![]()
最新記事公開時にプッシュ通知します
![]()
『「技術書」の読書術』IPUSIRON氏が教える、翻訳技術書の読み方
2025年5月30日
![[レバテックLAB]翻訳のクセを攻略する](https://levtech.jp/media/wp-content/uploads/2025/06/250528_LTlab_eyecatch_column.png)

IPUSIRON(イプシロン)
1979年福島県相馬市生まれ。相馬市在住。2001年に『ハッカーの教科書』(データハウス)を上梓。情報・物理的・人的の観点から総合的にセキュリティを研究しつつ、執筆を中心に活動中。主な著書に『ハッキング・ラボのつくりかた 完全版』『暗号技術のすべて』(翔泳社)、『ホワイトハッカーの教科書』(C&R研究所)などがある。
近年は執筆の幅を広げ、同人誌として『シーザー暗号の解読法』などを刊行。共著には『「技術書」の読書術』(翔泳社)、『Wizard Bible事件から考えるサイバーセキュリティ』(PEAKS)がある。また、翻訳に『Pythonでいかにして暗号を破るか 古典暗号解読プログラムを自作する本』(ソシム)と『暗号解読 実践ガイド』(マイナビ出版)、監訳に『安全な暗号をどう実装するか』(マイナビ)がある。現在は執筆活動の他、さまざまな分野で活動中。一般社団法人サイバーリスクディフェンダー理事。
X:@ipusiron
Blog:「Security Akademeia」
- はじめに
- 翻訳書特有の読みにくさを分解
- 読む労力を減らすテクニック
- 1. 「まったくわからない」は2割まで
- 2. 概要をつかむ
- 3. 読み込む部分を絞る
- 翻訳文特有のクセを克服する
- 1. 長くて読みにくい文の区切り方
- 2. 主語や述語を補完する
- 3. 言語間でギャップのある用語を押さえる
- 4. 人名に違和感があれば原語を確認する
- 5. 本質以外の部分は読み飛ばす
- 日本は翻訳大国
- まとめ
はじめに
はじめまして、IPUSIRON(@ipusiron)と申します。
現在はIT技術書の執筆を本業としています。20年以上にわたり、主にセキュリティ分野の書籍を執筆してきました。近年では、翻訳や監訳を手がけることもあります。2022年には、『「技術書」の読書術』という、読書法に関する書籍を執筆するまでに至り、「選び方」「読み方」「情報発信&共有」の観点で、筆者独自の読書法を紹介しています。

このたび、「難解な翻訳書を読みこなす方法」というテーマで記事を寄稿する機会をいただきました。ここでいう翻訳技術書とは、翻訳されたIT技術書を指しています。
翻訳書が読みにくいと感じるのは自然なことであり、そういうものだと割り切って読むしかありません。私自身、翻訳技術書の読みにくさはたびたび感じています。
本記事では、読者であり翻訳者でもある視点から、私自身が実践している翻訳技術書の読書法をピックアップして紹介します。いずれも基本的なテクニックであり、すぐに実践できるので、実際の読書にご活用ください。
ネットで情報収集する際には、英語サイトを参照せざるを得ないことが多々あります。また、研究レベルであれば、英語の論文を読むのが必須です。ただ、一般的なエンジニアは、翻訳技術書や日本語のIT技術書で十分にスキルアップが可能だと考えています。というのも、評価の高い洋書の多くは翻訳されており、翻訳のタイムラグも近年では縮小傾向にあるためです。多忙な一般のITエンジニアにとっては、1冊の洋書をじっくり読むより、複数の翻訳書を効率よく読むほうが情報収集の点で有利です。なお、原書の読書においては、DeepL翻訳やChatGPTが役立ちます。英文の翻訳だけでなく、内容を整理したり疑問点を解消したりできます。
スキルアップや情報収集を目的ではなく、楽しみとして読むなら、洋書(ここでは英語のIT技術書)もおすすめです。趣味の範囲内であれば完璧に理解する必要はなく、「楽しむついでに知識を得られればよい」という気楽な姿勢で読むことができます。趣味で洋書を読む場合、読みやすさや興味を重視すべきです。自分の得意分野や関心領域、図やイラストが豊富なもの、好きな著者(文章が読みやすく、他の著書も気に入っている)などを基準に選ぶとよいでしょう。
