![]()
![]()
見ている画像を脳活動から画像生成AIが高品質に再現 フランスの研究者ら「Brain-Diffuser」開発【研究紹介】
2023年3月17日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
フランスのCerCo、トゥールーズ大学、ANITIに所属する研究者らが発表した論文「Brain-Diffuser: Natural scene reconstruction from fMRI signals using generative latent diffusion」は、潜在拡散に基づく生成モデルを用いてfMRI(磁気共鳴機能画像法)パターンから画像を再構成するフレームワークを提案した研究報告である。参加者に画像を見せた際の脳活動(fMRI信号)から、潜在拡散モデルを含むフレームワークでその画像に類似した画像を生成する。
研究背景
近年では、脳信号から情報をデコードする新しい方法が研究されている。視覚の研究分野では、統計的手法や機械学習を用いてfMRIの神経活動から特定の情報(位置や方向など)を解読したり、画像のカテゴリを予測したり、候補セットから模範画像を一致させたり、単純な形状や構造など複雑さの低い画像を再構築したり、といった研究が数多く行われている。
一方で、深層学習モデルが進化した影響を受け、多くの研究が深層生成モデルを利用して画像全体を再構成する潮流が生まれた。これらの深層生成モデルには、変分オートエンコーダ(VAE)、敵対的生成ネットワーク(GAN)、そして最近ではテキストから画像を生成するタスクで有名になった潜在拡散モデル(LDM)などがある。これらの研究のほとんどは、既存の深層生成モデルを使用し、大規模なデータで事前学習した後、マッピングを学習して(単純な回帰またはより高度なニューラルネットワークアーキテクチャ)、脳信号から対応する潜在変数を再構築する。
研究概要
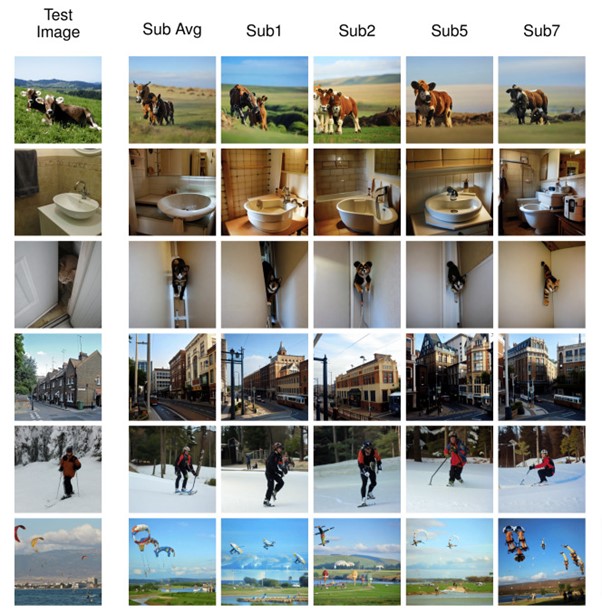
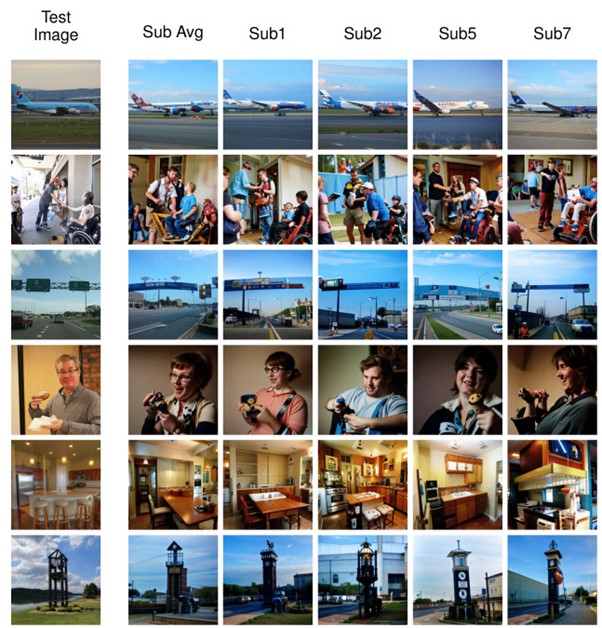
今回のようなfMRIによる脳活動から自然画像を再構成するタスクは、これまでにも多数研究されている。そして上記のような様々な手法で再構成が行われてきた。データセットも進化しており、最近では、8人の参加者が画像データセット「COCO」を閲覧しながらfMRI測定を行った、「Natural Scenes Dataset」(NSD)というデータセットが活用されている。含まれている画像の数、多様性、複雑性から、ごく最近であるが、fMRIに基づく自然画像再現タスクにおいてベンチマークとなりつつある。
