![]()
最新記事公開時にプッシュ通知します
![]()
【Go言語】死なないジョブワーカー処理~数万並行処理でも落ちない設計~
2025年12月15日


プログラミング言語の学習において、チュートリアルや書籍で基本文法を押さえたあと、「手を動かして何かを作る」というのはよくあるステップです。しかし、基礎を終えたばかりのエンジニアにとって「何をつくればその言語の特性を深く理解できるのか」は難しい問題ではないでしょうか。
TODOアプリやCRUDのような定番の題材もありますが、そこからもう一歩踏み込んだ実践的な開発となると、一筋縄ではいきません。言語ごとに特性や、現場で求められる実装パターンがそれぞれ異なるためです。
今回のテーマはGo言語です。ツールやマイクロサービス、Webサーバーなど多様な用途がある中、とりわけその強みが活かされるのが、ジョブワーカー(バックグラウンド処理)の実装でしょう。
大量のデータをさばくジョブワーカーはGo言語の得意分野の一つですが、並行処理の設計を誤るとデータ消失などの重大な事故に繋がるリスクもあります。
そこで本記事では、Go言語のスペシャリストmattn氏に「手を動かして学んでほしい題材」として「数万単位の並行処理でも落ちないジョブワーカーの設計」について解説していただきました。
ジョブワーカー処理とは
バックエンド処理において、ジョブワーカーは登録されたジョブ(タスク)を非同期に処理する役割を担います。 例えばユーザーがWebアプリケーションで更新した内容にしたがって、複数の手続きをバックグラウンドで実行する場合などに利用されます。
多くのユーザーから登録された情報を1つのワーカーが処理するのは非効率です。そのため複数のワーカーが積まれたジョブを分担して処理することで、システム全体のスループットが向上し、ユーザー体験も改善されます。
大規模かつ複雑なシステムでは、キューを用い、サーバーそのものを水平にスケールアウトすることが一般的ですが、処理の単位で並行化を図ることも重要です。
例えば、1つの情報登録に対して、画像のリサイズ、データベースの更新、ファイルの更新など直接関与しない複数の処理が必要な場合があります。画像のリサイズを行っているあいだに、データベースの更新処理、さらにはファイルの更新処理を同時に進めることができれば、全体の処理時間を短縮できます。これらの処理を個別にジョブとして並行に処理することで、全体の処理時間を短縮するのがジョブワーカー処理の目的です。
約10年前までは、スレッドプールを用いてジョブワーカーを実装することが多かったものの、Go言語の登場により、軽量な goroutine(ゴルーチン)を活用したジョブワーカーの実装が可能となりました。Go言語のgoroutineは、数千から数万の並行処理を効率的に扱えるため、かつてはシステムの大改修を要した大規模ジョブワーカーの導入も、現在は比較的容易に実装・安定運用できるようになりました。
Go言語における並行処理
以下のようなコードを考えてみましょう。5つのファイルを順番に更新する処理です。
import (
"fmt"
"time"
)
func updateFile(i int) {
fmt.Printf("Updating file %d\n", i)
time.Sleep(1 * time.Second) // シミュレーションのためのI/O待ち
}
func main() {
for i := 0; i < 5; i++ {
updateFile(i) // 各ファイルの更新処理
}
}
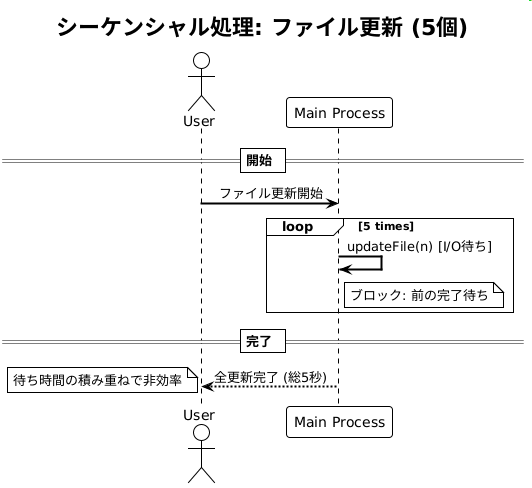
この処理は一見、シンプルに見えますが、実際には各ファイルの更新処理が完了するまで次の処理が開始されないため、全体の処理時間が長くなってしまいます。例えば、5つのファイルを更新する場合、各更新処理に1秒かかるとすると、合計で5秒かかります。
updateFile(0) updateFile(1) updateFile(2) updateFile(3) updateFile(4)
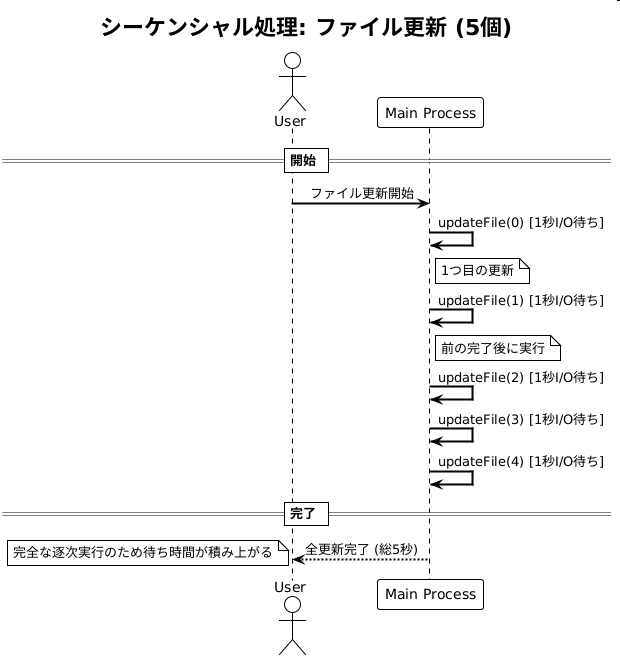
これをgoroutineを使って並行処理に変更すると、各ファイルの更新処理が同時に開始されるため、全体の処理時間を大幅に短縮できます。5つのファイルを同時に更新する場合、各更新処理に1秒かかるとしても、全体の処理時間は約1秒で済みます。
もちろん、goroutineを使う場合でも、各ファイルの更新処理が完了するまで待つ必要がありますが、全ての更新処理が同時に進行するため、全体の処理時間は大幅に短縮されます。
Go言語でgoroutineを使うには関数呼び出しの前にgoキーワードを付けます。
