![]()
最新記事公開時にプッシュ通知します
![]()
生成AIはなぜ簡単な計算問題を間違えるのか。トークナイザーから見るLLMの計算プロセス
2025年3月27日


GMOインターネットグループ デベロッパーエキスパート
杜 博見
2023年4月にGMOインターネットグループ株式会社に新卒入社。同社グループ研究開発本部AI研究開発室データ解析・AI研究グループ所属のデータサイエンティスト。グループ横断のプロジェクトで技術支援を担当する。
大規模言語モデル(LLM)を利用した生成AIが簡単な計算を間違える現象は、しばしば話題となってきた。その原因は、LLMが実際に“計算”をせずに過去の学習データから最も確率が高い答えを推測しているためだと言われており、現時点での解決策は数値計算をプログラミングとして書かせることだとされている。
2024年11月に開催されたテックカンファレンス「GMO Developers Day 2024」では、GMOインターネットグループのデータサイエンティスト杜博見(と・ひろみ)氏が、OpenAIの「GPT-4o」と「OpenAI o1 preview」、Anthropicの「Claude 3.5 Sonnet」、Googleの「Gemini 1.5 Pro」、Metaの「Llama 3 70b instruct」の5つのモデルに計算問題を解かせる実験を行った。結果をもとに、誤答を生み出すLLMの特性を考察した。
4種類の有名問題と各AIモデルの成績
今回の実験では、生成AIが間違えやすい単純な数値計算問題として知られている以下の4種類の問題を出した。
- 1. 小数点以下の数値の大小を比較する
- 2. strawberryの「r」を数える
- 3. 桁数の多い数字「100……000」の0を数える
- 4. 4桁以上のかけ算
問題(1)小数点以下の数値の大小を比較する
1つ目は、小数点以下の数値、すなわち0.11と0.9の大小を比べる問題。
9.11と9.9を比較する1問目、5.11と5.9を比較する2問目で両方正解したのはOpenAI o1 preview のみだった。


解答の理由を尋ねると、誤答したモデルからは「11は9より大きい」という説明が散見された。小数点以下の数値をうまく認識していないことがわかる。
問題(2)strawberryの「r」を数える
英単語「strawberry」に含まれるアルファベット「r」を数える問題では、Gemini 1.5 ProとOpenAI o1 previewの計2モデルが正解した。


理由を答えさせると、rを「2つ」と誤答したGPT-4o、Claude 3.5 Sonnet、Llama3 70b Instructは、共通して“berry”という部分のrを1つしかカウントしていないことがわかった。一方、Geminiは誤ったカウントの仕方でたまたま数値が一致しただけで、OpenAI o1 previewのみが正しい方法で回答を導いていた。
問題(3)桁数の多い数字「100……000」の0を数える
「100000000000000000000000000000000には0がいくつ並んでいますか?」という問題に対しては、全てのモデルが誤答した。中でも、OpenAI o1はそもそも数値全体を34桁だと誤認していた。

問題(4)4桁以上のかけ算
最後に、桁数の多いかけ算の問題を出すと、「1204×1402」に正答したのはClaude 3.5 SonnetとOpenAI o1 previewの計2モデルだった。


