![]()
最新記事公開時にプッシュ通知します
![]()
映像内のあらゆる動く物体を追跡し分離できるAI「SAM-PT」 点を数か所指定するだけの簡単操作【研究紹介】
2023年7月10日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
スイスのチューリッヒ工科大学などに所属する研究者らが発表した論文「Segment Anything Meets Point Tracking」は、映像中の動的なあらゆる物体を追跡し、セグメンテーションする手法を提案した研究報告である。この研究では、最近発表された米Meta社の静止画像セグメンテーションモデル「SAM」を、ゼロショット設定における動画セグメンテーションタスクに対応させる。
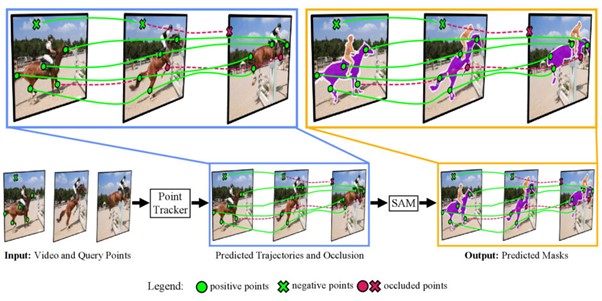

研究背景
動画セグメンテーションは、自律走行、ロボット工学、ビデオ編集など、さまざまなアプリケーションにおいて非常に役立っている。しかし、深層学習ネットワークを用いた現在の方法論は、特にゼロショット設定において未知のデータに直面すると困難を伴う。これらのモデルは、特定の動画セグメンテーションデータがない場合、多様なシナリオで一貫した性能を維持することが難しい。
この課題に対する潜在的な解決策の1つは、画像セグメンテーションで成功しているモデルを動画セグメンテーションタスクに適応させることだ。その中でも、Metaが開発した「SAM」(Segment Anything Model)は非常に有望なモデルである。SAMは、画像セグメンテーションのための強力な基盤モデルであり、1100万枚の画像と10億以上のマスクを含む大規模なSA-1Bデータセットで学習され、ゼロショット汎化能力が実現されている。
このモデルは非常に適応性が高く、単一の前景ポイントから高品質なマスクを生成することができ、ゼロショットにおいて堅牢なパフォーマンスを示す。SAMは画像セグメンテーションにおいて強力な能力を持っているが、現時点では動画セグメンテーションタスクには適用することができない。
研究内容
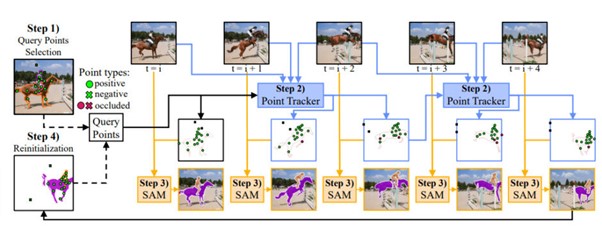
この研究では、疎な点追跡と、「SAM」の強力な画像セグメンテーションを組み合わせることで、動画中のあらゆる物体の追跡を可能にする動画セグメンテーションモデル「SAM-PT」(Segment Anything Meets Point Tracking)を提案する。
SAM-PTは、動画セグメンテーションデータのトレーニングを必要とせずに、動画に埋め込まれた豊富な局所構造情報を利用した点駆動アプローチを採用する。主に4つのステップで構成される。
まず、(1)最初のフレームでクエリポイントをユーザーが追加する。このポイント(点)は、動画内のセグメンテーションしたい対象オブジェクト(ポジティブポイント)と、非対象オブジェクト(ネガティブポイント)に付与する。これにより、セグメンテーションの対象となるオブジェクトか、非対象となるオブジェクトかが決まる。
次に、(2)ポイントトラッカーを使用して、これらのポイントをすべてのビデオフレームに伝播させる。ポイントトラッカーは、クエリポイントから始まり、ポイントをビデオフレーム間で伝播させ、ポイントの軌跡とオクルージョンのスコアを予測する。(3)SAMを使用して、伝播されたポイントに基づいて各フレームのセグメンテーションマスクを生成する。
最後に、(4)オプションとして、予測されたマスクからクエリポイントをサンプリングしてプロセスを再初期化する。再初期化は、信頼できない点やオクルードされた点を取り除き、オブジェクトが回転したときなど、後のフレームで見えるようになるオブジェクトの部分やセグメントからの点を追加することで役立つ。

実証実験
SAM-PTの性能を評価する実験を行った結果、DAVIS、YouTube-VOS、MOSE、UVOを含むいくつかのベンチマークにおいて高い性能を示した。
SAM-PTは、動画セグメンテーションデータを学習していないにも関わらず、未見のオブジェクトに対するより良い汎化を提供し、SAMの本来の柔軟性を維持しながら、その機能を動画セグメンテーションに効果的に拡張できることを実証した。
この結果から、SAM-PTは動画セグメンテーションの領域で有望な手法であり、未来の研究や応用において重要な役割を果たすことが期待される。
Source and Image Credits: Rajivc, Frano, Lei Ke, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan and Fisher Yu. “Segment Anything Meets Point Tracking.” (2023).
関連記事

「自分の絵を画像生成AIから守る」――学習される前に絵に“ノイズ”を仕込みモデルに作風を模倣させない技術「Glaze」【研究紹介】

PairsのマッチングでAIが果たす役割とは?Pairs Data Director奥村純に聞く、感情感覚領域にある「AIにしかできないこと」

イスラエルと米国の研究者らが開発 3Dモデルを簡単編集できるAIシステム「GeoCode」【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


