![]()
最新記事公開時にプッシュ通知します
![]()
「クマ遭遇AI予測マップ」を開発して見えたもの。人流解析のプロが野生動物の世界に挑んだ所感【フォーカス】
2025年11月19日

![]()
上智大学 応用データサイエンス学位プログラム 准教授
データサイエンティスト
深澤 佑介
機械学習応用や時空間データ解析を専門とする。株式会社NTTドコモに19年間在籍し、携帯電話の運用データに基づくモバイル人口統計の実用化研究等に従事。人々の移動需要や飲食店の需要予測など、都市空間における人流解析の最前線で活躍。2023年4月より上智大学准教授。
クマ遭遇AI予測マップ(上智大学 深澤研究室サイト内)
researchmap
連日のようにクマによる人身被害が報じられ、状況が深刻化しています。環境省の2025年10月17日付発表によると、今年度のクマによる死者数はこの時点で7名で、過去最多。この状況に対し、さまざまなアプローチでのクマ対策が各地で進んでいます。
そんな中、都市の「人流」解析のプロでありながら、現在はクマの「遭遇」予測に注力しているデータサイエンティストがいます。上智大学准教授の、深澤佑介さんです。かつてNTTドコモに19年間在籍し、携帯電話の運用データに基づく「リアルタイム人口統計」を活用し人々の移動需要や飲食店の需要予測など、都市の時空間データ解析の最前線で活躍してきました。
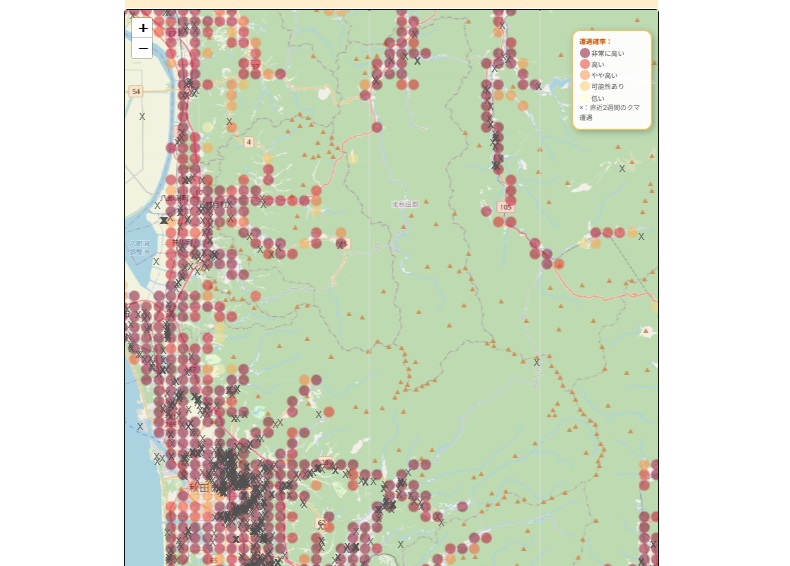
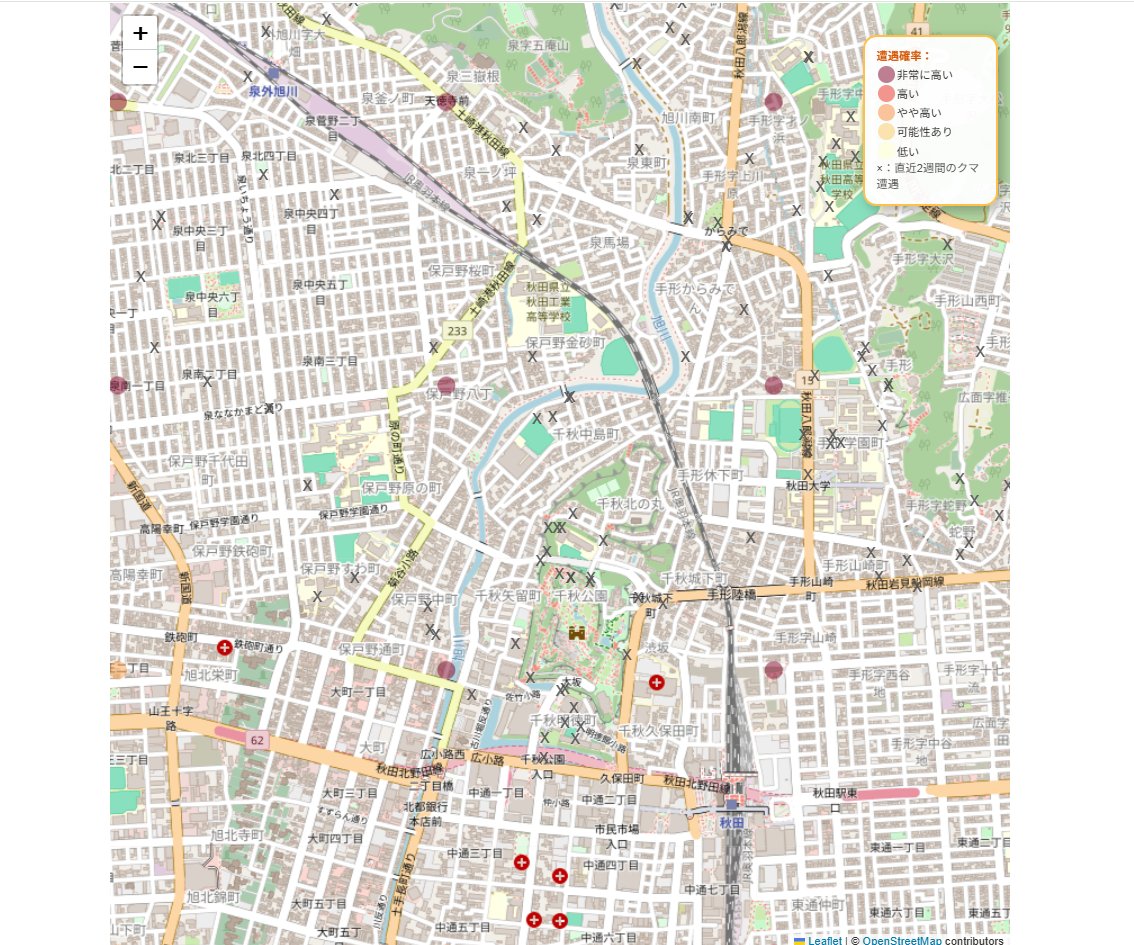
そんな深澤さんは10月、研究室で開発した「クマ遭遇AI予測マップ」をWebサイトで一般公開。これは過去の遭遇記録や人口分布、土地被覆、標高、周辺道路の情報といったデータをAIで統合し、1kmメッシュ単位でクマとの「遭遇確率」を予測・可視化するものです。秋田県に始まり、札幌や東京など、予測対象のエリアを次々に拡大しています。
2025年7月には、その基盤技術に関する論文が国際学術誌にも掲載されました。発表時点で、このAIモデルの予測精度はテストの結果「正答率63.7%」と評価されています。