ただ、より複雑なかけ算「1.29433×0.642937」に正答できたモデルはなかった。

単語や数字のトークン分割に課題
以上の結果をふまえ、杜氏が実験したAIが計算問題に苦戦した背景を考察した。
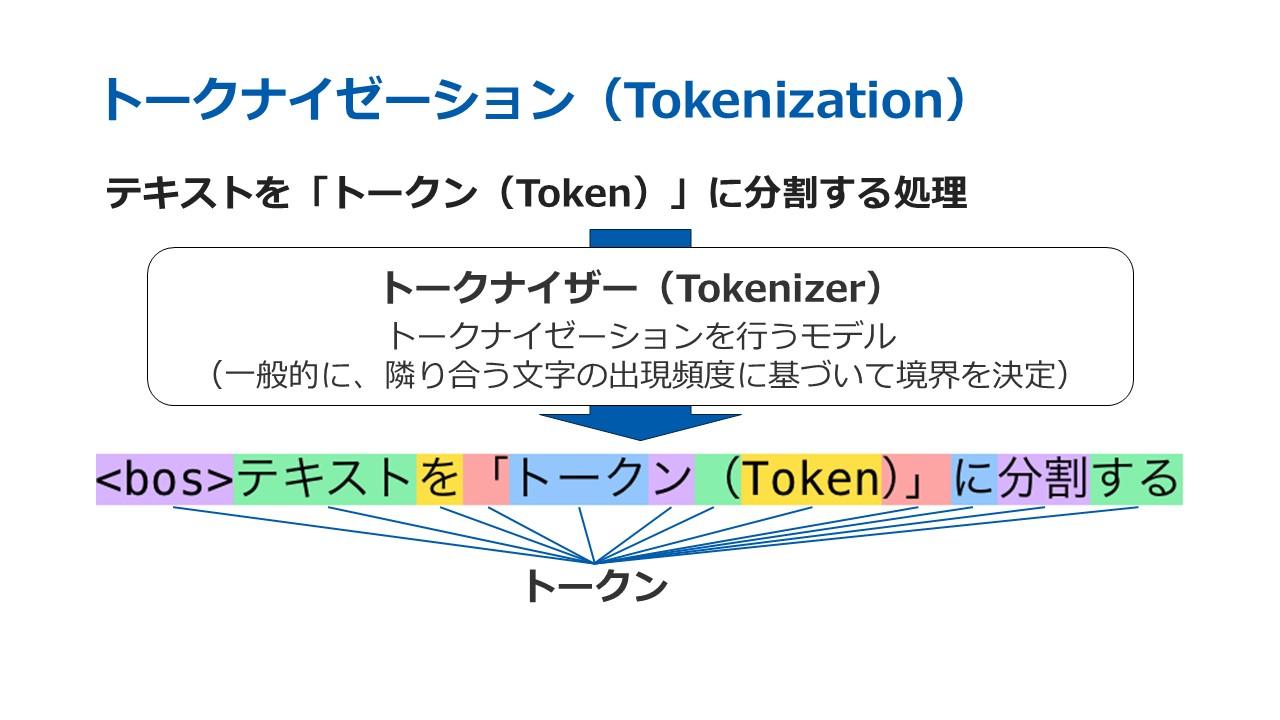
杜氏はまず、テキストをトークンという意味を持つ最小単位に分割する「トークナイゼーション」を挙げた。実際にこの処理を行うモデルは「トークナイザー」と呼ばれ、一般に文章内の隣り合う文字の出現頻度に基づきトークンの境界を決定する。
今回、Hugging Face上でCognitive Labが開発したツール「Tokenizer Arena」を使い、GPT-4o、Claude3、Gemma、Llama3 各モデルのトークナイザー(※)を比較した。
※Claude3.5とGeminiのトークンナイザーは非公開のため、非常に近いと思われる「Claude3」「Gemma」で代用

各モデルに問題(1)~(3)の質問文を入力し、トークン分割を可視化すると、5.11と5.9の大小比較では、Gemini(Gemmaで代用)のみが1桁の数字を1つのトークンとして認識した。一方、Gemini以外のモデルは、小数点以下の2桁の数値「11」や「90」を1つのトークンとして認識していた。

strawberryの「r」を数える問題では、実験で用いたモデルが回答した通り、全てのトークナイザーがstrawberryの“berry”の部分を分割せずに1つのトークンとして扱っていたことがわかる。例えば、GPT-4oの目線では、「st」「raw」「berry」という3つの異なるトークンの塊の中から、「r」という別の4つ目のトークンの数を数えるということになってしまい、事前知識がないLLMには判断が難しいだろう。

