![]()
最新記事公開時にプッシュ通知します
![]()
【スゴ本】知らないと現場が燃え尽きる。システム障害対応で本当に優先すべき5つのこと
2026年2月26日


古今東西のスゴ本(すごい本)を探しまくり、読みまくる書評ブログ「わたしが知らないスゴ本は、きっとあなたが読んでいる」の中の人。自分のアンテナだけを頼りにした閉鎖的な読書から、本を介して人とつながるスタイルへの変化と発見を、ブログに書き続けて10年以上。書評家の傍ら、エンジニア・PMとしても活動している。
わたしが知らないスゴ本は、きっとあなたが読んでいる
- はじめに
- 1. 現場をまとめる「旗振り」を決める
- 2. メンバーの健康維持のための「今晩の宿」を確保する
- 3. 「War Room」をつくり、情報を集約・可視化する
- 4. 陥りがちな罠を見極め、二次被害を避ける
- 5. 責任転嫁のための「犯人探し」をやめさせる
- おわりに
はじめに
「システム障害」でネット検索すると、するべきことが書いてある。
- ・影響範囲を調査する
- ・原因を突き止める
- ・復旧対策を実施する
そんなことは知っとるわ!
調べても、ありきたりなことしか出てこない。問題はそこではない。部分的にしか見えない流動的な状況において、錯綜する情報を元に、何を優先しどう対応していけば良いか、分からないことにある。
障害が起きると、「まず業務の継続を優先せよ」と言われる。
だが、どうすれば継続できるか、ある程度原因が分からないとどうしようもない。そして、原因のあたりをつけるためには影響調査と被疑対象の絞り込みが必要だ。
しかも、事態は流動的で、全体が見えない状況下でだ。システムが巨大で複数の組織や企業やサービスに渡るものであるほど、さらに難度が上がる。
『システム障害対応の教科書』は、まさにそんな状況での基本的な動作と現場のマネジメントをまとめたものだ。システム障害の検知から原因調査、復旧対応までを網羅的に押さえている。

当然、ボリュームもかなりあるため、「いま」起きているトラブルを前にして読むようなものではない。
この記事では、本書をベースに、私の経験を交えた5つの勘所を解説する。
1. 現場をまとめる「旗振り」を決める
最重要はこれ。だけど、忘れられがちなのもこれ。
旗振りとは、システム障害に対応するチームのリーダーのこと。本書では、「インシデントコマンダー」と定義されている。主な役割はこれ。
- 1. 体制構築:対応するメンバーを集め、役割をアサインする
- 2. 兵站:メンバーのシフト・食事・宿泊を割り振る
- 3. 情報の一元化:原因解析、仮説検証、復旧対策の状況を集める
- 4. コミュニケーションのハブ:顧客や関連チームと連携する
旗振りを任された人は、まず障害の対応方針を決める。例えば、システムの復旧を優先するのか、データ汚染の拡大を止めるのか、原因の特定と障害エリアからの切り離しを第一に考えるのかなど、何を優先するのかは、障害の発生箇所によって異なる。
また、初期の解析によって優先度の再考が必要になる場合だってある(調べたらデータ汚染が他システムへ飛び火してたことが判明したとか)。刻々と変わる状況を可視化し、然るべきメンバーの検討と(必要に応じ)経営層も含めたジャッジを求め、解決に向けて全体を指揮する役割だ。
旗振り不在だとどうなるか?