「人流」予測の専門家が、なぜ今、野生動物の世界に挑むのか。そして、今回の研究を通して見えてきた、クマ予測ならではの高精度化を阻む技術的な壁とは。「研究を通して、クマと人の遭遇の発生を左右する、意外な『要素』の存在も少しずつわかってきました」と語る深澤さんに、今回の研究開発の所感についてお聞きしました。
ディープラーニングではなく、特徴量エンジニアリングでアプローチ
――まず、「クマ遭遇AI予測マップ」の概要についてお教えください。
深澤:このモデルは、過去のクマとの遭遇記録、人口分布、土地被覆(その土地が何に覆われているか)、標高、道路情報など、さまざまなデータを統合してAIに学習させ、「遭遇確率」をマップ上に出力しています。
ここでの遭遇確率はわかりやすくいうと「過去にクマとの遭遇が起きた場所と、どれだけ環境条件が似ているか」を示すスコアです。例えば、マップ上で確率0.9と表示された地点は、過去に遭遇が報告された場所と、人口の分布、土地被覆、標高といった諸条件がかなり似通っている、と解釈できます。そのため、同様に遭遇リスクが高い可能性がある、ということを示しています。
ご注意いただきたいのが、このマップはクマの「出没」ではなく、人とクマの「遭遇」のリスクを予測している点です。
クマが山中に姿を現す「出没」は、人がいない場所でも起こり得ます。しかし、私たちがデータとして取得できるのは、あくまで人とクマが出会ってしまった「遭遇」の記録です。AIカメラなどで全域を監視しているわけではないので、人が目撃していない「出没」データは入手できません。ですから、このモデルは人間とクマの「遭遇」が、いつ、どこで発生する可能性が高いかを予測することに主眼を置いています。
なお、予測モデルとして伝統的なツリーベース(Random Forestなど)の手法だけでなく、ディープラーニングやTransfomerを含め様々なモデルを検証しましたが、精度検証の結果、ExtraTreesというツリーベースの手法の精度が高かったです。これは、データが少量でTransfomerやディープラーニングではうまく学習が進まないことや、系列データではなくテーブルデータとして扱ったためツリーベースの手法が向いていたと考えています。そのため、公開している情報は基本的にツリーベースのモデルを用いた予測に基づいています。

