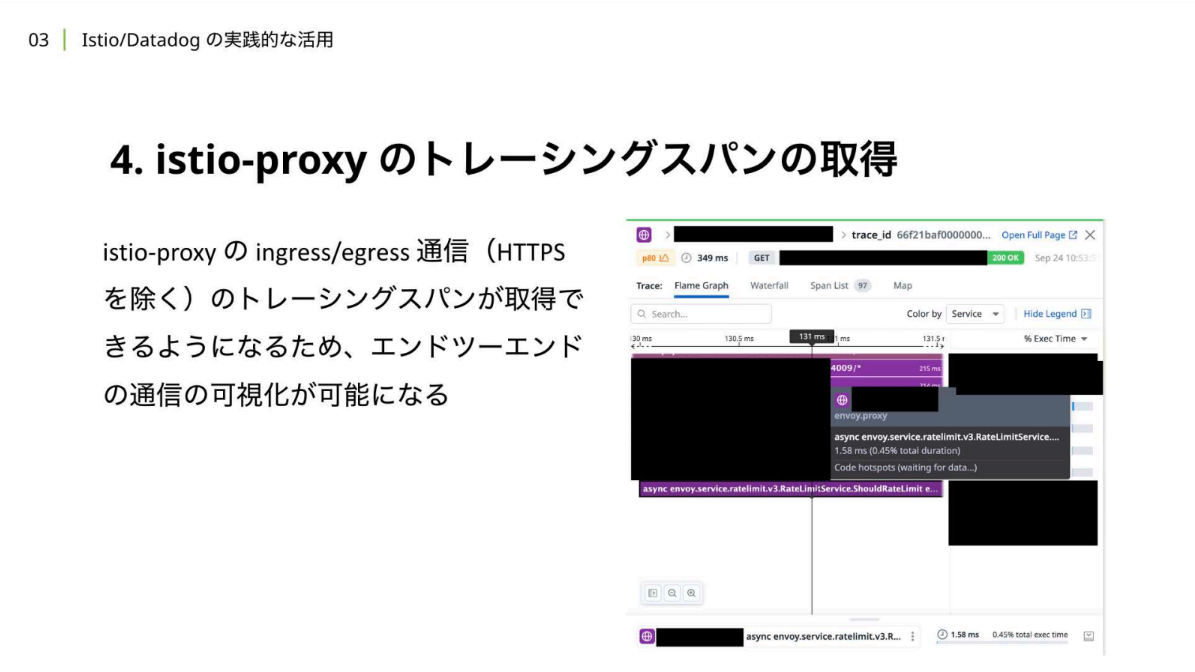
岡:Istio/Datadog活用の話に戻ります。弊社では、istio-proxyのトレーシングスパン取得も行っています。
Fensi Platformのようなサービスメッシュプラットフォームの場合、各サービスへのoutbound/inbound通信はistio-proxyを経由しています。そのため、istio-proxyのトレーシングスパンを取得することで、istio-proxyと自社開発サーバー以外での通信にかかっている時間が可視化できるようになります。

岡:公式ドキュメントに則って設定することも可能ですが、最新のIstioではTelemetryCRを使用した設定が推奨されていることに加え、Datadog Agentにトレーシングスパンを送信する際、DestinationRule CRでアイドルタイムアウト値を調整しないと、意図しない通信断が多く発生してしまうという理由から、違う設定方法を実践しています。
istio-proxyのトレーシングスパンを取得するためには、まずIstioOperatorでDatadogをプロバイダーとして設定する必要があります。そして、istio-ingressgatewayのトレーシングスパンを取得するためには、DatadogにKubernetes Serviceのドメインを設定する必要があることに注意します。
なお、通信コストの最適化を行うためにUDS(ユニックスドメインソケット)でDatadogAgentにトレーシングスパンを送りたいと思うかもしれませんが、現在Envoyではサポートされていません。
Datadogをプロバイダーとして登録した後は、TelemetryCRでトレーシング機能を有効にします。DatadogAgentのHead-based sampling(デフォルトのサンプリングアルゴリズム)はルートスパンに対してサンプリングレートが適用されるため、istio-proxyのサンプリングレートは高めに設定しておくのがおすすめです。 これにより、 istio-proxyのingress/egress 通信のトレーシングスパンが 取得できるようになるため、エンドツーエンドでの通信の可視化がより容易になります。
おわりに
岡:今回は、Datadog/Istioを活用したオブザーバビリティの実践について、Fensi Platformという社内開発者向けプラットフォームの構成を例に紹介しました。
自分たちのニーズにあったオブザーバビリティを実践することで、SREとして適切な信頼性のコントロールが可能になったり、ユーザーのニーズを満たすサービスを持続的に提供したりすることが可能になりました。
関連記事

変化するクラウドの風景。クラウド管理における優先事項はオブザーバビリティから最適化へ【テッククランチ】

障害対応を属人化させない。「全員インシデントコマンダー」体制を根付かせた、山本五十六の格言【NewsPicks SRE 安藤裕紀】

「欲しいけど難しい」IPづくり。群雄集うクリエイティブ集団「SSS by applibot」が実践する、IPを生み出すスクラップアンドビルドに密着
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理

国産組込みOS「ITRON」が40年生き残ってきた理由を、生みの親と振り返る【TRON】


