![]()
最新記事公開時にプッシュ通知します
![]()
脳活動から聞いている音声を文章で抜き出す非侵襲的技術 米テキサス大が開発【研究紹介】
2023年5月11日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
米テキサス大学オースティン校に所属する研究者らが発表した論文「Semantic reconstruction of continuous language from non-invasive brain recordings」は、音声を聞いている脳活動から、その内容の単語やフレーズ、文章を復元する非侵襲的技術を提案した研究報告である。無音の動画を見ている脳活動からも、シーンの内容を説明する文章を復元することに成功した。
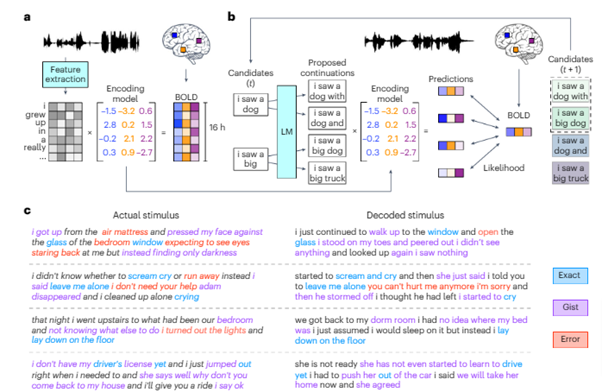
研究内容
これまでにも脳活動から音声を解読するアプローチは行われてきたが、人の脳内に侵襲性の高い電極を埋め込む必要があったり、非侵襲的システムでも決められた単語や短いフレーズの解読に限定されていたりと制限が多かった。
本研究では、機能的磁気共鳴画像法(fMRI)を用いて記録された皮質の信号データから自然言語を用いて知覚・想像した刺激を再構築する非侵襲的デコーダシステムを提案する。このシステムは、聞いた音声、無音動画の意味を理解可能な単語シーケンスで生成するタスクを可能にする。
実現するためには、fMRIの時間分解能の低さという、一つの大きな障害を克服する必要があった。研究チームはこの課題に対して、次に来る単語の候補を生成し、脳活動に最適な候補を選択するアプローチを採用する。
学習ステップでは、ボランティアの参加者3人にラジオ番組、ポッドキャスト、TEDトークなどの音声を聞いてもらい、その際の脳活動をそれぞれ16時間記録したデータセットでモデルを訓練した。モデルは単語一つ一つを的中させるように訓練されておらず、多少言葉が違っていても意味的に合っているように訓練された。
学習したシステムを大脳皮質全体でテストしたところ、元の言葉の意図した意味に近いテキストが概ね作成され、時には正確な単語やフレーズの再現も見られた。
例えば、「I don’t have my driver’s license yet」(まだ運転免許証を持っていない)という文章を聞いた場合、システムは「She has not even started to learn to drive yet.」(まだ運転を習い始めていない)という文章を出力した。単語は違うが、概ね意味は合っている。
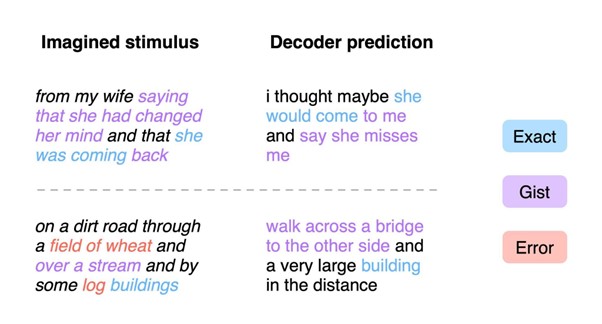
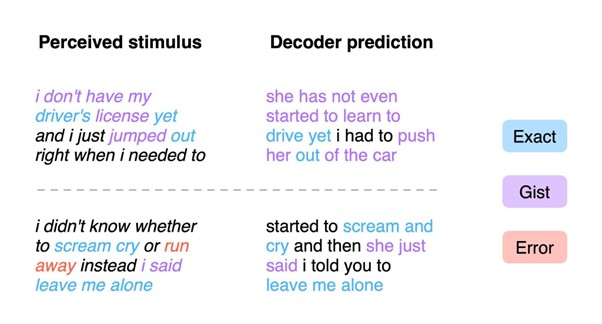
ただし、現時点では、聞こえてくる音声に参加者が集中していないと予測することはできず、例えば動物の名前や数字など別のことを想像していると、音声を聞いていても妨害され正確に取得できない結果が示された。また、訓練した参加者たちとは別の未訓練の人に試しても、うまく復元することができなかった。
次に、音声のない無音動画を4本見せた際の脳活動を記録し、そのシーンをテキストで再現できるかをテストした。その結果、ユーザーの見ている内容を意味的に合った内容の文章で出力することに成功した。

例えば、上図では「彼女はとても弱っていたので、呼吸を整えるために首を押さえた。」「私は、似ている女の子が背中を殴られ飛ばされるのを見た。」と出力されたように、概ね意味が合っているのが確認できる。
音声や無音動画を脳活動から復元するタスクにおいて、意味的に高い精度を示した本システムだが、fMRI装置に依存するため、研究室以外での使用が難しいのが現状だ。そのため研究者らは、機能的近赤外分光法(fNIRS)のような、より携帯性の高い他の脳画像システムに応用したいと考えている。
Source and Image Credits: Tang, J., LeBel, A., Jain, S. et al.Semantic reconstruction of continuous language from non-invasive brain recordings. Nat Neurosci (2023). https://doi.org/10.1038/s41593-023-01304-9
関連記事

脳に埋め込んだ電極で「発話内容」を読み取りテキストと音声に変換する技術 1分62英単語の高速出力に成功【研究報告】

「合成脳」10万枚を公開 画像生成AIで脳のMRI画像を医療用に大量生成 欧米の研究者らで実施【研究紹介】

育てた人の脳細胞をコンピュータに接続、生きたAI「Brainoware」で学習し数式を解くことに成功【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