――NTTドコモでは携帯電話ネットワークの仕組み等を利用した「人流」の解析を専門としてきた深澤さんですが、なぜアカデミアに転身し、研究テーマとして「クマ」を選ばれたのでしょうか?
深澤:2023年の春、上智大学に着任した私は「何か新しいことをやりたい」と考えていました。人工知能やデータサイエンスに関わる人間として「未来を予測する」というのは常にひとつの目標です。そして、時空間データを使って人のリスクに関わるような、より直接的な社会課題の解決に貢献したいという思いがありました。
そんな時、学生と話す中で「2023年にクマの目撃件数がものすごく増えている」という事象が話題になりました。
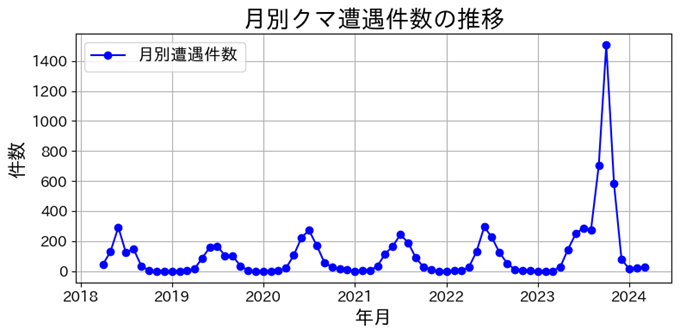
深澤:2023年以前は、年ごとのクマの遭遇件数はある程度範囲が決まっていました。しかし、2023年の9月、10月に異変が起き、遭遇件数が爆発的に増えました。しかも、森や山だけでなく、これまでは遭遇がなかった市街地に近いエリアにまで遭遇範囲が広がっていました。
そこで「これまで培った時空間データ解析のノウハウを使って、この“これまでは出ていなかった場所で起き得る遭遇”を予測できないか」と考えたのです。
――深澤さんは都市の「人流」解析が専門ですよね。いわばクマの「生態」に関するドメイン知識がない状態から、どのようにして有効なデータを選び、モデルを構築していったのですか?
深澤:当然、最初からどのデータが有効かわかっていたわけではありません。遭遇予測に着目した先行研究もほとんど無かったため、手探りで進めました。
まずは人とクマが交錯する場所、つまり「人の居住地」と「クマの生息域」が重なる場所を捉えることから始めました。前者については国勢調査のデータを、後者についてはクマが生息しやすい落葉樹林などの植生情報をJAXAが公開している土地被覆図のデータから取得しています。
そして自分なりに文献を調べつつ、さまざまな仮説のもと、例えば国土交通省の「道路情報」や「標高データ」、気象データ、そしてクマの食糧に関わる「ブナの実の豊凶情報」といった各種の特徴量を試行錯誤しながらモデルに投入していきました。
そうして構築したモデルがどれほどの精度を持つかについて、実際のデータでの検証も行っています。例えば秋田県のモデルでは、2021年と2022年の遭遇記録データをAIに「訓練データ」として学習させ、そのモデルが2023年に実際に発生した遭遇記録(テストデータ)をどれだけ正確に予測できたかを、「正答率(Accuracy=論文では63.7%)」等の指標で評価しています。
そして、どのデータが予測精度に有効だったかを見極めるために、モデルを構築した後にSHAP(※1)という手法で分析し、「どのような特徴量が予測に効いているのか」という考察も繰り返し行ってきました。
(※1)SHAP (SHapley Additive exPlanations):AIの予測結果に対し、各特徴量(データ)がどれだけ貢献したかを数値化し、判断根拠を可視化する技術。「説明可能なAI(XAI)」を実現する代表的な手法。
――いわば異常な年であった2023年の遭遇記録を、テストに用いていたとは。そこに至るまでの道のりは、データを入れて、結果を見て、また理由を探るという地道な作業の繰り返しなんですね。
深澤:ただ、SHAP分析で「このデータが予測に効いている」とわかっても、その「理由」がすぐには理解できないことも多々ありました。
例えば、研究を進めるうち、土地被覆において「川」や「湿地帯」の情報が予測におおきく影響すると分かってきたのですが、最初は
「なんで湿地帯が効くんだろう? クマが水でも飲みに来るのかな?」
と不思議に思っていたんです。
深澤:後からクマの生態学の専門家の方に聞いてみたりしてわかったのですが、クマとの遭遇が多く発生している川は、岸辺が藪になっていることが多いんですね。どうやらクマはこの藪を“道”のように伝って、夜の間に市街地へ移動してくるらしい、と。だから、朝になって「街中に突然現れた!」と驚くようなケースがあるみたいなのです。
このように、データサイエンス的な発見と、生態学的な知見が後から結びつく、という経験が何度もありました。