翻訳書特有の読みにくさを分解
翻訳技術書を読んでいるときに、違和感を覚えたり、筆者の主張がつかみにくかったりする要因はさまざまであり、原因ごとに適切な対処法も異なります。
以下に、違和感を引き起こす代表的な4つの原因をまとめます。
| 問題点 | 原因 | |
|---|---|---|
| ① | 読者 | 読者の前提知識が不足している、あるいは内容が読者のレベルに対して高度すぎる |
| ② | 訳 | 直訳・誤訳、翻訳者の誤訳・解釈ミス・勘違いなど |
| ③ | 原書 | 原文自体に誤りがある、原著者の勘違い、そもそも原書が読みにくいなど |
| ④ | 日本語 | 翻訳そのものではなく、訳文の日本語表現が不自然。誤字・脱字・表記ミスなど |
①の「読者の理解度」については、すべての技術書に共通する問題であり、翻訳技術書に限った話ではありません。これは読解力の問題ではなく、単に読者の前提知識が足りていないことが原因であることが多いといえます。
②の問題については、完全に避けるのは困難といえます。日本語で書かれた技術書であっても、誤字や脱字は存在します。もちろん、それらのミスをなくすために何度もチェックは行われていますが、それでも完全には防ぎきれないのです。業界特有の事情もあります。例えば、“compromise”という単語には、「妥協する」や「傷つける」といった意味がありますが、セキュリティ分野では「危険にさらす」という意味で使われることがあります(※1)。
③については、本質的な対処法がほとんどないのが実情です。そういう意味で、②の問題よりも厄介だといえるでしょう。原書そのものの文章が読みにくいにもかかわらず、翻訳書が読みやすくなっていたとしたら、それはラッキーなことです。そのときは、翻訳者の技量に素直に感謝しましょう。
④の問題は、まれに発生します。これは、訳者の日本語力や、専門分野に対する理解不足によって引き起こされます。例えば、“encryption”は「暗号化」、“decryption”は「復号」と訳すのが正確です。しかし、「復号化」という不自然な日本語表現になっていることがあります(※2)。これは翻訳者が「~化」という語尾に引きずられ、「暗号化」の対義語は「復号化」であると勘違いしていることによりますが、日本語には「復号化」という語は本来存在しません。「暗号化する」という言い方はあっても、「復号化する」は自然ではないことからも、それがわかります。
※1 “compromised”は、「危殆(きたい)化」と訳されます。これは、安全だと思われていたものが、危険にさらされる状態になることを指します。
※2 この勘違いは、暗号に関する本や記事でしばしば見かけます。
翻訳技術書は厳選された“良書”が多く、ハズレが少ない傾向があります。その理由については、日本の出版社の立場で考えるとわかります。当然ながら、出版社は翻訳書を出版することで利益を出したいと考えています。そのためには、「どの本を翻訳するのか」を第一に考えます(※)。その際、翻訳対象本(原書)は、以下の基準で選ばれます。
①海外で売れている本や高評価な本…安全策。翻訳書も売れる可能性が高い。
②日本に類書やライバル本がない…売れるかどうかは未知数だが、出版する価値がある。
③編集者の直感で選ばれた本…日本市場で売れる可能性を感じる。
④原著者が有名か人気である…過去にヒット作を持つ著者なら売れる可能性が高い。
いずれの場合も、たくさんある出版物から厳選された本に該当します。特に①のケースであれば、原書が良書である可能性が高く、その翻訳書も良書になる可能性が高いといえます。この選定基準から漏れた洋書にも良書は存在しますが、翻訳されることはほぼありません。よって、原書を読まなければ、こうした本と出会えないのです。言い換えると、趣味で洋書を読むことで、そうした良書に出会える可能性があるということです。このことが、上のミニコラムで趣味で原書を読むことを勧めた理由の一つでもあります。