for i := 0; i < 5; i++ {
go updateFile(i) // 各ファイルの更新処理を goroutine で並行実行
}
ただしこの場合、メインの処理はgoroutineの終了を待っていません。メインの処理が先に終了してしまい、goroutineの処理が完了しないままプログラムが終了してしまう可能性があります。
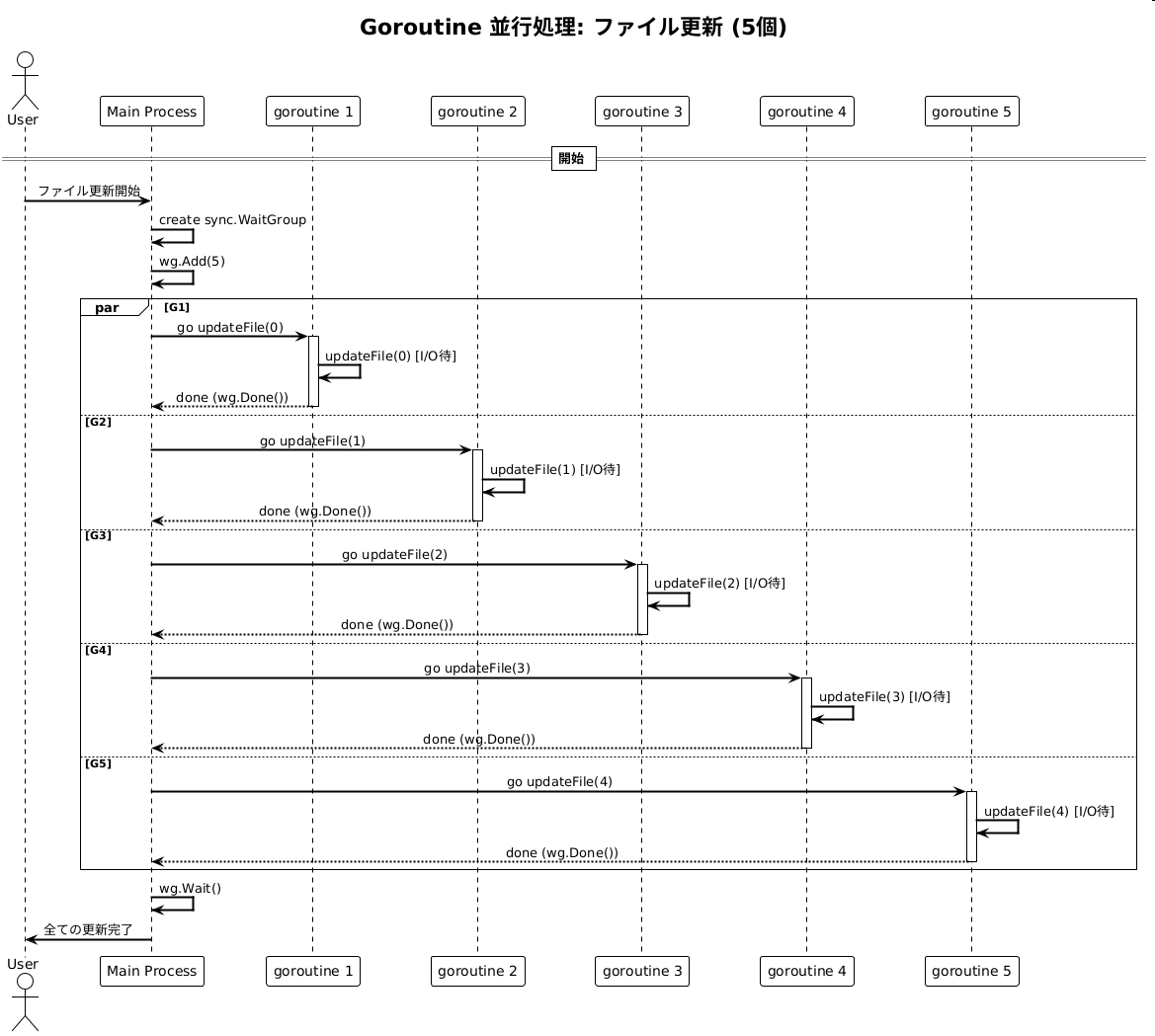
そこで利用するのがsync.WaitGroupです。sync.WaitGroupを使うことで、複数のgoroutineの完了を待つことができます。以下のコードは、5つのファイルを並行に更新し、全ての更新処理が完了するまで待つ例です。
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1) // WaitGroup に goroutine の数を追加
go func(i int) {
defer wg.Done() // goroutine の完了を通知
updateFile(i) // 各ファイルの更新処理
}(i)
}
wg.Wait() // 全ての goroutine の完了を待つ
実際には、updateFile関数内でwg.Done()を呼び出すようにすることもできます。
func updateFile(wg *sync.WaitGroup, i int) {
defer wg.Done() // goroutine の完了を通知
// ファイルの更新処理
}
メインの処理では以下のように呼び出します。
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1) // WaitGroup に goroutine の数を追加
go updateFile(&wg, i) // 各ファイルの更新処理
}
wg.Wait() // 全ての goroutine の完了を待つ
なお各goroutineの中で、変更が競合するような変数にアクセスする場合は、sync.Mutexなどを使って排他制御を行う必要があります。
var mu sync.Mutex ... mu.Lock() model.value = newValue mu.Unlock()
わずかな修正で大きく効率化することからも、goroutineがいかに手軽で強力な機能であるかがわかります。
通常、スレッドを使った並行処理では、スレッド数が増えるとシステムリソースを大量に消費し、パフォーマンスが低下しやすくなります。これは、CPUがスレッドの状態に関係なくタイムスライスを割り当てるためです。処理をしていないスレッドにもCPUリソースが割り当てられ、リソースの無駄遣いにつながります。例えばネットワーク通信やディスクI/O待ちでブロックされているスレッドにもCPUリソースが割り当てられるため、効率的なリソース利用ができません。
GoのランタイムはM:Nスケジューリングを採用しており、多数のgoroutineを少数のOSスレッドへ効率的に多重化することで、スレッド増加によるリソース消費を防ぎます。
goroutineは非常に軽量で、数千から数万規模で同時に動かしてもパフォーマンス低下が起きにくくなっています。
Goroutineを使ったワーカー処理の実装
goroutineを使うことで、簡単に並行処理が実装できることがわかりました。では、ジョブワーカーとして実際にgoroutineを使った並行処理を実現する場合、どのように実装すればいいのでしょうか。
ワーカーとは、決まった処理を繰り返し実行する役割を持つコンポーネントです。ジョブワーカーの場合、キューからジョブを取得し、各々のワーカーがそのジョブに対して処理を行います。Go言語でこれを実現するのがchannel(チャネル)です。
channelは、goroutine間でデータをやり取りするための仕組みです。ジョブワーカーでは、channelを使ってジョブをキューイングし、複数のgoroutineがそのchannelからジョブを取得して処理を行います。
type Job struct {
// ジョブの定義
}
type Result struct {
// 結果の定義
}
func processJob(job Job) Result {
// ジョブの処理
return Result{}
}
func worker(ch <-chan Job, results chan<- Result) {
for job := range ch {
result := processJob(job) // ジョブの処理
results <- result // 結果を返却
}
}
結果を受け取る場合