本書によると、さながら「ちびっこサッカー」になるという。小さい子がサッカーするとありがちな、ボールに全員が集まってモブ状態となる、あれだ。
誰が何をするのか決まらず、場当たり的に「ログ取れる人が解析する」「電話を取った人が顧客対応する」といったやり方になる。全員が作業担当となるうちに、別のところから指示が飛んできて、優先度は吟味されないまま、全員がかかりきりになる。
すると、断片的な情報は集まっても、それが何を意味し、どう解決に結びつけることができるのか分からない。「どうなってるんだ!」というクレームに、どう答えてよいか分からない。関連システムへの影響調査の依頼や、経営層も含めた対応や、社外への発信が必要なのかも判断がつかない。
情報が錯綜すると、解析や復旧作業が重複し、データを壊すといった二次被害が出てくる(出前がかちあうというやつ)。あるいは、実施結果が検証されないまま復旧したかどうかの判断ができないといった状況に陥る。
組織的な対応が取れないから、できる人に作業が集中する。その人は、手を動かして解析する作業をし、原因と影響と復旧対策を考え、顧客や経営層に状況を伝えることになる。そういうスーパーマンも、ひとりの人である。数日から数週間と、時間が経過するにつれ、擦り減ってゆき、最悪の場合、壊れる。
そうさせないために、まず旗振りを決め、その旗振りに集まる様々な役割を、メンバーに振る。誰が手を動かし、誰が仮説検証し、誰が顧客応対をするのかを決める。増えていく情報の交通整理をしたり、記録するにも手が必要だろう。
旗振りを決める上で、最も重要なのは「旗振りと作業者を分ける」だ。
電話をしながら車を運転するのが危険なように、2つの役割を同じ人が担当すると、作業ミスによる二次被害・連絡漏れなどの可能性が高まるためです。作業担当が鳴り止まない電話に追われ、作業自体が遅延してしまうこともあります。
(『システム障害対応の教科書』 p.52)
これは本当にそう。サーバルームで電話しながら作業していると、電話対応と作業のどちらか(あるいは両方)をミスする。電話で伝えるべきこと、聞こうと思っていたことを失念する(電話を切った後にね)。あるいは、普段なら絶対にやらない作業ミスをする(取ったログを持って帰るのを忘れる)。
普通だと「分かっている人」や「できる人」が作業者になりがちなので、その場合は上司に旗振りを任せることになる(ここを一緒にして、作業者と旗振りを兼任させてはいけない)。
2. メンバーの健康維持のための「今晩の宿」を確保する
システム障害の最大の肝は、「いつ終わるか分からないこと」だ。
だから、まずヤバそうなトラブルだと感じたら、チームの宿を確保することを考える。会社泊を考えるのか、近くの宿泊施設を利用するのか、誰が泊まり、誰を帰すのかを考える。
「え?何が起きてどうすればよいか分からないのに、そこが先?」という人がいるだろう。だが、メンバーをどうやって休ませて、サイクルを回すかを最初に考えないと、限界まで働いて、場当たり的に休息を取ったりザコ寝になる。
1日2日ぐらいで済むならよいが、連泊連勤が続くとパフォーマンスは著しく低下し、最悪、体調不良者が続出する。そして復旧してほとぼりが醒めるころ、「辞めます」という人が出てくる。
システム障害の始まりはハッキリしており、「システムが動かない」「データがおかしい」といった問い合わせが来る。それは朝イチかもしれないし、終業間際かもしれない。深夜、通勤途中に連絡が来ることだってある。
だが、そのトラブルがいつ終わるかなんて、分からない。「ログやデータベースを調べれば分かるでしょ?」という人がいるが、原因や影響が分かっても、その復旧をどうするかまでは分からない。
一部のデータパッチを当てるだけか、ロールバックが必要か、プロセスを再立ち上げしなければならないか、また復旧作業の業務影響がどうなるか、業務担当と調整が必要になる。復旧を優先するのか、(一部不具合があっても)業務続行を優先するか、上層部の判断が必要になる。
要するに、システム障害は、多くの部署や担当、役職、企業、サービスをまたがっており、原因も、影響も、対策も見えない状況で進めるため、終わり方が分からないのが普通なのだ。
だから、トラブルが大きくなりそうだと感じた時点で長期戦を覚悟する。宿を予約した後に空振りしたら、笑ってすませばいい。重要なのは、メンバーの体調とチームのパフォーマンスだ。