※ 翻訳対象本の選定には、「翻訳者を誰にするのか」「翻訳権を得られるか」「スケジュール的に可能か」「出版タイミングが適切か」なども考慮されます。
読む労力を減らすテクニック
初心者〜中級者のITエンジニアが、翻訳技術書を読み進める際に役立つテクニックを紹介します。
翻訳書にありがちな「翻訳特有の読みにくさ」や「読むだけで疲れて本質にたどり着けない」といった問題を克服するヒントになるはずです。なお、一部の内容については翻訳書に限らず、技術書全般に共通する読書テクニックも含まれています。そのため、技術書の読み方を見直すきっかけとしても役立つでしょう。
1. 「まったくわからない」は2割まで
本を選ぶ際は「2割程度がとても難しい」と感じるものを探してみましょう。このとき、「2:3:5 = まったくわからない:頑張ればわかる:すでに知っている」のようなバランスが取れている本を選ぶのがおすすめです(※)。
背伸びをしすぎて、理解できない部分が多すぎる本を選んでしまうと、まったく読み進められず、読了できずに挫折感だけが残ります。努力すれば理解できる本であっても、そうした努力を要する部分が多すぎると、読み終えるのに時間がかかってしまうからです。
一方、すでに知っている内容ばかりの本では、得られるものが少なく、費用対効果も下がってしまいます。「2:3:5」の構成であれば、飽きることも、挫折することもなく読み進められるはずです。成長にもつながりやすくなります。
※ ここでの数値は、読書の難易度バランスをイメージとして伝えるためのものであり、厳密な意味を持つものではありません。
2. 概要をつかむ
自明なことではありますが、本の内容を事前に知っていると、読書効率が上がり、理解も深まります。一般書なら要約動画が役立ちますが、IT技術書の要約動画は少ないのが現状です。そこで、以下の方法を活用すると効果的です。
- ・読者のXやブログでの感想
- ・読者レビュー
- ・著者や翻訳者の投稿(X、ブログ、サポートページ)
- ・イベントでの著者登壇動画やプレゼン資料
特にプレゼン資料には、出版の経緯、読みどころ、裏話などが公開されていることがあります。これは「概要を知る」という目的にとどまらず、読者の興味を引く内容でもあります。私自身も、Xやブログを積極的に活用して、書籍の内容を紹介しています。多数の出版物と関わってきましたので、相関図などをあわせて公開することもあります。
3. 読み込む部分を絞る
見出しに着目する
本を読むうえでもっとも役立つのが、目次(見出しの一覧)です。目次は本の構成に対応しており、ここを見るだけで、その本の全体像や難易度をある程度推測できます。例えば、以下の目次は翻訳書『Pythonでいかにして暗号を破るか 古典暗号解読プログラムを自作する本』(ソシム)のものです。

この本は、導入部、24章、付録で構成されていますが、内容を詳しく読まなくても、目次を見るだけでどの程度の範囲まで解説しているのか大まかに推測できます。これらの目次からトピックを読み取るために以下の章に着目してみました。
- 5章ではシーザー暗号
- 19章では頻度分析
- 20章ではヴィジュネル暗号の解読
- 24章では公開鍵暗号のプログラミング
こうして見るとシーザー暗号からヴィジュネル暗号まで、古典暗号に関して基本的な内容を一通り網羅していると察しがつきます。一方、第22章から第24章までで扱われている現代暗号については、おそらく駆け足で触れている程度だと推測できます。現代暗号は高度な内容になるため、たった3章で本格的に解説するのは難しいからです。
次に、目次で構成を把握したうえで、「まえがき」や「あとがき」に目を通して、著者が本書を通じて伝えたいメッセージや意図を理解します。その後は、頭から順に読み進めるのも、知りたいことが載っている章から読むのも、目的に応じて自由に選べばよいのです。
パラグラフから段落構造を把握する
翻訳技術書を速読する際に役立つテクニックの一つが、段落の先頭文を拾い読みする方法です。この方法が有効なのは、英語の技術書や学術書がパラグラフ・ライティングという手法で書かれているためです。翻訳書において、原書の構造が反映されていれば、この速読テクニックが有効に機能します(※)。