以下のworker関数は、channelからジョブを受け取り、そのジョブを処理し、結果を別のchannelに送信します。複数のworker goroutineを起動することで、並行にジョブを処理できます。このworker関数は、処理を開始する前にあらかじめ起動しておく必要があります。
ch := make(chan Job, 100)
results := make(chan Result, 100) // 結果用の channel
// 事前にワーカーを複数起動
for i := 0; i < numWorkers; i++ {
go worker(ch, results)
}
// ジョブを channel に送信
for _, job := range jobs {
ch <- job
}
close(ch) // ジョブの送信が完了したら channel を閉じる
// 結果の受信(注: 並行処理のため結果の順序は保証されません)
for i := 0; i < len(jobs); i++ {
result := <-results
fmt.Println(result) // 結果の処理
}
処理の中でchannelを閉じることで、ワーカーに対してジョブの送信が完了したことを通知できます。ワーカーはchannelが閉じられると、全てのバッファがなくなり次第、自動的にループを抜けて終了します。
シーケンシャルに処理を行うと待ち時間が積み重なるケースでは、この実装により並行化することで効率的にジョブを処理できます。
結果を受け取らない場合
goroutineが処理結果を呼び出し元に返す必要がないケースもあります。前述の例ではchannelを閉じることでgoroutineを終了させていましたが、例えばソケットサーバーのようにクライアントと対話しているあいだ、動作しつづけるワーカーの場合はchannelを閉じる必要はありません。
import (
"log"
"net"
)
func handleConnection(conn net.Conn) {
// 接続の処理
defer conn.Close()
// ...
}
listener, err := net.Listen("tcp", ":8080")
if err != nil {
log.Fatal(err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Println(err)
continue
}
go handleConnection(conn) // 各接続を goroutine で処理
}
その他には、キーボード入力を待ち受ける例もあります。キーの入力は常に監視が必要なので、細かいループの中でキーの入力状態を都度問い合わせるか、キーの入力を待つために処理をブロックする必要があります。goroutineを使用することで、メインの処理とは独立してキーの入力を待つことができます。
import (
"bufio"
"fmt"
"os"
)
func readKey(ch chan<- rune) {
r := bufio.NewReader(os.Stdin)
for {
c, err := r.ReadRune()
if err != nil {
return
}
ch <- c
}
}
// メインから呼び出し例
// ch := make(chan rune)
// go readKey(ch)
実はchannelにはバッファがあり、デフォルトではバッファサイズは0です。つまりchannelからデータを受信するまで、送信側はブロックされます。また逆にchannelにデータを受信するまで、受信側はブロックされます。
バッファサイズを指定することで、送信側が一定数のデータをバッファに格納できるようになります。
channelにバッファを設けることで、システム応答性を良くするために、channelにバッファサイズを指定することもあります。
ch := make(chan rune, 10) // バッファサイズ 10 の channel
この場合、channel のバッファが満杯になるまで、送信側のgoroutineはブロックされません。受信側がデータを受け取るまで、送信側は最大10個のデータをchannelに格納できます。
うまくバッファのサイズを調整することで、送信側や受信側のブロックが減り、システム全体の応答性が向上します。ただしバッファサイズを大きくしすぎると、メモリ使用量が増加する可能性があるため、適切なサイズを選択することが重要です。
キャンセル処理