また、100000000000000000000000000000000の0を数える問題を見ると、GTP-4oとLlama3は最大3桁ごとに数値を区切ることも観察された。3桁以内だと1つのトークン、4桁以上だと2つ以上のトークンとして認識されるようだ。
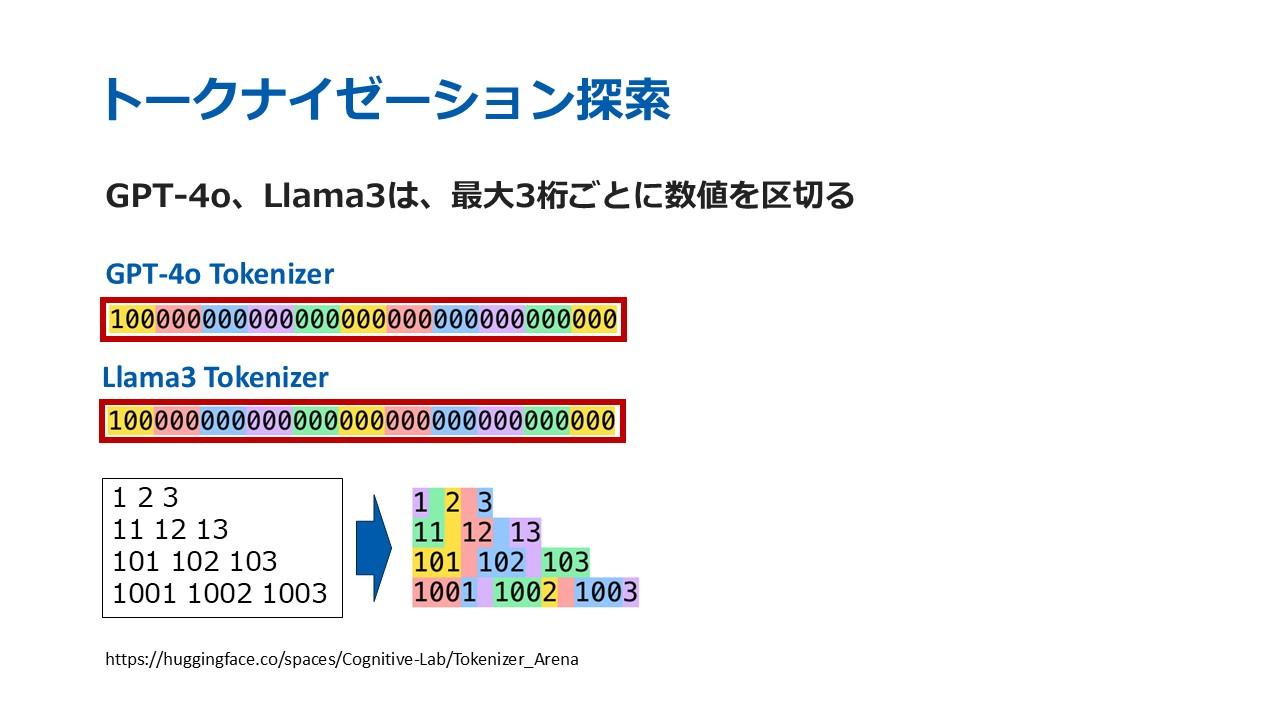
このように、「1」とその後に続く32個の「0」は、「100」というトークンと「000」というトークン11個の中でまた新しい単独の「0」のトークンの数を数えて…というように認識されていた。したがって、この問題も「1」「0」で区切るという前提条件がないLLMには解答が難しいといえる。
さらに、隣り合う文字の出現頻度に基づいてトークンの境界を決定するというトークナイザーの性質から、GTP-4oとLlama3がいずれも出現頻度の低い4桁以上の数値を1つのトークンと認識できなかったという仮説が考えられる。
「9.11」を同時多発テロ事件の日付と認識
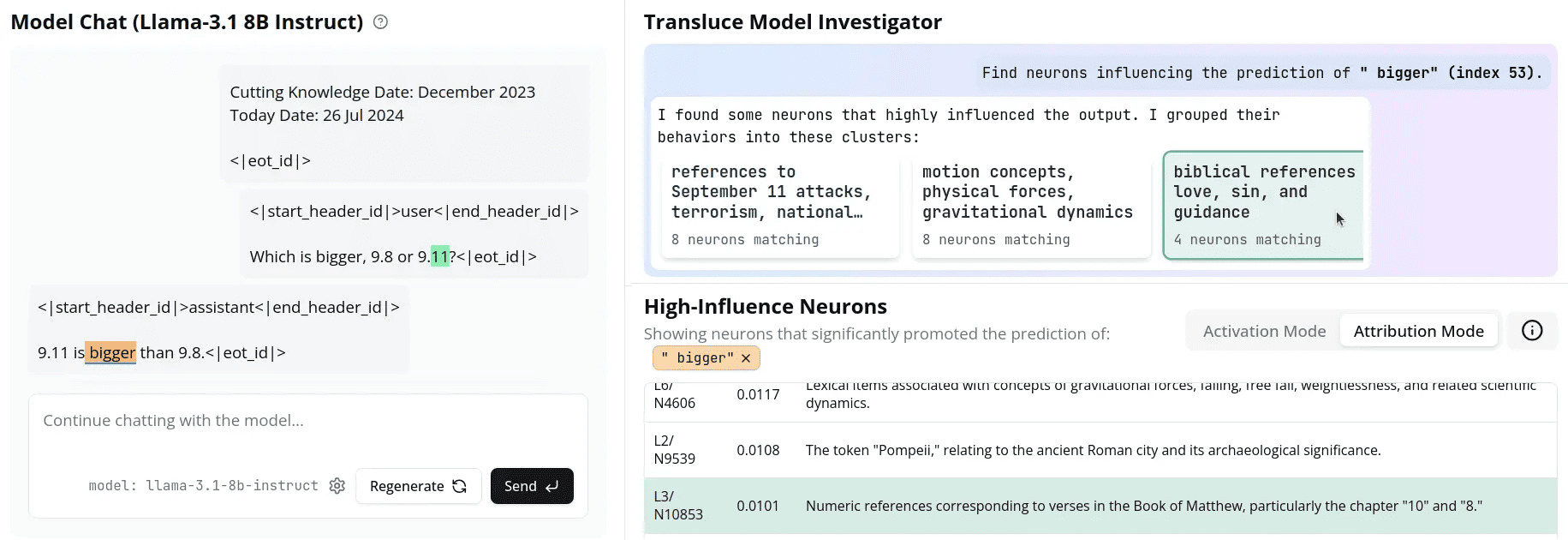
杜氏はこのほかの要因として、LLM内のニューロン活動が誤答に影響した可能性を示唆した。