パラグラフ・ライティングとは、パラグラフを基本単位として、論理的かつ明確に文章を構成する記述法です。ここでいう「パラグラフ」は、直訳の「段落」とは意味合いがやや異なります。日本語の「段落」は、読みやすさのために区切られた文章のまとまりであるのに対して、英語における「パラグラフ」は論理の最小単位です。パラグラフ・ライティングの大原則は、「1つのパラグラフに1つのトピック(著者の主張)がある」という点にあります。これにより、読み手にとって論理構造が明確になり、理解しやすくなるのです。
1つのパラグラフは「主張→補足・具体例」という構造を基本としています。冒頭には、筆者の主張を述べる文が配置されており、これをトピック・センテンスと呼びます。それに続く文はサブ・センテンスと呼ばれ、主張を補足・説明する内容で構成されており、具体例などが含まれることもあります。ただし、場合によってはパラグラフの最後に主張や結論が置かれることもあります。また、文章全体の最初のパラグラフでは、トピック・センテンスの前に読み手の関心を引く導入文(フックとなる文)が入ることもあります。
実際に具体例を見てみましょう。『Pythonでいかにして暗号を破るか 古典暗号解読プログラムを自作する本』から引用した文章を、先述の構造と照らし合わせ色分けしてみました。

原書がパラグラフ・ライティングで構成された文章は、翻訳版でもパラグラフの連続として展開されていくため、この構造を理解していれば、各パラグラフの冒頭文(=トピック・センテンス)だけを拾い読みすることで、文章全体の意味を把握することが可能になります。つまり、拾い読みであっても、筆者の主張や論理展開をすばやくつかめるのです。先に紹介した「見出しに注目する読書法」と組み合わせることで、さらに効率よく読み進められます。
※ この手法を使うには、原書が「パラグラフ・ライティング」を採用していること、かつ翻訳においてパラグラフの構造がそのまま反映されていることが前提となります。
接続詞から論理構造を把握する
接続詞は、文と文の間にある論理関係を示す手がかりになります。言い換えれば、接続詞をうまく活用することで、その文が飛ばしてもよいものかどうかを判断できるようになります(※)。この読み方は、翻訳技術書においても非常に有効です。
以下に、代表的な接続詞とその論理的な分類、および読書にどう活かせるかを一覧にまとめます。
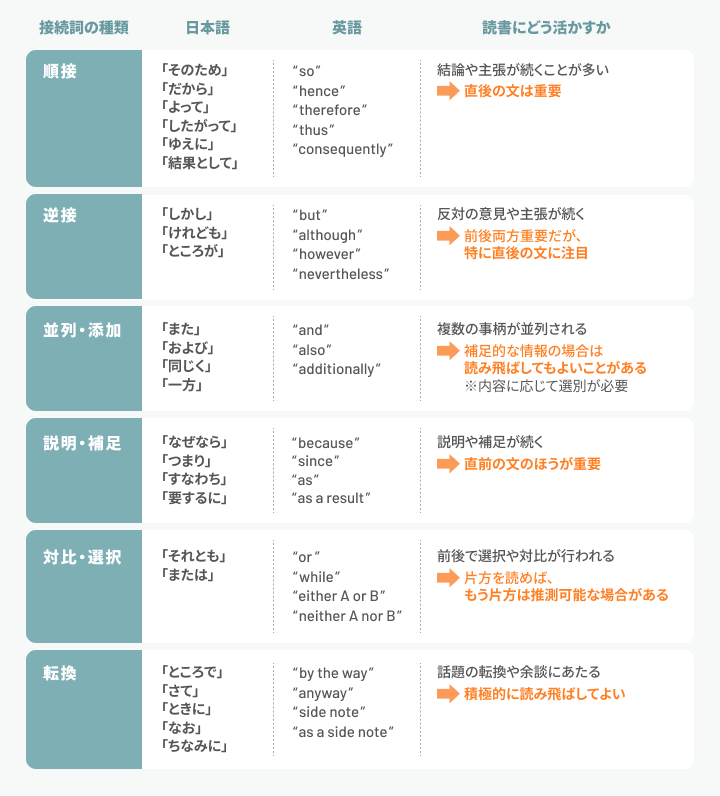
その他にも、英語では“for example”(例えば)のように接続詞のような働きをする副詞も頻繁に用いられます。接続詞に注目して論理構造を把握することで、著者の主張や文の要点を素早く見つけることができ、結果的に速読にもつながります。
※ 接続詞の役割を理解しておくことで、読書だけでなく執筆の際にも役立ちます。私は、最初は数学の証明を通じて接続詞と論理構造の関係を学び、その後、執筆を重ねる中で少しずつ語彙を増やしてきました。『「技術書」の読書術』では、飛ばし読みのテクニックの一つとして「日本語の用法を取捨選択のヒントにする」(P.149)を紹介しています。
翻訳文特有のクセを克服する
1. 長くて読みにくい文の区切り方
翻訳技術書の中には、1文が長くて読みづらいものがあります。その理由は、主に以下の2点によるものです。
- ・英語ではカンマや接続詞を使って、1文を長くすることが一般的であること。
- ・翻訳者の翻訳スタイルによって、原文の構造がそのまま維持されている場合があること。
例えば、以下のような英文があったとします。
“Hundreds of experts and generations of hobbyist researchers have examined the manuscript in great detail, but all the main questions about it are still unanswered.”