goroutineを使った並行処理では、キャンセル処理も重要です。前述のように、goroutineを止めるために入力データを受け取るchannelを閉じる方法を紹介しましたが、入力データを扱わない場合、goroutineを停止させる別の手段が必要です。そこで利用するのがcontextパッケージです。
Go言語では、contextパッケージを使ってキャンセル処理を簡単に実装できます。
import (
"context"
)
func worker(ctx context.Context) {
for {
select {
case <-ctx.Done():
// コンテキストがキャンセルされた場合の処理
return
default:
// 通常の処理
}
}
}
この関数はctx.Done()チャネルを監視し、コンテキストがキャンセルされるまで、処理を繰り返します。もしこのworkerを停止させたい場合、以下のようにコンテキストをキャンセルします。
ctx, cancel := context.WithCancel(context.Background())
go worker(ctx)
err := doSomething()
if err != nil {
// エラーが発生した場合、コンテキストをキャンセル
cancel()
return
}
またcontext.WithTimeout関数を使うことで、簡単にタイムアウト処理を実装できます。
import (
"context"
"time"
)
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
go worker(ctx) // 5秒後に自動的にキャンセルされる
このように、Go言語には並行処理を安全に扱うための仕組みが必要十分に用意されています。これらを活用することで、堅牢なジョブワーカーシステムを構築できます。
バケツリレー方式
この方式は、異なる複数の処理ステージを連結し、各ステージが独立して動作するように設計されたパターンです。各ステージは前のステージからデータを受け取って処理を行い、次のステージにデータを渡します。これにより、システム全体のスループットが向上し、各ステージの負荷分散が可能になります。
func stage1(in <-chan Job, out chan<- Job) {
for job := range in {
// ステージ1の処理
out <- job
}
close(out)
}
func stage2(in <-chan Job, out chan<- Result) {
for job := range in {
// ステージ2の処理
result := processJob(job)
out <- result
}
close(out)
}
func main() {
jobs := make(chan Job, 100)
jobInOut := make(chan Job, 100)
results := make(chan Result, 100)
go stage1(jobs, jobInOut)
go stage2(jobInOut, results)
// ジョブの送信
for _, job := range jobList {
jobs <- job
}
close(jobs)
// 結果の受信
for result := range results {
fmt.Println(result)
}
}
例えばstage1では指定された複数のURLから素材をダウンロードし、stage2ではダウンロードした素材を加工して保存する、といった具合に処理を分割できます。通常、ファイルのI/Oやネットワーク通信を行うとき、CPUはアイドル状態になるため余裕が生まれます。そのあいだに他の処理を進めることで、システム全体の効率を高めることができるというのがgoroutineの強みです。
落ちないジョブワーカー設計のポイント
前述のように、24時間365日、止まることが許されないシステムにおいては、タイムアウトやエラーハンドリング、キャンセル処理などが非常に重要になります。そしてその実装をひとたび間違ってしまうと簡単にシステムが落ちてしまいます。
Go言語を使い、停止しないシステムを設計するためには、いくつかのポイントがあります。
・適切に処理を分割する
・並行処理のあいだをchannelで接続する
・要件に合わせchannelのバッファサイズを調整する
・contextを使ってキャンセル処理を正しく実装する
これらを適切に実装することで、数万並行処理でも落ちないジョブワーカーを設計できます。
実際に手を動かしてみよう
ジョブワーカーの設計ポイントを理解したところで、実際に手を動かして作ってみましょう。堅牢なジョブワーカーを作るには、単に動くだけでなく、異常系の動作も漏れなく確認する必要があります。
