![]()
最新記事公開時にプッシュ通知します
![]()
「合成脳」10万枚を公開 画像生成AIで脳のMRI画像を医療用に大量生成 欧米の研究者らで実施【研究紹介】
2022年9月26日


先端テクノロジーの研究を論文ベースで記事にするWebメディア「Seamless/シームレス」を運営。最新の研究情報をX(@shiropen2)にて更新中。
英King’s College London、米National Institute of Mental Health、英Birkbeck College、英University College Londonによる研究チームが発表した論文「Brain Imaging Generation with Latent Diffusion Models」は、拡散モデルを用いた方法で脳のMRI画像を大量に生成し、医療用の大規模な脳合成データセットを作成した研究報告だ。
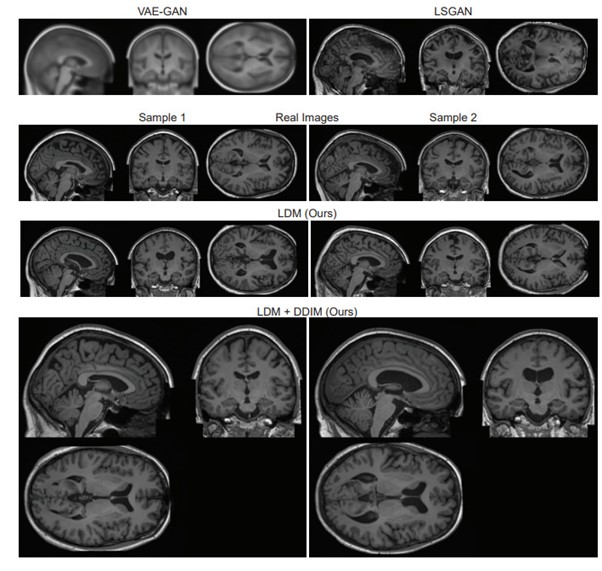
研究背景
深層学習モデルは、自然言語処理やコンピュータビジョンなどの分野でいくつかの画期的な進歩を促したが、これらの一部は、ネットワークを訓練するために使用される大量のデータセットに起因する。
同時期に医療画像解析も、セグメンテーション、構造検出、コンピュータ支援診断などのタスクを解決するために深層学習モデルを適用し、著しいブレークスルーを遂げた。だが、現在の医療用画像プロジェクトの限界の1つは、大規模なデータセットが利用できないことである。プライバシー保護の観点から、一般に公開されている医療データセットは数千例までと制限されており、データ共有に困難が伴う。このような制限は、モデルの一般化においてボトルネックとなり、最先端の手法が臨床に導入される速度を低下させる。
一方でプライバシーが保証された合成データの生成は、有意義な研究を大規模に実施する有望な代替手段を提供する。これらの合成データは実データを補完し、深層学習モデルの訓練データを劇的に増加させる。しかし、意味のある合成データを生成することは、特に脳のような複雑な器官を考えると簡単ではない。
そこで登場したのが拡散モデルだ。近年、拡散モデルは自然画像の合成において有望な結果を示し、機械学習界隈で注目を集めている。拡散モデルは、強固な理論的基盤の上に構築しながら、サンプル品質においてGAN(Generative Adversarial Network)に匹敵する。印象的なフォトリアリズムの無条件画像を達成しただけでなく、クラスやテキスト文を条件とする画像を生成するために用いられ、OpanAIのDALL·E 2やGoogleのImagen、Stable DiffusionなどといったText to Imageモデルで一般的にも注目を集めている。
研究概要
本研究では医療用データが少ない課題を解決するため、拡散モデルを用いて成人の脳の合成MRI画像を大量に作成する手法を提案する。
高解像度脳画像から合成画像の生成を実現するために、入力データを低次元の潜在的表現に圧縮するオートエンコーダーと拡散モデルの生成モデリング特性を組み合わせた潜在拡散モデル(Latent Diffusion Model)を使用する。またUK Biobankの31,740枚のトレーニング画像を用いてモデルの学習を行った。
その結果、提案モデルを用いて現実的で高品質な合成脳画像が生成できるとわかった。出力結果の品質も高く、以前のGANベースのアプローチを凌駕する精度を示した。
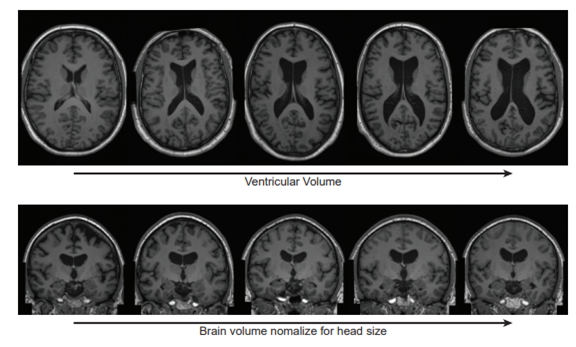
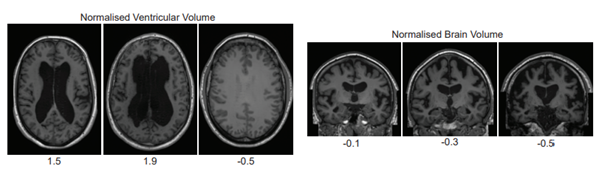
さらに、年齢、性別、脳室容積、頭蓋内容積などの共変量に条件付けすることで、期待通りの表現が得られる制御性も実証した。この制御を活かして、脳室容積と年齢を分析した結果、入力値と観測値の間に高い相関関係があることもわかった。
また、大容量な脳室を作成したり、脳室を完全に削除したりして、見たことのない合成脳を生成できるとわかった。
研究者らは、このように生成した脳画像10万枚からなる合成データセットを公開した。これによって世界中の研究者らは、従来では収集が難しいプライバシーを考慮した訓練用脳画像データを豊富に入手することができる。
今後は、放射線レポートなど、他のスキャンモダリティを条件付けとして用いるモデルを開発する予定としている。
参考情報:LDM 100k Dataset
Source and Image Credits: Pinaya, Walter HL, et al. “Brain Imaging Generation with Latent Diffusion Models.” arXiv preprint arXiv:2209.07162 (2022).
関連記事

「コード」から「漫画」を自動作成するツール「CodeToon」。カナダの研究者らが開発【研究紹介】

1枚の写真から作成する動くメガピクセル頭部アバター。ロシアチームが開発【研究紹介】

3Dモデルの質感を好きな画風に変えられるスタイル変換モデル NVIDIAなどが開発【研究紹介】
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