この英文は“~, but ~”という構造をしており、これを翻訳する際に「~するが、~」と続けるか、「~します。しかし~」と文を分けるかは翻訳者次第です。
翻訳者によっては、原文の構造を尊重するあまり、非常に長い文をそのまま訳すスタイルを取ることがあります。そういった翻訳書を読む場合は、読者自身が接続詞に注目しながら文を区切って読む工夫が必要です。
私の場合は、紙やPDFの本であれば、文の切れ目に二重斜線「//」を書き込むことがあります。文の切れ目というのはだいたいこういう場所です。私が翻訳した『暗号解読実践ガイド』3章「単一換字式暗号の解読法」から一例を紹介します。
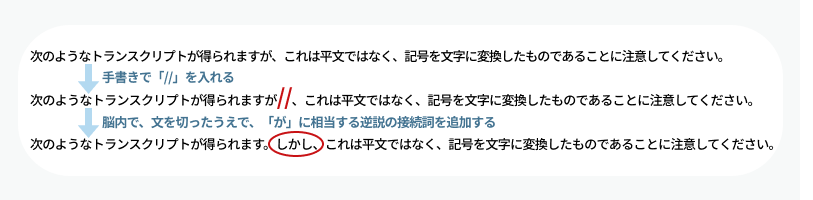
このように、自分なりの読解補助を取り入れて区切りながら読むことで、長文に対するストレスを大幅に軽減できます。
2. 主語や述語を補完する
英語では、“it” や “they” などの代名詞が頻繁に使われ、翻訳の過程で、これらの代名詞が「それ」や「これら」などと訳されることがあります。また、文脈から明らかな主語が省略されることもあるため、翻訳技術書では主語や述語があいまいな文が多くなりがちです(※1)。
この種の文章への対応策は、翻訳技術書(または訳文)を読む際に、助詞や語順を手がかりにして、隠れている主語・述語を補完する意識を持つことです(※2)。
例えば、以下のような英文があったとします。
“It encrypts the data and then deletes the original.”
この英文を「それはデータを暗号化し、その後元のデータを削除します」と訳したとします。一見自然な訳文ですが、この「それ」が何を指しているのかが明確でないため、読者は混乱してしまう可能性があります。たとえ暗号理論にある程度の知識があっても、「それ」がプログラムなのか、送信者なのか判断がつかないのです。場合によっては、主語が省略されて「データを暗号化し、その後元のデータを削除します」と訳されることもあります。
このようなときは前後の文脈を丁寧に読み、「それ」が何を指しているのかを推測してマークする(丸で囲んで線で結ぶ)か、書き留めておくとよいでしょう。
主語がない場合も、読み手はまず主語にあたる代名詞が隠れていると想定したうえで、助詞や文脈を手がかりにして主語を推測することになります。この読み方に慣れてくると、翻訳書の読解がぐっと楽になります。
※1 翻訳者は原文に忠実に訳しているため、これ自体が悪い訳というわけではありません。
※2 助詞とは、言葉と言葉の関係や文法的な役割を示す言葉です。例えば「は」「が」は主語、「を」「に」は目的語を明確にする手がかりになります。
3. 言語間でギャップのある用語を押さえる
英語と日本語の間には、意味や表記にギャップのある用語が多数存在します。翻訳技術書を読むうえで、これらのギャップにどう向き合うかが、読解のスムーズさに大きく影響します。
ギャップには主に、以下の3つのケースがあります。
- ①日本語に訳語がまだ存在しない。
- ②英語圏と日本語圏で呼び方・表記が異なる。
- ③訳語が冗長・不自然で、国際的には英語のまま使われるのが一般的。
①の「日本語に訳語がまだ存在しない(定着していない)」については、独自の訳語が当てられたり、英語表記のまま記載されたりすることがあります。例えば、暗号ブロック長が合わない場合の調整手法として知られる“Ciphertext Stealing”には、自然な日本語訳が存在しません。カタカナで「サイファーテキスト・スティーリング」と表記するのも不自然であるため、現在は“Ciphertext Stealing”のまま記述するか、略称である“CTS”を使うのが一般的です。
②の「英語圏と日本語圏で呼び方・表記が異なる」については、翻訳技術書において原文に忠実な表記が使われる一方で、日本語圏での呼び名が補足されることがあります。例えば、他人の画面を背後や横から覗き見るハッキング手法は、日本語で「ショルダー・ハッキング」(Shoulder Hacking)といいますが、英語では「ショルダー・サーフィン」(Shoulder Surfing)になります。しかも、英語では”Surfing”にもかかわらず、訳語のカタカナ表記では「サーフィング」ではなく「サーフィン」と、語尾が不揃いになっていることも混乱のもとといえます。また、「ホワイトハッカー」という言葉は日本で通用しますが、英語圏では「ホワイトハットハッカー」(Whitehat Hacker)や「エシカルハッカー」(Ethical Hacker)のように表現されます。