題材の提案: 画像ダウンロード・合成・アップロードシステム
ここでは以下のようなシステムを作ってみることをお勧めします。
複数の画像URLを受け取り、各画像をダウンロードし、ローカルのテンプレート画像と合成してから、S3や外部ストレージにアップロードする。
このシステムは、以下の3つのステージに分かれています。
・複数の画像URLをchannelで受け取る
・各URLから画像をダウンロードする (ステージ1: ネットワーク I/O)
・ダウンロードした画像とローカルのテンプレート画像を合成する(ステージ2: ディスクI/Oでの読み込み・書き込み)
・合成した画像をS3や外部ストレージにアップロードする(ステージ3: ネットワークI/O)
このシステムでは、前述のバケツリレー方式を使って、各ステージを独立したgoroutineで処理します。ダウンロード待ちのあいだに画像合成を進め、合成中にアップロードを進めることで、全体のスループットを向上させます。各ステージはI/O待ちが発生するため、goroutineで並行処理する意味があります。
type DownloadJob struct {
URL string
}
type SaveJob struct {
URL string
Image image.Image
}
type UploadJob struct {
URL string
Filename string
}
func downloadStage(ctx context.Context, in <-chan DownloadJob, out chan<- SaveJob) {
for job := range in {
select {
case <-ctx.Done():
return
default:
resp, err := http.Get(job.URL)
if err != nil {
log.Printf("Failed to download %s: %v", job.URL, err)
continue
}
defer resp.Body.Close()
img, _, err := image.Decode(resp.Body)
if err != nil {
log.Printf("Failed to decode %s: %v", job.URL, err)
continue
}
out <- SaveJob{URL: job.URL, Image: img}
}
}
close(out)
}
func saveStage(ctx context.Context, in <-chan SaveJob, out chan<- UploadJob) {
for job := range in {
select {
case <-ctx.Done():
return
default:
// テンプレート画像をディスクから読み込み (ディスク I/O)
templateFile, err := os.Open("template.png")
if err != nil {
log.Printf("Failed to open template: %v", err)
continue
}
defer templateFile.Close()
template, _, err := image.Decode(templateFile)
if err != nil {
log.Printf("Failed to decode template: %v", err)
continue
}
// ダウンロードした画像とテンプレートを合成
composed := composeImages(template, job.Image)
// 合成した画像をディスクに保存 (ディスク I/O)
filename := sanitizeFilename(job.URL) + ".png"
outFile, err := os.Create(filename)
if err != nil {
log.Printf("Failed to create %s: %v", filename, err)
continue
}
defer outFile.Close()
if err := png.Encode(outFile, composed); err != nil {
log.Printf("Failed to save %s: %v", filename, err)
continue
}
out <- UploadJob{URL: job.URL, Filename: filename}
}
}
close(out)
}
func uploadStage(ctx context.Context, in <-chan UploadJob) {