「遭遇しなかった」データまでは存在しない。“データ不均衡”との闘い
――SHAP分析を通して、特に「興味深い」と感じた発見はありましたか?
深澤:ぱっと思い浮かぶものが2つあります。
1つは「高齢者の人口分布」、特に「85歳以上の人口」が、遭遇予測において非常に重要なファクターになるとわかったことです。
当初はなぜだろう? と疑問に思っていました。もちろん、クマが特別、あえて高齢者を狙って襲っているわけではありません。
しかし、クマの専門家の方々と話す中で仮説が見えてきました。高齢化が進んだ地域というのは、結果として放置された「空き家」や「耕作放棄地」が増えやすい。そして、そこには餌としてクマを誘引する「放置された柿の木」などが残されていることが多いんだそうです。
つまり、AIは「柿の木」のデータを直接学習しているわけではありませんが、いわば「高齢者の人口分布」という代理変数から、「クマのエサとなる誘引物がある場所」のパターンを学習していたのではないか? と解釈しています。
――年齢分布のデータが、結果的に「放置された誘因物」の存在を反映している可能性がある、と。
深澤:次は、「直近1か月の出没場所」よりも「1年前の同時期の出没場所」という特徴量の方が、予測への寄与度が大きかったことです。
普通に考えれば、「昨日出た場所の方が1年前に出た場所より危ない」と感じるかもしれません。しかし分析結果は逆でした。一体どういうことなのか。
これもあくまで仮説ですが、まず「直近の出没」のデータは、クマが川沿いを移動中に偶然「通りすがった」結果が多分に含まれています。しかし「1年前にも出ていた場所」というのは、そこに柿の木のような何か固定の「誘引物」があり、クマが「あそこにはエサがある」と学習して毎年のように再訪している可能性があるのです。だから、予測精度に大きく影響しているのでは? と。
――それは非常に興味深い気づきですね。それでは、クマの予測ならではの技術的な困難や課題において、実感したものがあれば教えてください。
深澤:特に大きかったのは、データの「不均衡」の問題です。
特に困ったのが、「遭遇したデータ」(正例)は世の中にあるけれど、「遭遇しなかったデータ」(負例)は存在しないということです。これは単純に、クマの目撃情報が出ていない地点を、「遭遇しなかったデータ」として学習させればよいというものではありません。例えば山奥の場合は通例人が立ち入らないから、遭遇報告が上がってきません。しかし、恐らくクマは生息していますよね。なので「遭遇しなかった」をどう定義するかが非常に難しい。
しかしこの「負例」のデータがないと、AIは「遭遇した」ケースと「遭遇しなかった」ケースの比較ができなくなり、何を学習すればよいか分からなくなってしまう。
そこで我々は2段階の方法で負例データを作成しました。まず、実際に遭遇があった場所(正例)のすぐ近くで、土地の条件が酷似しているけれど、遭遇報告がなかったメッシュを「負例」とみなします。これにより、モデルは「条件は似ているのに、なぜ片方でだけ遭遇が起きたのか」という微妙な差を学習できるようになる。
しかし、これだけだと山間部のデータばかりに偏ります。そこで次に、都市部なども含めた、学習対象の自治体の全域からランダムにメッシュを抽出し、それらも「負例」として加えます。こうすることで、モデルは例えば「都心のような場所では遭遇は起きない」ということも学習できるようになり、地図上にリスクのグラデーションを描けるようになるのです。
――その2段階のサンプリングが、予測モデルの肝だったんですね。
深澤:こうして、モデルの基盤が完成しました。しかし、このアプローチを全国に展開しようとすると、新たな壁にぶつかります。それは、自治体ごとの「クマ目撃情報の収集方法の違い」です。
例えば秋田県では「クマダス」という、警察や住民から寄せられたクマの目撃情報を登録・閲覧できるシステムの運用が活発で、データの粒度も全国トップクラスです。
深澤:一方で、自治体によってはこうしたシステムが整備されておらず「クマを目撃したらメールにて自治体に報告してください」との形式がとられていることもあります。これでは、特に高齢化が進む地域だと、なかなかデータが集まりません。
そしてデータの数が極端に少なく、かつ全域において地形条件が似ている県だと、AIが特徴の違いを学習できなくなります。
結果として、地図全体が真っ赤(どこも危険)になるか、真っ白(どこも安全)になるというような、両極端な予測しかできなくなる。実際「クマ遭遇AI予測マップ」では、こうした理由から適切な予測ができず、マップの公開を見送っているエリアもあります。このようにクマの目撃情報について全国的に統一されたデータが無いというのは、大きな壁のひとつです。