このように呼称が異なると、読者が意味を誤解する可能性があるため、補足情報や注釈に目を通す意識が重要です。
③で略語が混乱を招く場合、視覚的に整理するのがよいと思います。IT分野では、略語(アクロニム)が頻繁に登場します。その際、翻訳書では日本語訳に加えて、原語(英語)と略語が併記されることが一般的です。例えば、以下のような英文があったとします:
“Advanced Encryption Standard (AES) is a symmetric block cipher…”
これを翻訳すると、「高度暗号化標準(Advanced Encryption Standard:AES)は、対称ブロック暗号であり…」となります(※)。このように最初に定義された略語は、その後の文章では「AES」のみで登場するのが普通と思いたいところですが、実際には「Advanced Encryption Standard」と「AES」が混在して出てくる洋書も珍しくありません。例えば、“Advanced Encryption Standard”をその都度「高度暗号化標準」と訳し、”AES” はそのままにしてしまうと、「高度暗号化標準」と「AES」が混在してしまい、読者にとって非常に読みにくいということもあります。そうした場合は、読者側で工夫して読むしかありません。
私の場合、紙やPDFで読んでいるときは、略語に関して自分で手書きのメモを加えることがあります。特に読みづらいページでは、同じ用語をフリーハンドで丸や四角で囲み、線でつなぐなどして、訳語と略語の関係性を視覚的に整理します。こうすることで、訳語の読みにくさに惑わされず、用語の意味を抽象化して読み進められます。

以上のように、英語と日本語の間でギャップのある用語は、読みにくさに直結します。しかし、それは内容の難しさというより、表記上・言語上のノイズにすぎません。
したがって、ギャップを無理に埋めようとするのではなく、「そういう違いがあるもの」として受け入れて読み進めるほうが、読書の観点では建設的といえます。
※ この例では、「訳語(原語:略語)」の順で訳しています。これは英文の語順に従った形ですが、「訳語(略語:原語)」という書き方が間違いというわけではありません。翻訳スタイルや編集方針により異なります。
4. 人名に違和感があれば原語を確認する
翻訳書では、人名や固有名詞がカタカナ表記されるのが一般的です。
例えば、原文に “Alan Turing” と書かれていれば、翻訳では「アラン・チューリング」と表記されます。このように、よく知られた人物名であれば特に問題にはなりません。
問題になるのは、読みが難しい人名や、読者が初めて目にするような人名が登場した場合です。翻訳者が無理にカタカナ表記したことで、かえって違和感を覚えることがあります(※)
例えば、ElGamal暗号を知っている人であれば、暗号の名前としては英字で見慣れていると思います。そうした例で設計者の“Taher ElGamal”について書籍内で言及されるとき、「タヘル・エルガマル」と人名だけがカタカナで表記されていると、ElGamal暗号とのつながりにも気づきにくくなってしまいます。こうしたときは、カタカナで表記してある人名をネット検索すると、案外もともとの英語表記がすぐに出てくるものです。名前が “Taher ElGamal” であることがわかれば、そこから「ElGamal暗号の”ElGamal”だ」と連想できます。
以上のように、カタカナ表記に違和感があれば、「もしかして原文とズレがあるのかも?」と考えて原語を確認してみてください。
※ こうした混乱を避けるために、拙訳『暗号解読 実践ガイド』(マイナビ出版)では人名をカタカナ表記にせず、英語表記のまま記載する方針を取っています。