ちょっと考えてみて欲しい。みんな通常の業務があるはずで、その上にトラブル対応をすることになれば、その時点でオーバーワークになる。緊急事態だから、一時的にハイになるかもしれないが、アドレナリンは保たない。エナドリ入れても24時間戦えません。
状況により、予定通りに休ませることにならないかもしれないが、それでも休むための余白をつくるのだ。
ホテルが確保できないなら、誰がいつスパ銭に行くかを決める。メンバーが少なくても、当番表をつくる。目を真っ赤にして「まだイケます」なんて言ってくれる人もいるが、強制的に休ませる。ワンオペなら休息を入れたサイクルを先に考える。
「トラブルでも頑張った」としても、せいぜい上司が労いの言葉をかけてくれるぐらいだ。それより、メンバーの健康と休息を優先する。システム障害時における、リーダーの最大の役割は、メンバーをどうやって休ませるかだ。
3. 「War Room」をつくり、情報を集約・可視化する
「旗振りと体制」と「メンバーの休息」、この2つを押さえておくことで、障害対応を回しやすくなる。
そして、どこを中心に回すかというと、War Roomになる。War Roomは、作戦会議室だと思えばいい。物理であれウェブであれ、ハイブリッドであれ、そこに行けば最新情報と状況が分かる会議室だ。
物理的な会議室で説明する。そこに入ると、大きなホワイトボードが2種類ある(本書では、「フロー型」と「ストック型」と呼んでいる)。
一つは時系列に並んでいる一覧表だ。このホワイトボードは、フロー型になる。刻々と入ってくる、発生事象や影響調査、解析状況などが書き加えられていく。「いつ」「どこで」「何が」だけでなく、「どこの情報か」も合わせて書く(他システムに影響している場合、その連絡先も漏らさずに)。
ここに書かれたものがそのまま記録となるため、消さない。一杯になったら別のボードを用意して、そこへ続きを書く。
もう一つは、まとめの表だ。このホワイトボードは、ストック型になる。起きている事象とその影響、解析の状況と直接原因(事実か仮説かも含め)、復旧対処の準備と状況を書く。復旧のリミットがあるのか、復旧作業に伴う業務影響も書いておく。
ここに書かれたものが、現在の最新状況となる。明確になっていないのであれば、その旨を書く(〇〇が調査中、16時に状況報告予定というように)。途中参加したメンバーや、交代メンバーは、このボードを見て追いつくことになる。更新する際は、右上に日時を書いて画像を残しておく。

ホワイトボードの傍には、システムの全体像の絵や、連絡体制図、当番表も揃えておくといい。「いまどこを解析しているのか」や「次の6時間は誰が受け持つのか」といったとき、すぐに指さして話せるように可視化しておくのだ。
情報を必要としている人に、非同期に届けるためには、「この情報がいつ更新されるか」も添えておく。具体的には、「このボードは次回は20時に更新予定」と書いておく。あるいは、オンライン通話をつなげっぱなしにしているなら、「15分おきに状況を定時報告する」といったルールを決めておく。
ホワイトボードは、情報共有だけでなく、チームの盾となる。
まず、顧客やマスコミ対応に迫られ「どうなってるんだ!」と怒鳴り込んでくる人には、ストック型のボードを見せる。「どれくらいのインパクトなのか」や「いつまでに解決するか?それがいつ分かりそうか」について、目安を示せる。
もしボードが無いと、これらの質問は全て旗振りに集中する。ただでさえ指示に手一杯なのに、説明役もやらされることになる。War Roomにやってきている時点でそれなりに感情的になっているため、その矛先をかわす必要もある。それがボードになる。
また、「1時間でなんとかしろ!」とか無茶を言ってくる人も出てくる。疲弊しきったメンバーを前に怒りをあらわに懲罰をちらつかせる人もいる。そんなときは、フロー型のボードに言われたことをそのまま記載する。
人というのは面白い生き物で、酷い言葉を吐いても、それがどれほど酷いことを言っているのか、「見る」まで分からない。だから、そのままの言葉が書かれているボードを見て、初めて気づく。そこで、言われたことを実行するかどうかは別として、ひとまず記録する。