Transluce社が提供する「Monitor」という監視ツールを使うと、LLM内のニューロン活動を監視し、特定の文書予測に影響を与えた潜在情報を可視化できる。Llama-3.1に9.8と9.11を比較させたデモンストレーションを見ると、「9.11が大きい」という誤答に影響したニューロンの情報として、同時多発テロ事件の「9月11日」という歴史的な日付や聖書のチャプター表記などが挙がった。つまり、同AIモデルは9.11を単純な数字として認識していなかったといえる。
“最も確率が高い答え”を出す
トークン分割やニューロン活動の可視化により、誤答が生まれる過程の一部が明らかになった。だが、それ以前に、LLMの性質そのものにも原因があるという。
杜氏はAIモデルが計算を誤る本質的な背景として、「LLMは数値計算をしているのではなく過去の学習データから最も確率が高い答えを当てようとしていると考えられる」とした。
実際に現代数学界の第一人者テレンス・タオ(Terence Tao)氏も同様の見解を示している。
They(AI models)’re not solving the problem from the first principles, they’re just guessing at each step of the output.(AIモデルは、最初に与えられた条件から問題を解いているのではなく、出力の各ステップを推測しているだけです。)
(「IMO2024:AIandMathematics」での発言より引用、訳は編集局による)
つまり、簡単な計算タスクであっても、学習データがなければ質問に正確に対応できないと考えられるという。具体的には、3桁以下のかけ算は学習データ上で頻出していることから別の数字でも再現できるが、4桁以上になると学習データで全てカバーしきれず、一部のモデルは似たような数式を参考に“それらしい誤った回答”を生成しうるということだ。
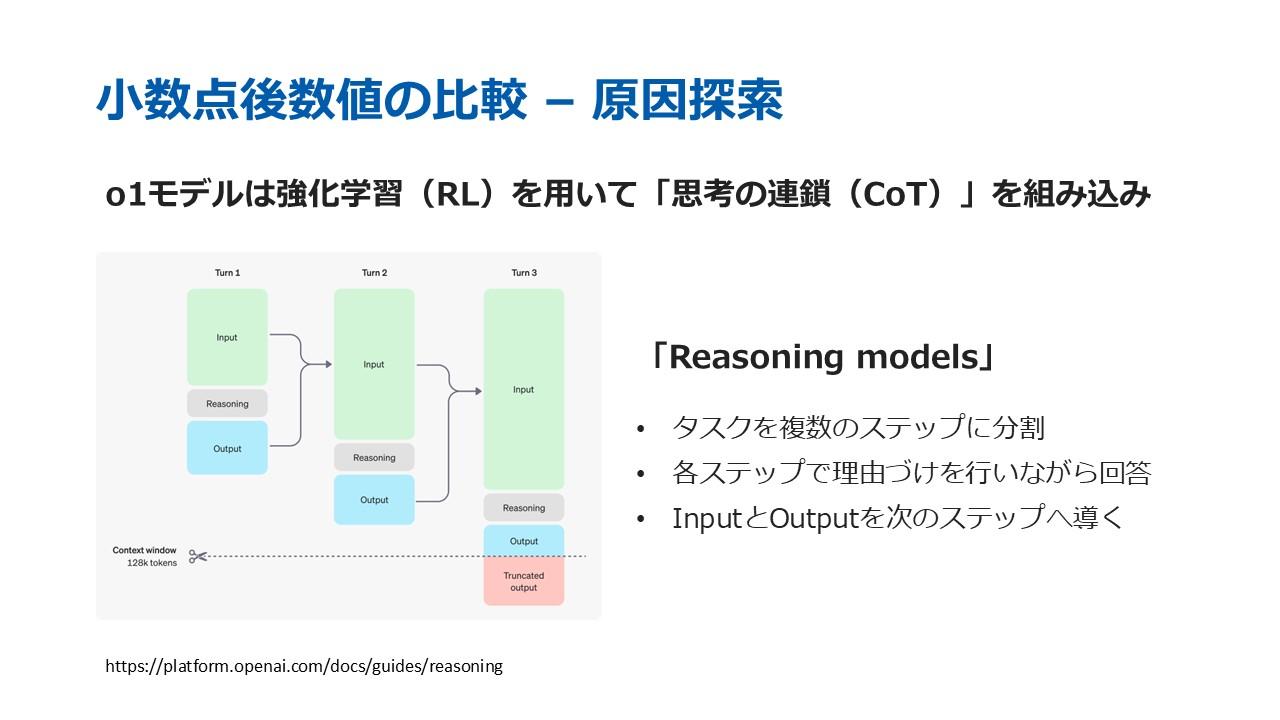
また、OpenAI o1 previewの計算精度が抜きんでた背景には、同モデルが強化学習(RL)を用いて思考の連鎖(Chain-of-Thought, CoT)を組み込んでいることが挙げられる。Open AIによる「Reasoning models」というフレームワークは、タスクを複数のステップに分割し、各ステップで理由付けを行いながら回答、出力した回答と入力内容を次のステップに用いることを繰り返すことで精度向上を目指している。杜氏は「o1が複雑な数式を簡単な数式に変換し、暗記したデータを活かすことで正確な解答を再現できたのではないか」と推測した。
今回の実験で、「LLMは数値計算が苦手だ」という言説を改めて確認できたという。杜氏は現時点での解決策として「電卓を使えばいい。あるいは生成AIモデルにプログラムを実行して回答してくださいというプロンプトを入力するだけでいい」と話す。確実に回答させるため、「プログラムを書いて」ではなく「実行して」と明確に書くことがポイントだという。