IT技術書には、図表やイラスト、サンプルコードやコマンド例、設定ファイルの一部、実行結果、エラーメッセージ、画面のスクリーンショットなどが数多く含まれます。こうした図表やコードが文章よりも直感的な理解を助けてくれることについて、実感している人は多いことでしょう。直感的な理解はもちろんのこと、構造の把握、概念モデルの形成(※1)に役立つことが複数の研究によって実証されています。例えば、「ファイアウォールはパケットのヘッダー情報を参照してアクセス制御を行う」という文章があったとします。文章でも意味は理解できますが、インターネットと社内ネットワークの間にファイアウォールが位置するイラストがあれば、すぐに理解できます。さらに、そのイラストを頭の中で再現できれば、文章を丸暗記する必要もありません。
また、初心者が新しい概念を学ぶ際に、完成された例(ここではサンプルや手順の実例など)を見るほうが、自力で問題を解くよりも効果的であることがわかっています(※2)。したがって、翻訳技術書においても、視覚的要素や実例に着目するのは、理解を深める有効な戦略といえます。もし本文がわかりにくいと感じたら、コード例や図表と照らし合わせてください。訳文のわかりやすさを補ってくれるはずです(※3)。
※1 概念モデルの形成とは、自分の頭の中で全体像や構造を整理し、イメージとして再構成することです。単なる暗記ではなく、「なぜそうなるのか」「どのように動作するのか」といった因果関係を理解し、再現できることが求められます。
※2 この効果は、教育心理学の世界でワード・エグザンプル効果(worked-example effect)と呼ばれています。
※3 私自身、翻訳作業中に「本文だけでは何を伝えようとしているのか分からない」と感じることがあります。そんなとき、図表に何度も助けられてきました。視覚的要素は言語の壁を超えます。図表から主張の意図が理解できても、翻訳の仕事では英文を飛ばすことはできませんが、通常の読書では本文(英文)を読み飛ばすことが有効です。
5. 本質以外の部分は読み飛ばす
内容の本質と無関係な部分は、初読時には積極的に読み飛ばして問題ありません。再読時にじっくり読めばよいのです。ここでは、読み飛ばしてもよい例を挙げます。
- ①章冒頭の引用文
- ②日本で馴染みのない用語、例え話、慣用句、ことわざ
- ③冗長な表現
- ④謝辞
①は、章の冒頭にある、文学書や思想書からの引用フレーズのことです。ありがちな例としては『孫子の兵法』の引用文があります。
日本人が著者であるIT技術書ではほとんど見かけませんが、英語のIT技術書ではたまに見かけます。つまり、翻訳技術書でもたまに見かけるということになります。何らかの意図が込められているのでしょうが、こうした引用文の意味は理解しなくても問題ないことが大半です。
②については、原書の文化圏で常識とされる用語や事柄、筆者の趣味などが、説明なしに登場するケースです。これらの補足がないと、日本の読者にとっては読みにくさを強く感じるはずです。例えば、海外のTV番組、海外の芸能人、海外ファンの多い作品(「スター・ウォーズ」など)、ことわざ・慣用句などが挙げられます。
ここでは、例を2つ紹介します。
1つ目は『暗号解読 実践ガイド』には、“Wheel of Fortune”という用語が登場します。原文では、読者は知っていて当然のように書かれていますが、ほとんどの日本人は何のことかわからないでしょう。“Wheel of Fortune”(「ホイール・オブ・フォーチュン」)はアメリカ合衆国のクイズ番組であり、訳注でその説明を加えました。翻訳者としてはそうするしかありませんでしたが、正直なところ、こうした例示は読み飛ばしても構いません。
2つ目は、プロダクト・マネジメントの分野に登場する「豚に口紅」モデルです。この「豚に口紅」という表現は、「豚に真珠」や「猫の小判」の英語版と誤解されやすいですが、意味は異なります。「豚に口紅」(英語では“lipstick on a pig”)は、表面的に飾っても本質は変わらないという意味のことわざです。「豚に口紅を塗ったところで、しょせん豚は豚」というわけです。海外の読者であれば、ことわざの意味からモデルの意図も直感的に理解できるのでしょう。しかし、日本人にとっては馴染みのない表現であり、詳しい説明がないと理解しづらくなります。誤って「豚に真珠」などの意味合いと混同してしまうかもしれません。したがって、いっそ飛ばした方がいいです
③については、小説なら別ですが、IT技術書であれば、本筋の理解に直接関係しない用語や冗長な表現は、読み飛ばしても問題ありません。