この記録は、後に責任問題でモメるとき、誰が感情的で、誰がフェアに対応したかを判断する材料となる。ウェブ会議室の場合なら、「全て」レコーディングしておく。こうしたエビデンスが、後に旗振りやメンバーを守る盾となる。
さらに、ホワイトボードを使うことで経営層と現場の対決姿勢を和らげることができる。「なんとかしろ!」と言ってくる人(経営層)の理屈からすると、自責であれ他責であれ、厄介ごとを抱え込んだ相手の向こう側に問題があるように見える。つまりこうだ。
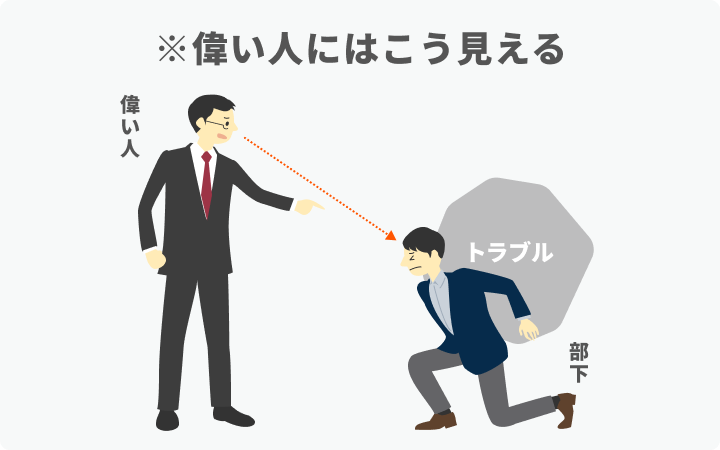
どんなトラブルなのか、いつ解消されるのか、聞かないと分からない。根掘り葉掘り聞きたくなるだろう。部下が「まだ分かりません」と返すなら、「いつ分かるのかを教えろ」と詰問調になる。
一方で、部下からすると、「なんで私が……」となるだろう。こっちは一生懸命にやっているのに、まるで問題そのものであるかのように詰めてくる。攻撃的な口調に、自然と対抗的な態度になってくる。
そこで、ホワイトボードを「人から問題を切り離す装置」として使うのだ。問題は、あなたや私が抱えているのではなく、ホワイトボード上、つまり私たちの間にあるのだ、という形だ。
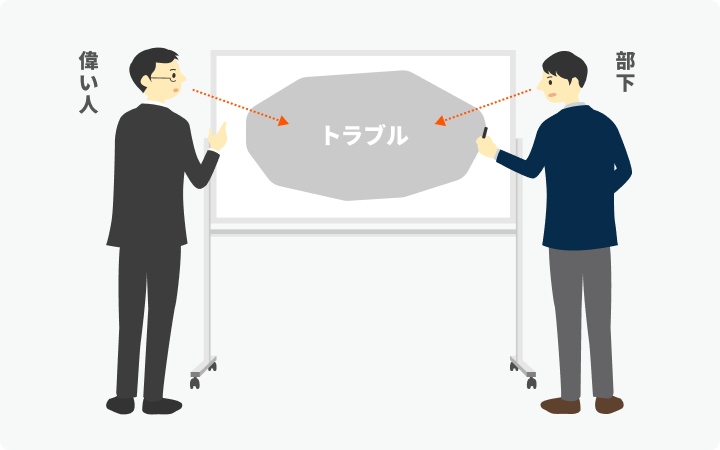
4. 陥りがちな罠を見極め、二次被害を避ける
システム障害の解析や復旧にあたって、二次被害はよく起きる。被害が露見していないだけで、普通に起きるものだと思ったほうがいい。
なぜなら、普段とは違うことをしているからだ。
緊急性&重要性が高いのに、リソースが足りない、時間が足りない、状況が不明で手探りの状態で、普段ならしない作業を、慣れていないかもしれない人が行う。いつもなら複数でやっているリスクのある作業を、リソースの関係上ひとりでやらざるを得ない。緊張続きで疲労困憊している状況で、ミスるなという方が無茶だろう。
だからこそ、ミスにつながる罠は極力潰しておく。本書では、様々な落とし穴が紹介されている。ベテランほど身に覚えがあるものばかりだろう。
- ・手順書のサーバ名が間違っていた(IPアドレスとホスト名が食い違っていた)ため、無関係のサーバをシャットダウンした
- ・ファイルを削除しようとしたが、削除対象の確認が漏れていたため、システム領域を丸ごと消した
- ・再実行してはいけないバッチ処理を動かしたため、結果データの件数が倍になり、容量を圧迫してしまった
- ・自システムのプロセスの再立ち上げで「問題なし」としてしまったが、相手先システムでの連携確認が漏れていたことが翌日に分かった
危ない作業は複数人でやるといったことで潰せるが、それができれば苦労はしない。できない状況下でやらねばならないのが障害対応だ。
それでも、せめて手順書だけは複数人でチェックするとか、リモートで画面共有しながら実施するといった対策がある。こればっかりは経験がモノを言う世界だが、漏れがどんな箇所で生じやすいかは、本書で予習しておくと、気づきやすい目が得られるかもしれぬ。
5. 責任転嫁のための「犯人探し」をやめさせる
トラブル対処の真っ只中で、終息した後の振り返り(ポストモーテム)の中で、必ず出てくる「犯人探し」。
これは、組織が大きくなればなるほど、役職が上になるほど湧いてくる。「誰のミス?」「私は言ったよね!」「責任を取らせるべきだ」というセリフを吐いてくる。
こういう人たちは、実は可哀想なヤツらだと思えばいい。どういう状況か分からず、どんな被害なのか見えず、どうすればよいか判断がつかない……そんな不確実性の下、恐怖に圧し潰されそうになって泣きわめく代わりに、誰かを探して、そいつに責任転嫁をしようとしているに過ぎぬ。
不安を転嫁し、不確実性を単純化できる、簡単な方法に囚われているのだ(経営層に近いほど、責任が重くなるから、その圧に負けてしまうのかもしれないが、それならその椅子に座っちゃいけないだろう)。
偉い人が不安に怯えるのは気の毒だが、犯人探しは現場レベルで悪影響を及ぼす。
報告が遅れ、情報が上がらなくなり、隠蔽が起きる。結果、解明が遅れたり、根本解決に至らない小手先の対処になる。一時的に小康状態となるが、後日、さらに大きな事故になるかもしれぬ。
では、この「犯人探し」を封じ込めるために、どうすればよいか?