「生成AIは万能ではありません。現状の生成AIはあくまで確率に基づき、それらしい文章や画像を生成しているに過ぎません。その生成AIは何が得意で何が苦手なのかを理解して道具として適切に使いこなすことが重要です」
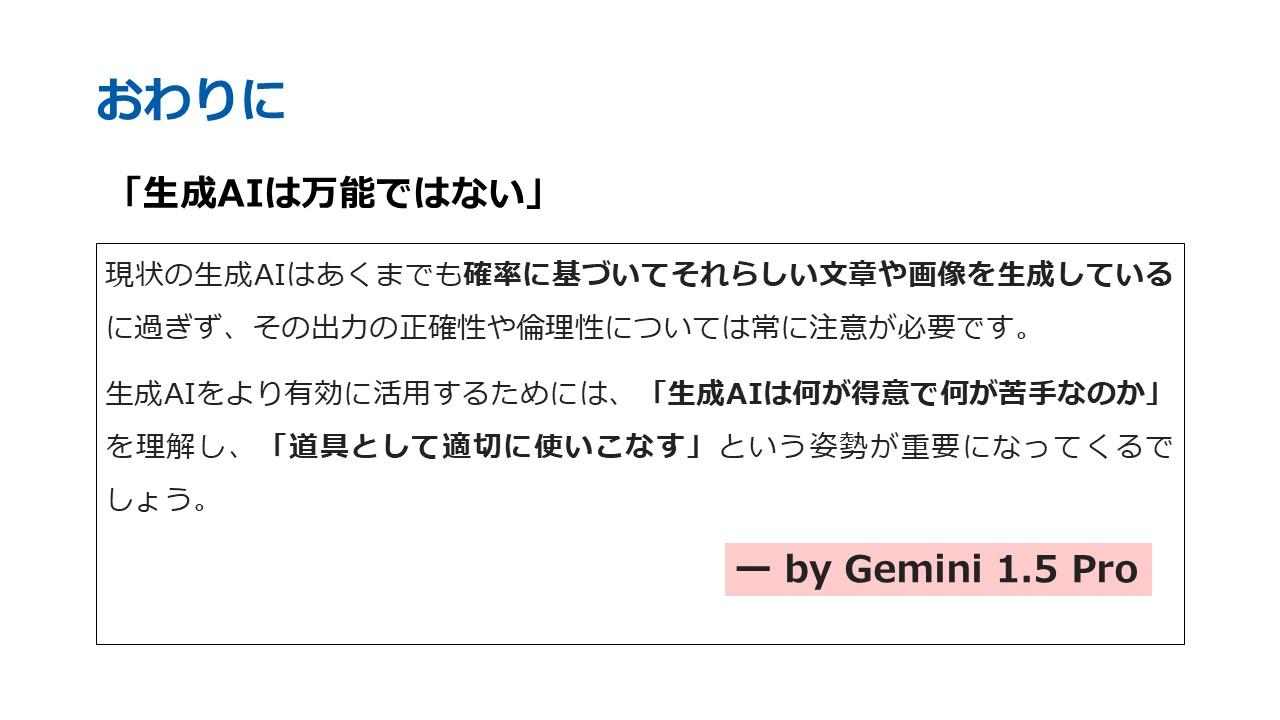
「一例として、こちらの文章はGemini 1.5 Proが生成したものです」
杜氏はこう語り、セッションを結んだ。
関連記事

初めてのAIプロダクトで「独自LLMで会話するAI VTuber」を開発。にゃおきゃっと氏に聞く「今10分触ってみる」が持つ力

生成AIは「意味」を理解しているのか?「ノリ」で喋れるLLMに、決定的に欠けているものとは

GPT-4にWebサイトを“自律的に”ハッキングさせる方法 AI自身が脆弱性を検出、成功率70%以上【研究紹介】
人気記事

テスト設計のAI活用 ~ 期待通りの出力を得るためのコンテキスト設計 ~

だって最高のホビーだから。プログラミング言語「HSP3」を30年開発している理由【フォーカス】

「国産ヒューマノイドは巻き返せる。だが、いまが最後のチャンス」。日本のロボット開発の厳しい現実と、起死回生の道筋