今回の研究でもNSDデータセットを活用する。このデータセットから画像を再構成した研究はすでに3件あり、それらをベースラインとして本モデルの性能を比較する。3件の中には日本の研究者らの成果も含まれている。大阪大学大学院生命機能研究科と情報通信研究機構CiNetに所属する高木らは、fMRIで得られた脳活動から潜在拡散モデル「Stable Diffusion」を用いて画像を再構築した研究を発表している。この研究は、2023年6月に開催予定の国際学会CVPR 2023に採択された論文である。
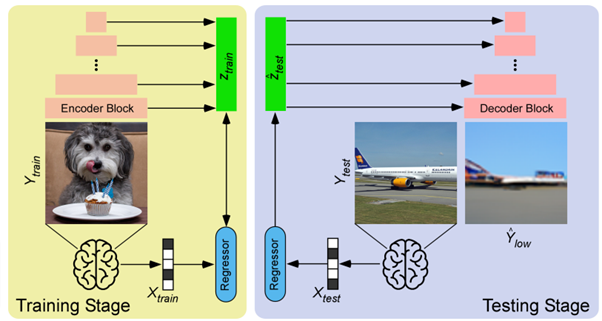
今回の研究でも潜在拡散モデルを活用するが、「Stable Diffusion」ではなく「Versatile Diffusion」を用い、さらに低レベルの画像生成、視覚と言語表現の両方を条件とした2段階フレームワーク「Brain-Diffuser」を提案する。
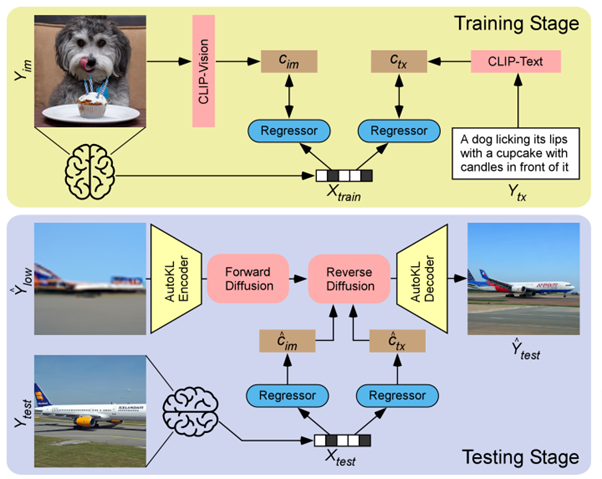
フレームワークの第1段階では、VDVAE(Very Deep Variational Autoencoder)を用いて、画像の低レベル再構成(初期推測のようなもの)を生成する。この再構成は、同じトレーニング画像について、fMRI信号をVDVAEの対応する潜在変数に関連付ける回帰モデルをトレーニングすることによって生成される。fMRIパターンからCLIP-Visionの特徴(対応する画像をCLIPモデルに供給して抽出)と、CLIP-Textの特徴(対応する画像のキャプションをCLIPモデルに供給して抽出)を抽出して条件とする。
第2段階では、テスト画像の最終的な再構成を行うために、事前に学習したVersatile Diffusionモデルの画像間能力を使用する。Versatile Diffusionモデルの画像間パイプラインを使用して、第1段階で生成した初期推測から出発し、予測されたCLIP-VisionとCLIP-Textの両方の特徴に導かれながら、拡散による最終再構成を生成する。
評価実験
Brain-Diffuserの実力を評価するための実験を行った。その結果、Brain-Diffuserで生成されたシーン画像は、元画像と完全には一致しないものの、レイアウトや意味情報のほとんどが保持されていることが確認された。またデータセットが同じ先行研究3件の再構成画像と比較して、より自然に見えることが確認された。定量的に評価しても、Brain-Diffuserは高レベルと低レベルの両方の指標において、従来のモデルを凌駕していることがわかった。

関連記事

AIの「共食い」はすでに始まっている。BingのAIがChatGPTからコロナに関する誤情報を引用【テッククランチ】

「コード」から「漫画」を自動作成するツール「CodeToon」。カナダの研究者らが開発【研究紹介】

「合成脳」10万枚を公開 画像生成AIで脳のMRI画像を医療用に大量生成 欧米の研究者らで実施【研究紹介】
人気記事

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?

Rubyへの型導入、実際にどんな利点がある? 壊さず進める大規模コード改善の実践知