遭遇リスク「高」だけに注目するのは……
――この研究の、今後の展望についてお聞かせください。
深澤:ある程度手法は確立できたので、さらに精度を上げていくこと。そして、「解釈可能性」の向上に取り組みたいです。たとえば、遭遇確率が高くなっている場所について、単に確率の数字だけでなく、「クマの遭遇が起きやすい川の湿地帯に近いためご注意ください」など、その理由も提示することで、遭遇確率が高いとされる背景についてユーザーにご納得いただけるのではないかと考えています。このマップはあくまで研究成果の社会還元を目的としており、自治体などで活用していただけるのであれば非常にありがたいと考えています。
――ちなみに自治体やユーザーが「クマ遭遇AI予測マップ」を活用するとしたら、注意した方がいい点はありますか。
深澤:「適合率(※2)」と「再現率(※3)」のトレードオフでしょうか。
(※2)適合率(Precision):「クマに遭遇する」とAIが予測した場所のうち、実際に遭遇が発生した割合。論文発表時点では、63.5%の評価。
(※3)再現率(Recall):実際に遭遇が発生した場所のうち、AIが予測できていた割合。論文発表時点では、63.6%の評価。
――詳しく教えてください。
深澤:このマップでは、1kmメッシュごとにで遭遇確率を表しています。確率ごとに、「非常に高い」で0.8~1.0、「高い」で0.6~0.8、「やや高い」は0.4~0.6、「可能性あり」は0.2~0.4、「低い」は0.0~0.2に分類しています。
ここでもし利用者が「非常に高い」と予測された、真っ赤な場所だけに注目するとします。
そこで実際にクマが出れば予測は当たったことになり、適合率は高くなります。ここだけに着目するのが一見、効率的に思えるかもしれません。
しかし現実問題、マップの検証結果を見ると、確率の基準値を高く設定するほど、再現率は下がっていくんです。なぜなら、実際の遭遇は、AIが「やや高い」(0.4〜0.6)や「高い」(0.6〜0.8)と予測したエリアでも多く発生するからです。
つまり、「『非常に高い』と予測された場所以外は安全だ」と判断して注目しないでいると、他のエリアでの実際の遭遇を「見逃す」ことになってしまう。平たくいえば「『非常に高い』とまでは予測されなかったエリアで油断しているところに、クマに出くわす」ことがあり得るわけです。
そのため、このマップでは、人命に関わる見逃しを防ぐことを最優先に考え、再現率を重視しています。「非常に高い」リスクの場所だけでなく、「やや高い」や、自治体によっては「可能性あり」と表示された、より広いエリアから警戒することを推奨しています。
