![]()
最新記事公開時にプッシュ通知します
![]()
Google「量子誤り訂正」新たな成果 高精度な論理量子ビット構築、大規模量子コンピュータに一歩前進?【研究紹介】
2024年9月11日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
Google Quantum AIなどに所属する研究者らが発表した論文「Quantum error correction below the surface code threshold」は、新たな量子エラー(誤り)訂正手法を提案した研究報告である。研究によると、量子ビットの論理エラー率を従来よりも大幅に低減することに成功した。この成果は、大規模な量子コンピューティングの実現に向けた一歩を示す可能性がある。
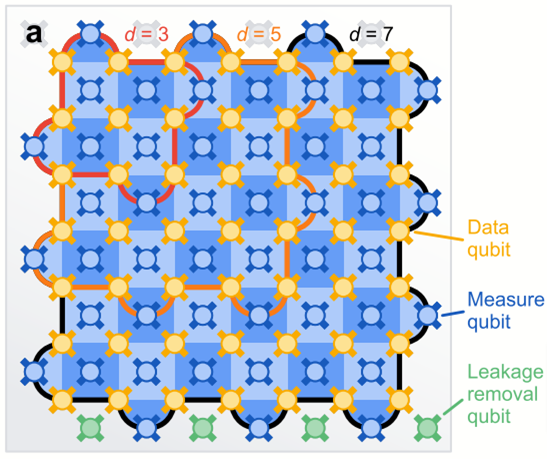
研究背景
量子コンピュータは、通常のコンピュータとは異なる原理で動作する。従来のコンピュータがデータを0か1のビットで扱うのに対し、量子コンピュータは量子ビット(キュービット)を使用する。量子ビットは0と1の重ね合わせ状態を取ることができ、特定の計算において従来のコンピュータを大きく上回る性能を発揮する。
しかし、量子コンピュータにはエラーが発生しやすいという大きな課題がある。量子ビットは非常に不安定で、わずかな外部からの干渉でも状態が変化してしまうためである。さらに、量子ビットの状態を直接確認しようとすると、その量子状態が崩壊してしまうという問題もある。
研究内容
研究者らは、この問題を解決するために、複数の物理量子ビットをまとめて、1つの論理量子ビットとして機能させる方法を採用している。論理量子ビットは、エラー検出と訂正機能を備えることで、個々の物理量子ビットよりも安定した量子情報の保持と操作を可能にするものである。このシナリオでは、量子ビットの状態を直接測定することなく、表面コード(表面符号)と呼ばれる技術を使用して、物理量子ビットの相対的な特性をさまざまな方法で観察し、エラー発生の間接的な検出が可能となる。
しかし、この方法にも課題がある。Google Quantum AIの2021年の研究は、単に物理量子ビットの数を増やすだけでは、全ての問題が解決するわけではないことが示唆されている。物理量子ビットを増やすとシステムの複雑さも増し、新たなエラーも増加し得るためだ。
目標は、エラー発生率以上に、エラーを抑制する方法を見つけることだ。この転換点は「閾値」と呼ばれている。
今回の研究チームは、72量子ビットと105量子ビットのプロセッサを用いた実験の中で、この方法の有効性を実証し、表面コードの閾値を下回るエラー率を達成した。試験では、論理量子ビットが個々の物理量子ビットの2倍以上の時間にわたって、正確に量子情報を保持できた。さらに研究チームは、1サイクルあたりのエラー率を約0.143%までに低減させることもできたと報告している。
また、高距離でのエラースケーリングの調査では、一定の距離までは、コード距離を大きくするにつれ論理エラー率が指数関数的に抑制されることも示唆されている。
これらの成果は、大規模な量子コンピュータ開発の大きな一歩となる可能性がある。しかし、量子コンピューティングの実用化に向けては、まだ乗り越えるべき大きな課題が残されている。
現在の量子プロセッサを単純に大規模化するだけだと、必要なリソースが膨大になってしまう問題があるのだ。具体的な例を挙げると、100万回の演算で1回のエラー率を達成するためには、論理量子ビット1つに1,457個の物理量子ビットが必要になる。これは、現在存在する最大級の量子コンピュータに収まり得る量よりも大きい。
Source and Image Credits: Acharya, Rajeev, et al. “Quantum error correction below the surface code threshold.” arXiv preprint arXiv:2408.13687 (2024).
関連記事
「動的量子チェシャ猫」が物理法則を揺るがす? “回転の勢い”が粒子から分離して移動できる可能性【研究紹介】

Googleの「量子超越性」覆す。NVIDIAの「A100」2300個超を使って量子コンピュータ凌駕【研究紹介】
「量子」で瞬時に証券売買調整?事前共有した“量子もつれ”取引所間で利用し、市場で優位に立つ手法提案
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