for job := range in {
select {
case <-ctx.Done():
return
default:
// S3 や外部ストレージにアップロード (ネットワーク I/O)
file, err := os.Open(job.Filename)
if err != nil {
log.Printf("Failed to open %s: %v", job.Filename, err)
continue
}
defer file.Close()
// 例: S3 にアップロード
if err := uploadToS3(job.Filename, file); err != nil {
log.Printf("Failed to upload %s: %v", job.Filename, err)
}
}
}
}
堅牢性を確認するためのテスト項目
1. 大量のジョブを投入する
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
downloadCh := make(chan DownloadJob, 1000)
saveCh := make(chan SaveJob, 1000)
uploadCh := make(chan UploadJob, 1000)
// 各ステージを起動
go downloadStage(ctx, downloadCh, saveCh)
go saveStage(ctx, saveCh, uploadCh)
go uploadStage(ctx, uploadCh)
// 10000個のジョブを投入
urls := generateURLs(10000)
for _, url := range urls {
downloadCh <- DownloadJob{URL: url}
}
close(downloadCh)
// 処理が完了するまで待つ
time.Sleep(5 * time.Minute)
}
大量のジョブを投入しても、メモリ使用量が急増せず、安定して処理が進むことを確認します。もしchannelのバッファサイズが適切でない場合、送信側がブロックされてデッドロックが発生する可能性があります。
S3に大量のファイルをアップロードするのが難しい場合には、minio等を使っても良いでしょう。
2. ネットワークエラーをシミュレートする
存在しないURLや、タイムアウトが発生しやすいURLを意図的に混ぜてみましょう。
urls := []string{
"https://example.com/image1.jpg",
"https://invalid-url-that-does-not-exist.com/image.jpg",
"https://httpstat.us/200?sleep=30000", // タイムアウトする URL
}
エラーが発生しても、他のジョブの処理が継続し、システム全体が停止しないことを確認します。
3. 途中でキャンセルする
処理の途中でcancel()を呼び出し、全てのgoroutineが適切に終了することを確認します。
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second) defer cancel() // 10秒後に自動的にキャンセルされる
context がキャンセルされたとき、各ステージのgoroutineが適切に終了し、リソースリークが発生しないことを確認します。
これらの実装から理解できること
goroutineが有効にはたらくのは、ネットワークI/OやディスクI/Oのような待ち時間が発生する処理に対してです。CPUバウンドな処理(例えば大量の画像処理や動画エンコード)に対しては、goroutineを増やしても効果が薄くなります。
どのような単位でgoroutineを分割するか、channelのバッファサイズをどの程度に設定するかは、実際に手を動かして試行錯誤することで理解が深まります。ジョブワーカーの設計はアプリケーションの特性に大きく依存するため、さまざまなパターンを試してみることをお勧めします。
関連記事

アウトプットのお題に選ぶ、奥深い自作「TODOアプリ」。mattn氏が教える、さらなる技術力の向上を目指すためのノウハウとは

気合いや根性では不可能。継続的アウトプットにつながるモチベーション管理術

【スゴ本】ITエンジニアの「武器」を増やす5冊
人気記事

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋

人間のコードレビュー力を鍛えるために。AIコーディング時代の「ペアプロ・モブプロの心得」