後ほどテクニックとして述べますが、長文に出会ったら、短く切るだけでも読みやすくなります。さらに読みやすくするために、冗長な表現をカットするのが有効です。最初のうちは、どの用語を飛ばすべきか悩むかもしれませんが、多読を続けるうちに自然と感覚が身につくはずです。「ルールを覚える」というより、慣れの中で判断力が養われます。
④の謝辞とは、著者が協力者に対して感謝の意を述べるセクションです。見慣れない人名が延々と続くうえに、内容として得られる情報はほとんどありません。したがって、謝辞についてはざっと目を通すか、思い切って読み飛ばして、本編に集中しても構いません。
翻訳書を読みにくくしている隠れた要因として、技術書の中でもページ数が比較的多いことが挙げられます。背景として、翻訳対象に選ばれる原書そのものが分厚いことに加え、翻訳書は原書よりもページ数が増える傾向があります。ページ数が増えることはあっても、大幅に減ることはほとんどありません。例えば、私が携わった『Pythonでいかにして暗号を破るか 古典暗号解読プログラムを自作する本』は原書が420ページであるのに対し、翻訳書は翻訳後に1.2倍のページ数(520ページ)になっています。
ページ数が多いことは、読みにくさの直接的な原因ではありません。とはいえ、通読に時間がかかる分、「読みにくい」という印象を持たれやすくなります。さらに、ページ数が多くなることで値段も高くなりがちです。そのため、読みにくさを感じさせてしまうと、評価が厳しくなりやすいという側面もあります。このことからも、翻訳書が多少読みにくい本でも、内容には十分な価値があると考えてよいと思います。
日本は翻訳大国
英語圏に生まれていれば、英語がネイティブとなり、最新の英語の本を原文のまま読むことができたでしょう。
では、読書という観点で、日本に生まれて不運だったのでしょうか?
いいえ、決してそうではありません。
世界には数多くの国がありますが、日本ほど翻訳書が身近な国は、実は多くありません。日本では、ほとんどの学問を日本語で学べます。最前線の研究レベルではない限り、日本語の情報で対応できるのです。実は、こうした環境は世界的に見ても珍しいといえます。こうした環境が成り立つ理由は、専門書の出版に力を入れている出版社や、翻訳に尽力している出版社の存在にあります。そのおかげで、専門的な内容であっても、日本語で読めるのです。
こうした背景があるからこそ、IT技術書においても、多くの翻訳書が存在しています。つまり、日本では翻訳書で学ぶことも、原書(洋書)で学ぶことも可能であり、学習の選択肢が広いという利点があります。このことから、読書環境に関して言えば、日本に生まれたことはそれなりに恵まれているといえるでしょう。
日本では新刊点数の増減はあっても、翻訳書の点数自体は比較的安定して推移しています。日本の新刊は年間7万点から8万点ほどありますが、そのうち6千点ほどが翻訳書といわれています。割合でいうと8%程度になります。ちなみに、翻訳の必要性が少ない英語圏のアメリカでは翻訳書がわずか3%程度と報告されています。
ところで、翻訳書の割合だけで考察するのは早計です。なぜなら、自国内の出版物が少ない国であれば、翻訳書の比率は相対的に高くなります。さらに、自国内の出版物の水準が高ければ、翻訳書の割合が高くなくても読書環境が優れているためです。ユネスコが提供する翻訳書籍の国際データベース「Index Translationum」によれば、日本は累計で約13万点を出版しており、これは世界第4位に相当します。上位3ヶ国は、ドイツ(約26万点)、スペイン(約23万点)、フランス(約20万点)となっています。
まとめ
以上、翻訳技術書をスムーズに読み進めるためのテクニックを紹介しました。これらを実践することで、翻訳技術書を効率よく通読できるようになります。ぜひ日々の読書に取り入れてみてください。それぞれのテクニックを意識し続けることで、やがて習慣となり、難しい翻訳本もストレスなく読みこなせるようになります。
そして、なによりも読書を楽しみながら、自分自身の成長を実感していきましょう。
関連記事

圧倒的な読書量を誇るからあげ氏が実践・読書との向き合い方

訳:吉羽龍太郎への信頼 ITエンジニアのキャリアを支える、知られざる技術書翻訳の世界

【渋川よしき】機械翻訳がある今でも「技術書翻訳をやってみたほうがよい」と思う理由
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