それは、原因を調査するときの主語を「人」でなくすることだ。誰がしたのかではなく、どんなプロセスの下で行ったかに焦点を当てる。偉い人が「人」を探そうとしたら、それをプロセスに言い直すことも有効だ。主語を「人」から「プロセス」に強制的に変えることで、犯人探しに至る道を塞ぐことができる。
例えば、「この設定を変えたのは誰?」と訊くのではなく、「いつ、この変更をした?それはどの手順に則って?」と聞く。すると、設定変更した理由が見えてくるだろうし、その背景として何かしらの要請があったことが分かるだろう。さらに、その要請がどう吟味され、設定変更にOKを出したプロセスが明らかになるだろう。
結果として、そのプロセスに欠陥があり、本来チェックするべきものが漏れていたのかもしれない。あくまで、問題があるのはプロセスだということを強調しておきたい。ミスした「人」が問題なのではなく、ミスを見つけられなかった、あるいはミスを防御できなかった「プロセス」に、問題があるのだ。
でも、「責任逃れするな!」と感情的になった人にはどうする?たいてい、組織上の「責任者」が怒り出し、現場のエンジニアは萎縮する。こんな状況はどうすればよいか?
感情的になっている人から現場を全力で守ることを優先する。その人を諫めるか、理を説くしかない。そうはいっても相手は感情的になっているので、耳を貸さないかもしれぬ。
私がやる手は、オフィスに置いてあるぬいぐるみ(デュークくん)を取り上げて、「いまそれをやっても仕方がないです!あとでやりましょう。責任が誰にあるか、いま、どうしても気になるなら、彼に責任を負ってもらいましょう!!」と叫んで、ぬいぐるみを殴りつける。
このとき、ありったけの憎しみを込めて、その人よりも怒り狂うのがポイントだ。すると、その勢いに気圧されて引っ込んでもらうことが何度かあった。
おそらく、「狂ったようにぬいぐるみを殴り続ける私」を客観視して、怒っても意味がないことに気づいたのかもしれない。あるいは、「こいつヤベぇ」とドン引かれたのかもしれない。いずれにせよ、怒りにはより強い怒りを、相手にぶつけるのではなく、別の何か(ぬいぐるみとかホワイトボード)にぶつける。問題は、「誰か」ではなく「何か」にあるのだから。
もう10年以上もオフィスにいるデュークくんは、ボロボロになってる(ごめんな)。

おわりに
システム障害における現場のマネジメントの勘所としては、旗振りを決め、体制を構築し、兵站に目配りしながら、War Roomをつくる。二次被害に注意しながら解析・復旧を進め、犯人探しを厳に慎む。
さらに具体的・網羅的に知りたいのであれば、『システム障害対応の教科書』に当たってほしい。
この記事を読んでいる人は、おそらく「いま」システム障害が起きている人ではないだろう。だから、ここまで読む余裕があるといえる。
そして、そんな人には、いま、「連絡体制図」を更新しておくことを勧める。
連絡網みたいなものはあるかもしれない。けれどもそれ、アップデートされているだろうか?電話番号やメアドは書いてあるかもしれないが、メーリングリストが変わっていたり、SlackやTeamsのアカウント名が欠けていたりはしないだろうか。異動で窓口役の人が変わっている可能性だってある。
システム障害は、何が起きるか分からないし、どう対処すればいいか分からない。だけど、そのときに必ず役立つ体制図は、いまなら余裕で準備しておける。備えあれば“嬉しい”ことは、いま、やっておこう。
関連記事
![【スゴ本】小さなミスの「ごまかし」が致命傷になる前に読むべき5冊[レバテックLAB]](https://levtech.jp/media/wp-content/uploads/2025/10/251010_lab_341.jpg)
【スゴ本】重大インシデントは報告されなかったミスから始まる。致命傷を負う前に読むべき5冊

【「スゴ本」中の人が薦める】実際の炎上プロジェクトを通して学ぶ。ITエンジニアが修羅場をシミュレートできる3冊+α

【「スゴ本」中の人が薦める】ITエンジニアのメンタルを守る4冊+心配事を減らすとっておきの方法
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


