![]()
最新記事公開時にプッシュ通知します
![]()
カメラ1台で多人数の全身の動きを3Dモデルで復元する技術 背景の3Dシーンも一緒に再現【研究紹介】
2023年1月24日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
ドイツのMPI Infoに所属する研究者らが発表した論文「Scene-Aware 3D Multi-Human Motion Capture from a Single Camera」は、静止した単眼カメラ1台で撮影した映像から複数の人間の全身の動きと3Dシーンを同時に予測する手法を提案した研究報告である。シーン内の複数の人間の絶対的な3次元位置、体型、関節をグローバルかつ時間的にコヒーレントに推定する。競合手法よりも高い3次元再構成精度を達成し、取得した動きでバーチャルキャラクターを動かすことにも成功した。

研究背景
ゲーム開発、VR/ARなどにおいて、シーン内の複数人の絶対的な3次元位置や体型などを推定することは、基礎的な研究課題である。そのため、マルチビューシステムやモーションキャプチャースーツなどの高度で高価な機材を用い、手動または半自動で追跡したモーションをノイズ除去し、そのモーションを用いてバーチャルキャラクターをアニメーションさせるといった研究が長年にわたって行われてきた。
しかし、高価な機材が必要なため一般ユーザーが導入するにはややハードルが高くスケールしていないのが現状である。手軽さを考え、単眼のRGBカメラ1台でキャプチャーして人体の3次元姿勢、形状推定を行う研究も進められているが、被写体が障害物に隠れたり、被写体同士が重なったりすると正確に再構築できない、そのうえ奥行きを捉えるのが苦手など、まだまだ発展途上の技術である。
研究内容
本手法ではこれらの課題に挑戦するため、静止カメラで撮影された単眼RGB映像から、シーン内の各人物の絶対位置、形状、ポーズ、およびシーンスケールを推定する新しい手法を提案する。実現するため、2次元関節の検出、SMPLパラメータ、視差マップ、人間のセグメンテーションマスクの4つのモダリティを同時に考慮して、これらに対して大規模な事前学習済みモデルを用いる。
まずシーン内の人間の2Dおよび関節角推定値を事前情報として、視差予測からシーンの絶対深度と人物固有のスケールを推定する。フレームごとの絶対深度が分かったら、予測されたセグメンテーションを使用して人間をセグメント化し、フレームごとの深度を時間的に集約することによって、絶対3D空間における静止シーンの高密度点群を再構成する。最後に、集約されたシーン推定と関節角度の予測を利用して、物理的妥当性と同様に時間的・空間的一貫性を確保するために、シーケンス全体に対して最適化を実行する。
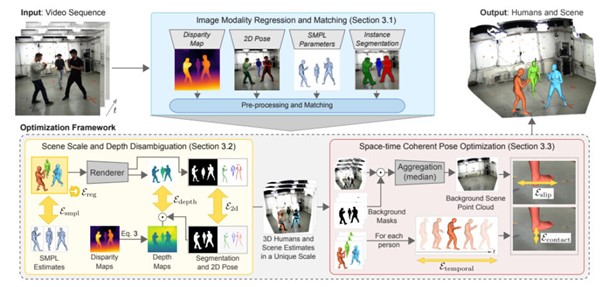
研究結果
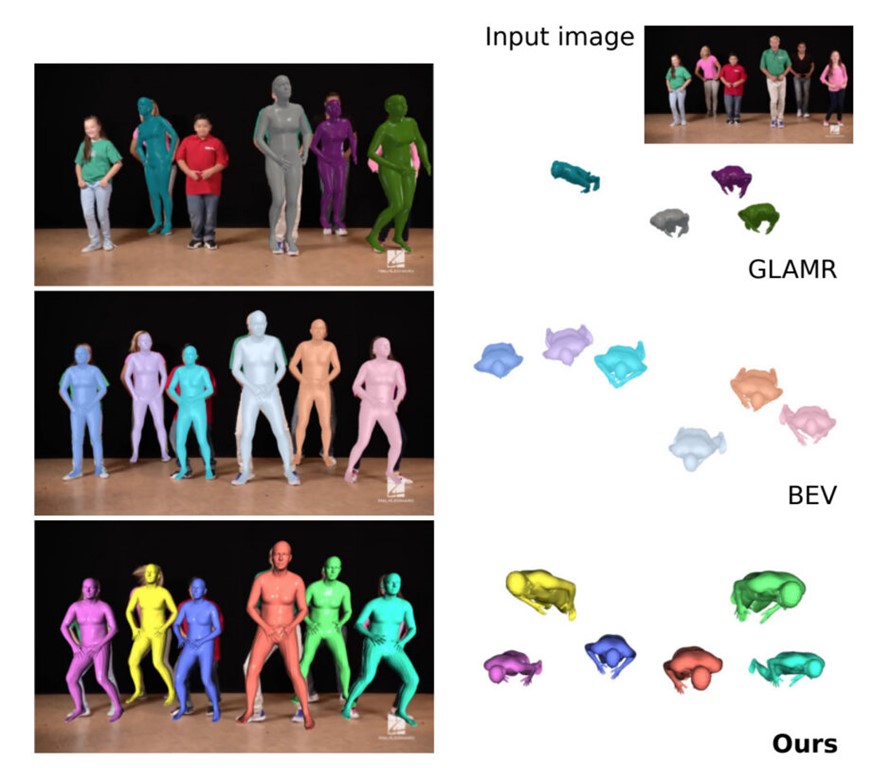
提案モデルによって出力された結果は精度が高く、多人数3D姿勢推定において、ベースラインよりも大幅に高い再現性を示した。アブレーション研究により手法のすべての構成要素が最終的な精度に寄与していることが確認された。
特に、再構築した際のちらつきと足裏の貫通などのアーティファクトが少なく、違和感のない出力結果になっている点がリアリティを高めている。

また人物同士の距離感も入力に忠実な出力となっている。従来の方法で複数人をキャプチャーした場合、人物同士の奥行きを正確に捉えることができず、正しい位置付けができない。前の人との距離が異常に離れていたり、近すぎたりする現象である。その点、提案手法はこの人物同士の奥行き感を正確に捉え、正しく位置付けが行える。これらの点から定性的に不自然が少ない仕上がりになっている。
提案手法の応用としては、取得した動きをバーチャルキャラクターに転写し、同じ動作をさせるモーションリターゲティングが考えられる。

Source and Image Credits: Luvizon, Diogo Carbonera, Marc Habermann, Vladislav Golyanik, Adam Kortylewski and Christian Theobalt. “Scene-Aware 3D Multi-Human Motion Capture from a Single Camera.” (2023).
関連記事

イスラエルと米国の研究者らが開発 3Dモデルを簡単編集できるAIシステム「GeoCode」【研究紹介】

スマホを90度に曲げ、奥行きをリアルに感じながら立体物を編集できる3Dモデリングツール「AngleCAD」【研究紹介】

ピタッとくっつく3Dキャラクターの足と地面、より自然な動きに NVIDIAが物理ベースの拡散モデルを開発【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