さらに、人によってリスクへの評価は変わってくるはずです。例えば東京から初めて秋田に旅行する方と、地元に慣れた方とでは、クマの生態に関する知識や土地勘も異なってくる。当然、不慣れな方であるほど、遭遇リスクが低い地域でも警戒していただいたほうがよいかと思います。状況やユースケースに応じて、リスク評価については慎重に判断していただければと思います。
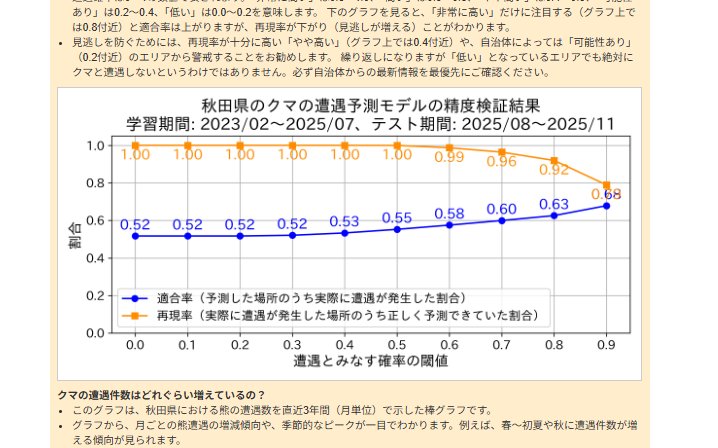
――ちなみに、「正答率63.7%、適合率63.5%、再現率63.6%」という数字(論文発表時点)をご自身ではどう評価されていますか?
深澤:例えば特徴量とクラスの関係が非常に複雑なクラス分類問題の場合、クラスごとのサンプル数が同量だとすると経験的には精度が7割を超えれば「予測としてかなりうまくいっている」といえます。逆に6割を切ると、特徴量とクラスの関係性が怪しまれることが多い。その点、63.7%という数字は「決してランダムではない、何らかの傾向がデータの中に確かに存在する」ことを示しているラインかと考えております。
そして人流データに取り組んでいた時は、人が対象なので人流のデータから全体像を把握することができました。
しかし、クマの場合はそうはいきません。私たちが得られるのは、あくまで「たまたま人間と遭遇した」という記録だけで、クマの全体像がわからないまま予測しなければならない。そこが非常に難しい点でした。
そんな中でも、6割を超える精度が出たことで、データサイエンスのアプローチがこの問題にも通用するという手応えを感じられたのは、ポジティブな発見として捉えています。ただ先ほどの通り、データが少ない地域ではまだまだ予測精度に課題があります。今後は、遭遇記録以外にも、予測精度を高められる術がないかを模索していきたいと考えています。そのようにしてデータサイエンスの力で、皆さんの安全に少しでも貢献できればと思います。

取材・執筆・編集:田村 今人
撮影:曽川 拓哉
関連記事

祖父の「銃声」で人々を守りたい。クマよけアプリ「BowBear」に込められた北の猟師の知恵【フォーカス】

“アニサキス殺し”パルスパワーは「器用貧乏」な技術だった 「電気エネルギー界のドラえもん」が拓く未来【フォーカス】

5指駆動「サイボーグ義手」が実現した理由。“実用化だけ”を見据えた研究者たち【フォーカス】
人気記事

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理

国産組込みOS「ITRON」が40年生き残ってきた理由を、生みの親と振り返る【TRON】

インデックスを張るだけでは足りない。数億件の名刺データを扱うSansanのSQLパフォーマンス改善

